 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponse Generation for Cognitive Behavioral Therapy with Large Language Models: Comparative Study with Socratic Questioning
Jan 29, 2024



Dialogue systems controlled by predefined or rule-based scenarios derived from counseling techniques, such as cognitive behavioral therapy (CBT), play an important role in mental health apps. Despite the need for responsible responses, it is conceivable that using the newly emerging LLMs to generate contextually relevant utterances will enhance these apps. In this study, we construct dialogue modules based on a CBT scenario focused on conventional Socratic questioning using two kinds of LLMs: a Transformer-based dialogue model further trained with a social media empathetic counseling dataset, provided by Osaka Prefecture (OsakaED), and GPT-4, a state-of-the art LLM created by OpenAI. By comparing systems that use LLM-generated responses with those that do not, we investigate the impact of generated responses on subjective evaluations such as mood change, cognitive change, and dialogue quality (e.g., empathy). As a result, no notable improvements are observed when using the OsakaED model. When using GPT-4, the amount of mood change, empathy, and other dialogue qualities improve significantly. Results suggest that GPT-4 possesses a high counseling ability. However, they also indicate that even when using a dialogue model trained with a human counseling dataset, it does not necessarily yield better outcomes compared to scenario-based dialogues. While presenting LLM-generated responses, including GPT-4, and having them interact directly with users in real-life mental health care services may raise ethical issues, it is still possible for human professionals to produce example responses or response templates using LLMs in advance in systems that use rules, scenarios, or example responses.
Computational analyses of linguistic features with schizophrenic and autistic traits along with formal thought disorders
Oct 14, 2023



[See full abstract in the pdf] Formal Thought Disorder (FTD), which is a group of symptoms in cognition that affects language and thought, can be observed through language. FTD is seen across such developmental or psychiatric disorders as Autism Spectrum Disorder (ASD) or Schizophrenia, and its related Schizotypal Personality Disorder (SPD). This paper collected a Japanese audio-report dataset with score labels related to ASD and SPD through a crowd-sourcing service from the general population. We measured language characteristics with the 2nd edition of the Social Responsiveness Scale (SRS2) and the Schizotypal Personality Questionnaire (SPQ), including an odd speech subscale from SPQ to quantify the FTD symptoms. We investigated the following four research questions through machine-learning-based score predictions: (RQ1) How are schizotypal and autistic measures correlated? (RQ2) What is the most suitable task to elicit FTD symptoms? (RQ3) Does the length of speech affect the elicitation of FTD symptoms? (RQ4) Which features are critical for capturing FTD symptoms? We confirmed that an FTD-related subscale, odd speech, was significantly correlated with both the total SPQ and SRS scores, although they themselves were not correlated significantly. Our regression analysis indicated that longer speech about a negative memory elicited more FTD symptoms. The ablation study confirmed the importance of function words and both the abstract and temporal features for FTD-related odd speech estimation. In contrast, content words were effective only in the SRS predictions, and content words were effective only in the SPQ predictions, a result that implies the differences between SPD-like and ASD-like symptoms. Data and programs used in this paper can be found here: https://sites.google.com/view/sagatake/resource.
* This is a revised version of the ICMI2023 paper with the same title
Speech Artifact Removal from EEG Recordings of Spoken Word Production with Tensor Decomposition
Jun 01, 2022
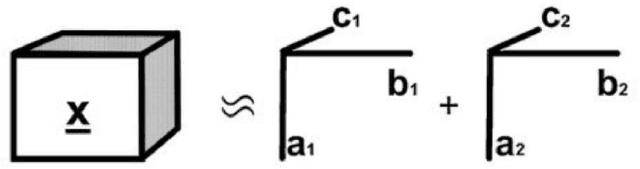
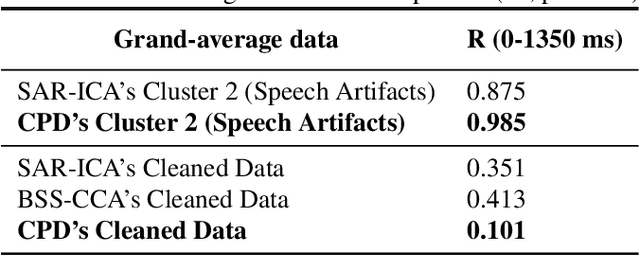
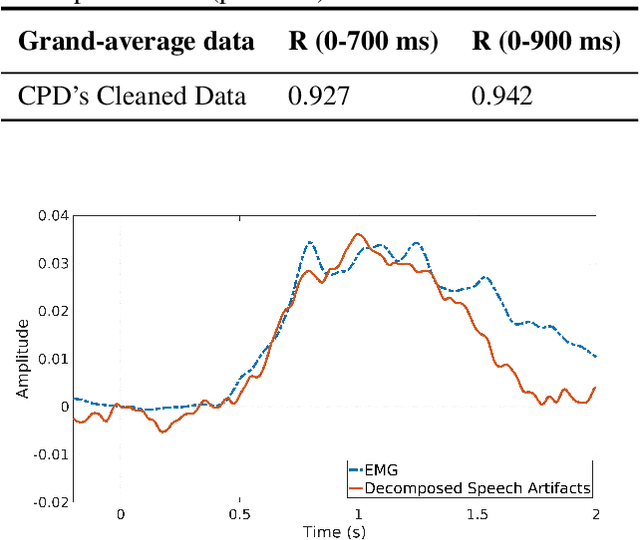
Research about brain activities involving spoken word production is considerably underdeveloped because of the undiscovered characteristics of speech artifacts, which contaminate electroencephalogram (EEG) signals and prevent the inspection of the underlying cognitive processes. To fuel further EEG research with speech production, a method using three-mode tensor decomposition (time x space x frequency) is proposed to perform speech artifact removal. Tensor decomposition enables simultaneous inspection of multiple modes, which suits the multi-way nature of EEG data. In a picture-naming task, we collected raw data with speech artifacts by placing two electrodes near the mouth to record lip EMG. Based on our evaluation, which calculated the correlation values between grand-averaged speech artifacts and the lip EMG, tensor decomposition outperformed the former methods that were based on independent component analysis (ICA) and blind source separation (BSS), both in detecting speech artifact (0.985) and producing clean data (0.101). Our proposed method correctly preserved the components unrelated to speech, which was validated by computing the correlation value between the grand-averaged raw data without EOG and cleaned data before the speech onset (0.92-0.94).