 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace-based Set Operations on a Pre-trained Word Embedding Space
Oct 24, 2022Word embedding is a fundamental technology in natural language processing. It is often exploited for tasks using sets of words, although standard methods for representing word sets and set operations remain limited. If we can leverage the advantage of word embedding for such set operations, we can calculate sentence similarity and find words that effectively share a concept with a given word set in a straightforward way. In this study, we formulate representations of sets and set operations in a pre-trained word embedding space. Inspired by \textit{quantum logic}, we propose a novel formulation of set operations using subspaces in a pre-trained word embedding space. Based on our definitions, we propose two metrics based on the degree to which a word belongs to a set and the similarity between embedding two sets. Our experiments with Text Concept Set Retrieval and Semantic Textual Similarity tasks demonstrated the effectiveness of our proposed method.
Actor-identified Spatiotemporal Action Detection -- Detecting Who Is Doing What in Videos
Aug 27, 2022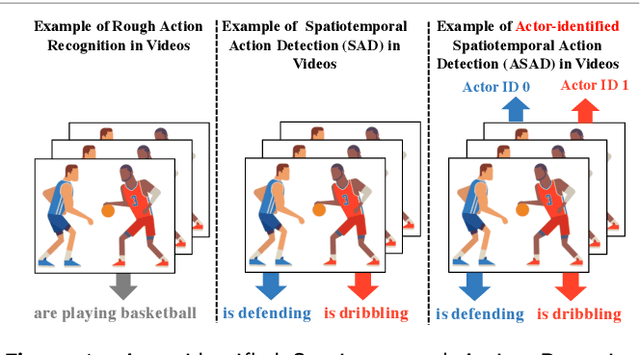

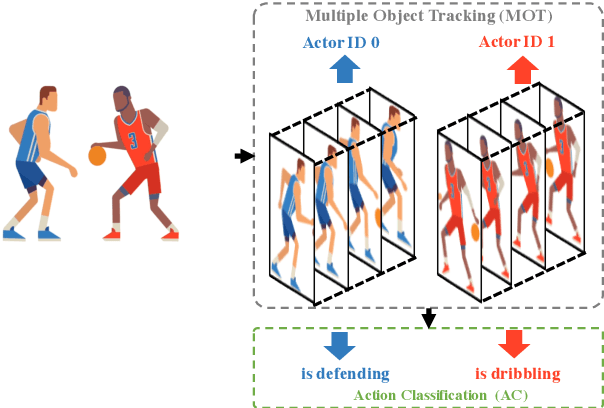

The success of deep learning on video Action Recognition (AR) has motivated researchers to progressively promote related tasks from the coarse level to the fine-grained level. Compared with conventional AR that only predicts an action label for the entire video, Temporal Action Detection (TAD) has been investigated for estimating the start and end time for each action in videos. Taking TAD a step further, Spatiotemporal Action Detection (SAD) has been studied for localizing the action both spatially and temporally in videos. However, who performs the action, is generally ignored in SAD, while identifying the actor could also be important. To this end, we propose a novel task, Actor-identified Spatiotemporal Action Detection (ASAD), to bridge the gap between SAD and actor identification. In ASAD, we not only detect the spatiotemporal boundary for instance-level action but also assign the unique ID to each actor. To approach ASAD, Multiple Object Tracking (MOT) and Action Classification (AC) are two fundamental elements. By using MOT, the spatiotemporal boundary of each actor is obtained and assigned to a unique actor identity. By using AC, the action class is estimated within the corresponding spatiotemporal boundary. Since ASAD is a new task, it poses many new challenges that cannot be addressed by existing methods: i) no dataset is specifically created for ASAD, ii) no evaluation metrics are designed for ASAD, iii) current MOT performance is the bottleneck to obtain satisfactory ASAD results. To address those problems, we contribute to i) annotate a new ASAD dataset, ii) propose ASAD evaluation metrics by considering multi-label actions and actor identification, iii) improve the data association strategies in MOT to boost the MOT performance, which leads to better ASAD results. The code is available at \url{https://github.com/fandulu/ASAD}.
USB: A Unified Semi-supervised Learning Benchmark
Aug 12, 2022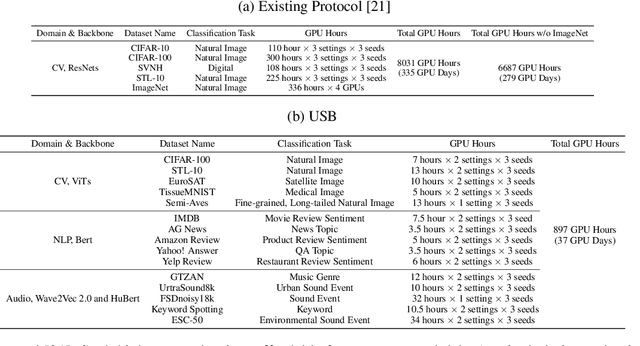
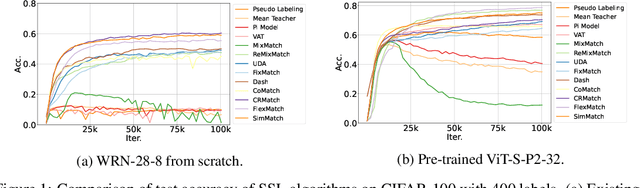
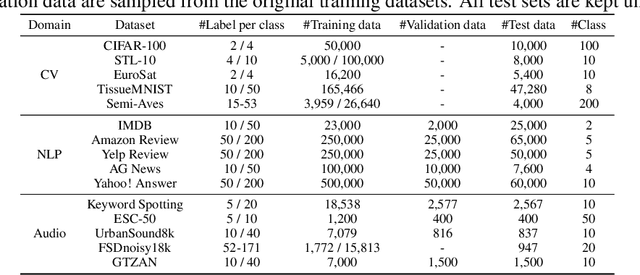
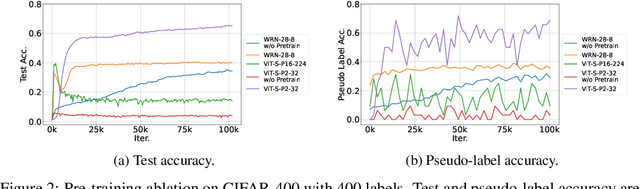
Semi-supervised learning (SSL) improves model generalization by leveraging massive unlabeled data to augment limited labeled samples. However, currently, popular SSL evaluation protocols are often constrained to computer vision (CV) tasks. In addition, previous work typically trains deep neural networks from scratch, which is time-consuming and environmentally unfriendly. To address the above issues, we construct a Unified SSL Benchmark (USB) by selecting 15 diverse, challenging, and comprehensive tasks from CV, natural language processing (NLP), and audio processing (Audio), on which we systematically evaluate dominant SSL methods, and also open-source a modular and extensible codebase for fair evaluation on these SSL methods. We further provide pre-trained versions of the state-of-the-art neural models for CV tasks to make the cost affordable for further tuning. USB enables the evaluation of a single SSL algorithm on more tasks from multiple domains but with less cost. Specifically, on a single NVIDIA V100, only 37 GPU days are required to evaluate FixMatch on 15 tasks in USB while 335 GPU days (279 GPU days on 4 CV datasets except for ImageNet) are needed on 5 CV tasks with the typical protocol.
Speech Artifact Removal from EEG Recordings of Spoken Word Production with Tensor Decomposition
Jun 01, 2022
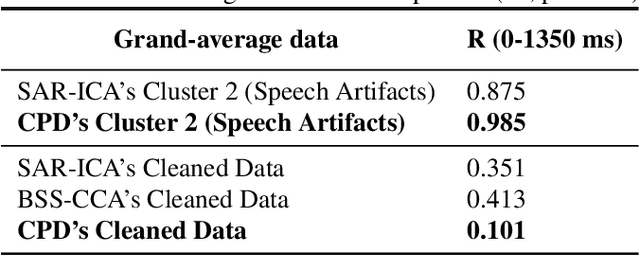
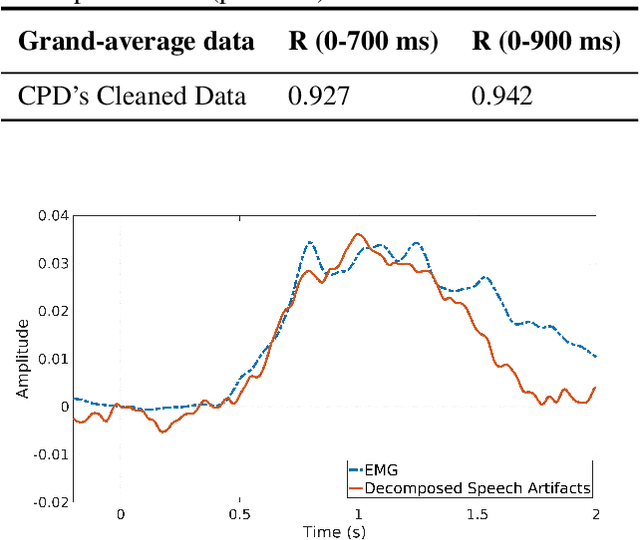
Research about brain activities involving spoken word production is considerably underdeveloped because of the undiscovered characteristics of speech artifacts, which contaminate electroencephalogram (EEG) signals and prevent the inspection of the underlying cognitive processes. To fuel further EEG research with speech production, a method using three-mode tensor decomposition (time x space x frequency) is proposed to perform speech artifact removal. Tensor decomposition enables simultaneous inspection of multiple modes, which suits the multi-way nature of EEG data. In a picture-naming task, we collected raw data with speech artifacts by placing two electrodes near the mouth to record lip EMG. Based on our evaluation, which calculated the correlation values between grand-averaged speech artifacts and the lip EMG, tensor decomposition outperformed the former methods that were based on independent component analysis (ICA) and blind source separation (BSS), both in detecting speech artifact (0.985) and producing clean data (0.101). Our proposed method correctly preserved the components unrelated to speech, which was validated by computing the correlation value between the grand-averaged raw data without EOG and cleaned data before the speech onset (0.92-0.94).
Improved Consistency Training for Semi-Supervised Sequence-to-Sequence ASR via Speech Chain Reconstruction and Self-Transcribing
May 14, 2022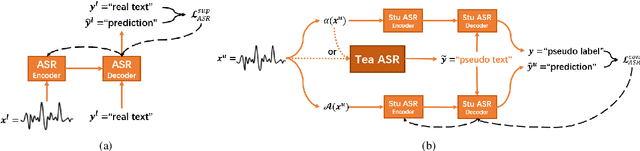
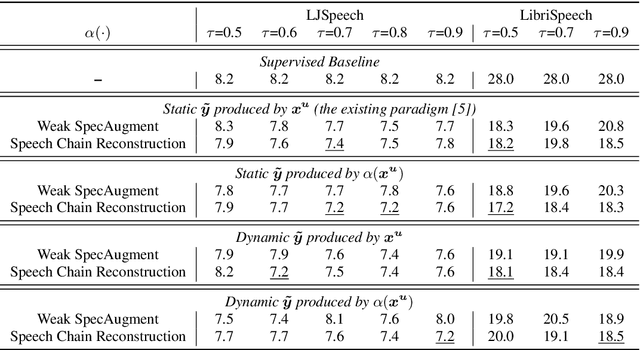
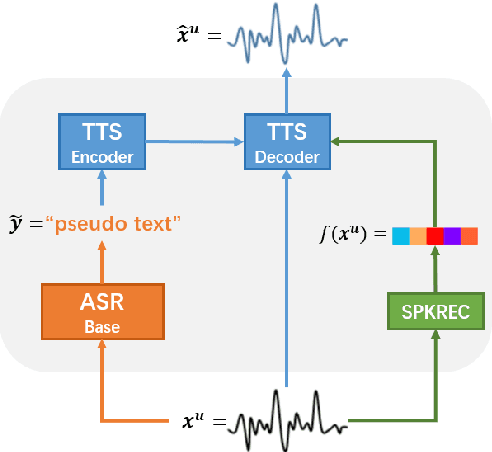
Consistency regularization has recently been applied to semi-supervised sequence-to-sequence (S2S) automatic speech recognition (ASR). This principle encourages an ASR model to output similar predictions for the same input speech with different perturbations. The existing paradigm of semi-supervised S2S ASR utilizes SpecAugment as data augmentation and requires a static teacher model to produce pseudo transcripts for untranscribed speech. However, this paradigm fails to take full advantage of consistency regularization. First, the masking operations of SpecAugment may damage the linguistic contents of the speech, thus influencing the quality of pseudo labels. Second, S2S ASR requires both input speech and prefix tokens to make the next prediction. The static prefix tokens made by the offline teacher model cannot match dynamic pseudo labels during consistency training. In this work, we propose an improved consistency training paradigm of semi-supervised S2S ASR. We utilize speech chain reconstruction as the weak augmentation to generate high-quality pseudo labels. Moreover, we demonstrate that dynamic pseudo transcripts produced by the student ASR model benefit the consistency training. Experiments on LJSpeech and LibriSpeech corpora show that compared to supervised baselines, our improved paradigm achieves a 12.2% CER improvement in the single-speaker setting and 38.6% in the multi-speaker setting.
Representing `how you say' with `what you say': English corpus of focused speech and text reflecting corresponding implications
Mar 29, 2022
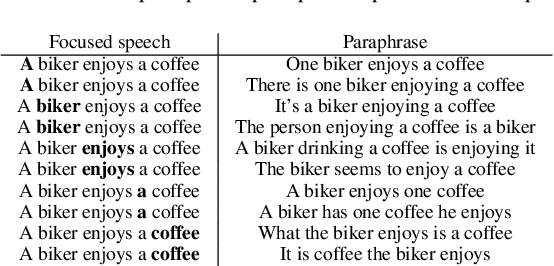
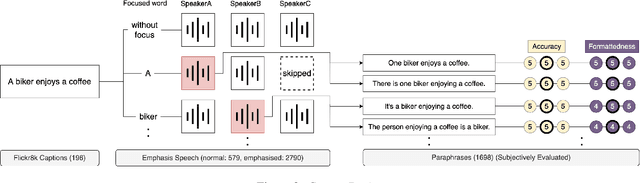
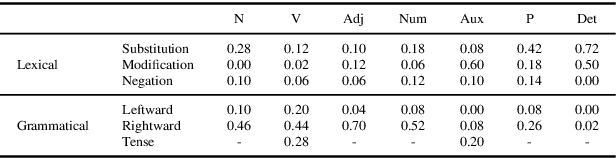
In speech communication, how something is said (paralinguistic information) is as crucial as what is said (linguistic information). As a type of paralinguistic information, English speech uses sentence stress, the heaviest prominence within a sentence, to convey emphasis. While different placements of sentence stress communicate different emphatic implications, current speech translation systems return the same translations if the utterances are linguistically identical, losing paralinguistic information. Concentrating on focus, a type of emphasis, we propose mapping paralinguistic information into the linguistic domain within the source language using lexical and grammatical devices. This method enables us to translate the paraphrased text representations instead of the transcription of the original speech and obtain translations that preserve paralinguistic information. As a first step, we present the collection of an English corpus containing speech that differed in the placement of focus along with the corresponding text, which was designed to reflect the implied meaning of the speech. Also, analyses of our corpus demonstrated that mapping of focus from the paralinguistic domain into the linguistic domain involved various lexical and grammatical methods. The data and insights from our analysis will further advance research into paralinguistic translation. The corpus will be published via LDC.
Speech Segmentation Optimization using Segmented Bilingual Speech Corpus for End-to-end Speech Translation
Mar 29, 2022
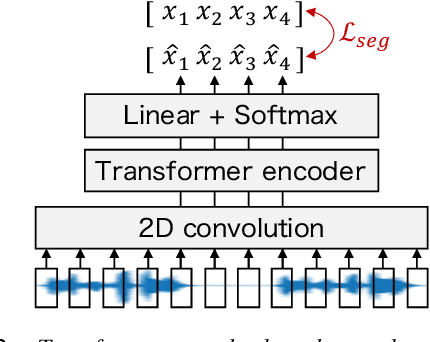
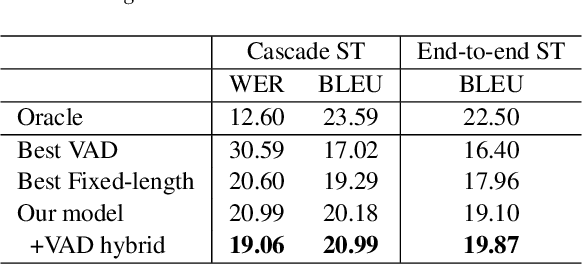
Speech segmentation, which splits long speech into short segments, is essential for speech translation (ST). Popular VAD tools like WebRTC VAD have generally relied on pause-based segmentation. Unfortunately, pauses in speech do not necessarily match sentence boundaries, and sentences can be connected by a very short pause that is difficult to detect by VAD. In this study, we propose a speech segmentation method using a binary classification model trained using a segmented bilingual speech corpus. We also propose a hybrid method that combines VAD and the above speech segmentation method. Experimental results revealed that the proposed method is more suitable for cascade and end-to-end ST systems than conventional segmentation methods. The hybrid approach further improved the translation performance.
Applying Syntax$\unicode{x2013}$Prosody Mapping Hypothesis and Prosodic Well-Formedness Constraints to Neural Sequence-to-Sequence Speech Synthesis
Mar 29, 2022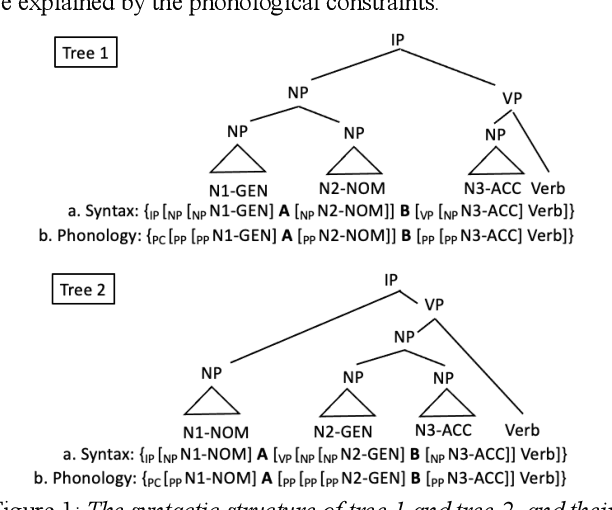
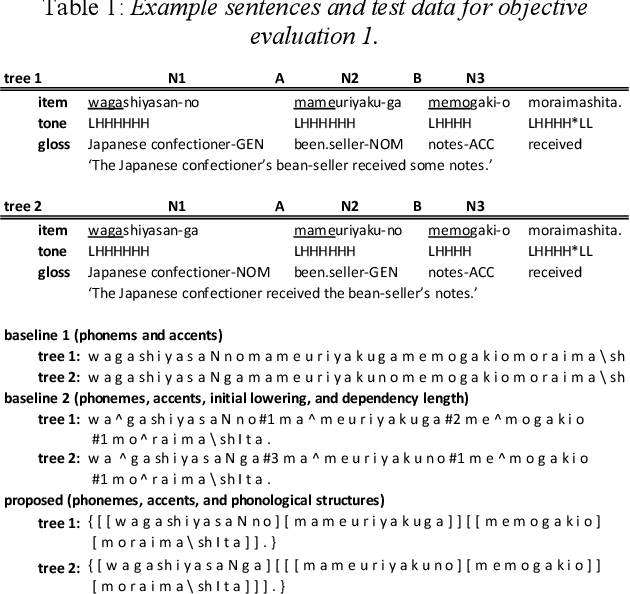
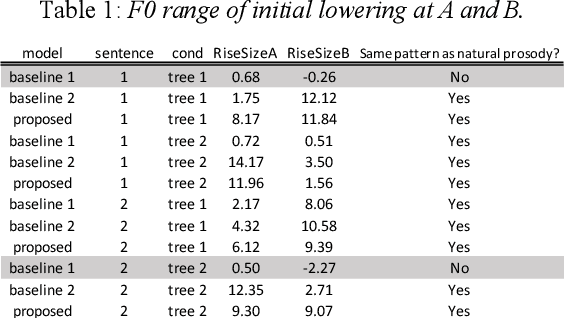
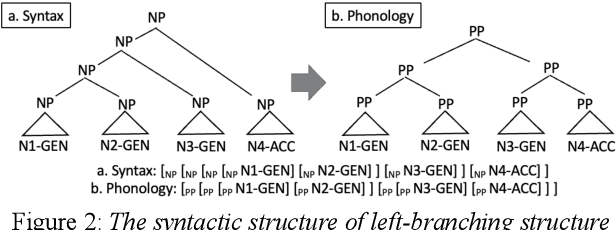
End-to-end text-to-speech synthesis (TTS), which generates speech sounds directly from strings of texts or phonemes, has improved the quality of speech synthesis over the conventional TTS. However, most previous studies have been evaluated based on subjective naturalness and have not objectively examined whether they can reproduce pitch patterns of phonological phenomena such as downstep, rhythmic boost, and initial lowering that reflect syntactic structures in Japanese. These phenomena can be linguistically explained by phonological constraints and the syntax$\unicode{x2013}$prosody mapping hypothesis (SPMH), which assumes projections from syntactic structures to phonological hierarchy. Although some experiments in psycholinguistics have verified the validity of the SPMH, it is crucial to investigate whether it can be implemented in TTS. To synthesize linguistic phenomena involving syntactic or phonological constraints, we propose a model using phonological symbols based on the SPMH and prosodic well-formedness constraints. Experimental results showed that the proposed method synthesized similar pitch patterns to those reported in linguistics experiments for the phenomena of initial lowering and rhythmic boost. The proposed model efficiently synthesizes phonological phenomena in the test data that were not explicitly included in the training data.
Simultaneous Neural Machine Translation with Constituent Label Prediction
Oct 26, 2021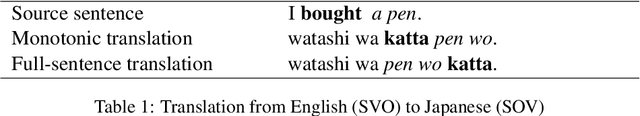
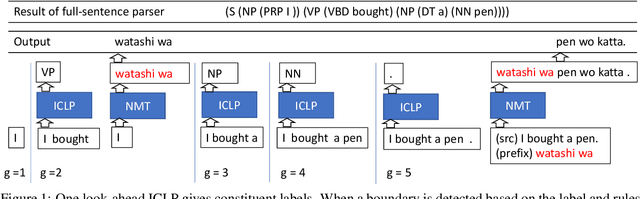
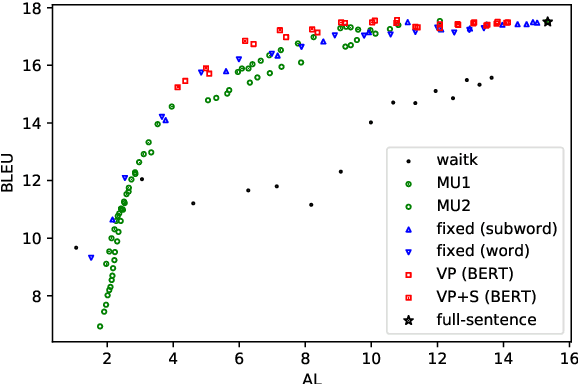

Simultaneous translation is a task in which translation begins before the speaker has finished speaking, so it is important to decide when to start the translation process. However, deciding whether to read more input words or start to translate is difficult for language pairs with different word orders such as English and Japanese. Motivated by the concept of pre-reordering, we propose a couple of simple decision rules using the label of the next constituent predicted by incremental constituent label prediction. In experiments on English-to-Japanese simultaneous translation, the proposed method outperformed baselines in the quality-latency trade-off.
Using Perturbed Length-aware Positional Encoding for Non-autoregressive Neural Machine Translation
Jul 29, 2021
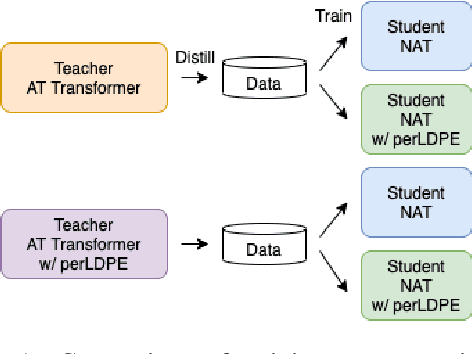
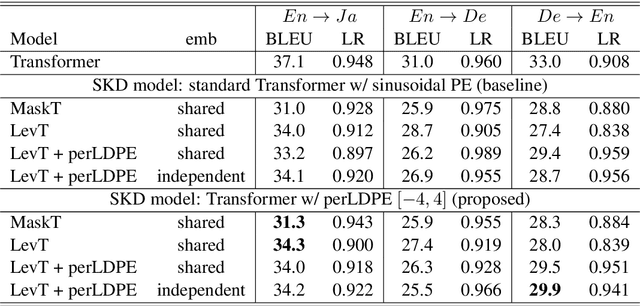
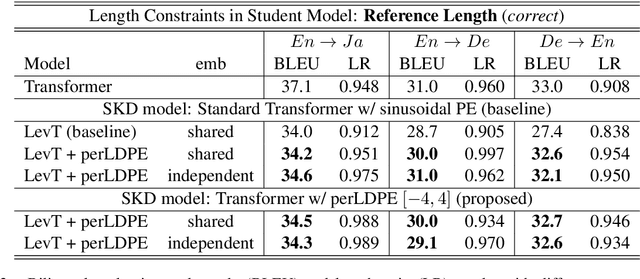
Non-autoregressive neural machine translation (NAT) usually employs sequence-level knowledge distillation using autoregressive neural machine translation (AT) as its teacher model. However, a NAT model often outputs shorter sentences than an AT model. In this work, we propose sequence-level knowledge distillation (SKD) using perturbed length-aware positional encoding and apply it to a student model, the Levenshtein Transformer. Our method outperformed a standard Levenshtein Transformer by 2.5 points in bilingual evaluation understudy (BLEU) at maximum in a WMT14 German to English translation. The NAT model output longer sentences than the baseline NAT models.