 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookbehind Optimizer: k steps back, 1 step forward
Jul 31, 2023The Lookahead optimizer improves the training stability of deep neural networks by having a set of fast weights that "look ahead" to guide the descent direction. Here, we combine this idea with sharpness-aware minimization (SAM) to stabilize its multi-step variant and improve the loss-sharpness trade-off. We propose Lookbehind, which computes $k$ gradient ascent steps ("looking behind") at each iteration and combine the gradients to bias the descent step toward flatter minima. We apply Lookbehind on top of two popular sharpness-aware training methods -- SAM and adaptive SAM (ASAM) -- and show that our approach leads to a myriad of benefits across a variety of tasks and training regimes. Particularly, we show increased generalization performance, greater robustness against noisy weights, and higher tolerance to catastrophic forgetting in lifelong learning settings.
Promoting Exploration in Memory-Augmented Adam using Critical Momenta
Jul 18, 2023Adaptive gradient-based optimizers, particularly Adam, have left their mark in training large-scale deep learning models. The strength of such optimizers is that they exhibit fast convergence while being more robust to hyperparameter choice. However, they often generalize worse than non-adaptive methods. Recent studies have tied this performance gap to flat minima selection: adaptive methods tend to find solutions in sharper basins of the loss landscape, which in turn hurts generalization. To overcome this issue, we propose a new memory-augmented version of Adam that promotes exploration towards flatter minima by using a buffer of critical momentum terms during training. Intuitively, the use of the buffer makes the optimizer overshoot outside the basin of attraction if it is not wide enough. We empirically show that our method improves the performance of several variants of Adam on standard supervised language modelling and image classification tasks.
Thompson sampling for improved exploration in GFlowNets
Jun 30, 2023Generative flow networks (GFlowNets) are amortized variational inference algorithms that treat sampling from a distribution over compositional objects as a sequential decision-making problem with a learnable action policy. Unlike other algorithms for hierarchical sampling that optimize a variational bound, GFlowNet algorithms can stably run off-policy, which can be advantageous for discovering modes of the target distribution. Despite this flexibility in the choice of behaviour policy, the optimal way of efficiently selecting trajectories for training has not yet been systematically explored. In this paper, we view the choice of trajectories for training as an active learning problem and approach it using Bayesian techniques inspired by methods for multi-armed bandits. The proposed algorithm, Thompson sampling GFlowNets (TS-GFN), maintains an approximate posterior distribution over policies and samples trajectories from this posterior for training. We show in two domains that TS-GFN yields improved exploration and thus faster convergence to the target distribution than the off-policy exploration strategies used in past work.
Measuring the Knowledge Acquisition-Utilization Gap in Pretrained Language Models
May 24, 2023While pre-trained language models (PLMs) have shown evidence of acquiring vast amounts of knowledge, it remains unclear how much of this parametric knowledge is actually usable in performing downstream tasks. We propose a systematic framework to measure parametric knowledge utilization in PLMs. Our framework first extracts knowledge from a PLM's parameters and subsequently constructs a downstream task around this extracted knowledge. Performance on this task thus depends exclusively on utilizing the model's possessed knowledge, avoiding confounding factors like insufficient signal. As an instantiation, we study factual knowledge of PLMs and measure utilization across 125M to 13B parameter PLMs. We observe that: (1) PLMs exhibit two gaps - in acquired vs. utilized knowledge, (2) they show limited robustness in utilizing knowledge under distribution shifts, and (3) larger models close the acquired knowledge gap but the utilized knowledge gap remains. Overall, our study provides insights into PLMs' capabilities beyond their acquired knowledge.
Should We Attend More or Less? Modulating Attention for Fairness
May 22, 2023



The abundance of annotated data in natural language processing (NLP) poses both opportunities and challenges. While it enables the development of high-performing models for a variety of tasks, it also poses the risk of models learning harmful biases from the data, such as gender stereotypes. In this work, we investigate the role of attention, a widely-used technique in current state-of-the-art NLP models, in the propagation of social biases. Specifically, we study the relationship between the entropy of the attention distribution and the model's performance and fairness. We then propose a novel method for modulating attention weights to improve model fairness after training. Since our method is only applied post-training and pre-inference, it is an intra-processing method and is, therefore, less computationally expensive than existing in-processing and pre-processing approaches. Our results show an increase in fairness and minimal performance loss on different text classification and generation tasks using language models of varying sizes. WARNING: This work uses language that is offensive.
Conditionally Optimistic Exploration for Cooperative Deep Multi-Agent Reinforcement Learning
Mar 16, 2023



Efficient exploration is critical in cooperative deep Multi-Agent Reinforcement Learning (MARL). In this paper, we propose an exploration method that efficiently encourages cooperative exploration based on the idea of the theoretically justified tree search algorithm UCT (Upper Confidence bounds applied to Trees). The high-level intuition is that to perform optimism-based exploration, agents would achieve cooperative strategies if each agent's optimism estimate captures a structured dependency relationship with other agents. At each node (i.e., action) of the search tree, UCT performs optimism-based exploration using a bonus derived by conditioning on the visitation count of its parent node. We provide a perspective to view MARL as tree search iterations and develop a method called Conditionally Optimistic Exploration (COE). We assume agents take actions following a sequential order, and consider nodes at the same depth of the search tree as actions of one individual agent. COE computes each agent's state-action value estimate with an optimistic bonus derived from the visitation count of the state and joint actions taken by agents up to the current agent. COE is adaptable to any value decomposition method for centralized training with decentralized execution. Experiments across various cooperative MARL benchmarks show that COE outperforms current state-of-the-art exploration methods on hard-exploration tasks.
Replay Buffer With Local Forgetting for Adaptive Deep Model-Based Reinforcement Learning
Mar 15, 2023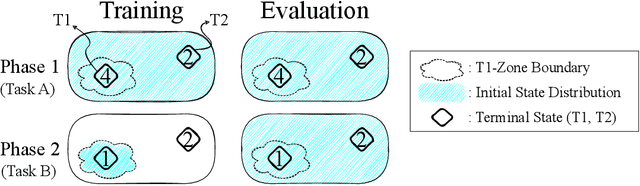
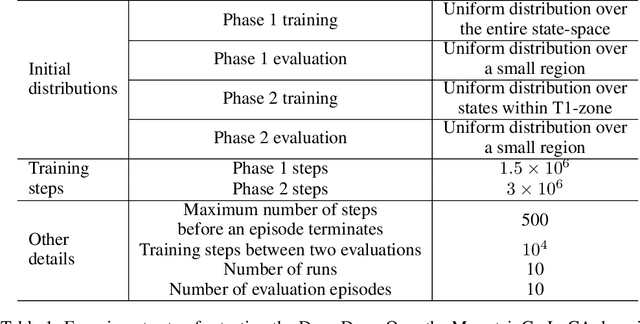
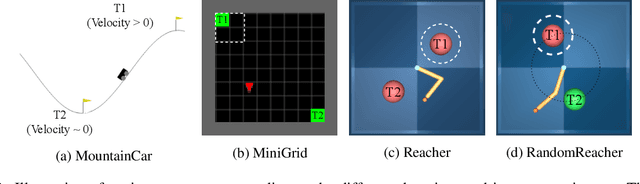
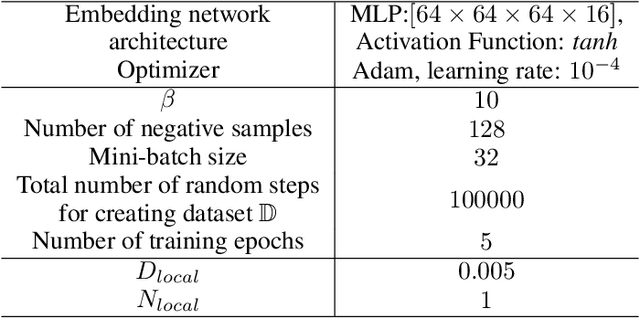
One of the key behavioral characteristics used in neuroscience to determine whether the subject of study -- be it a rodent or a human -- exhibits model-based learning is effective adaptation to local changes in the environment. In reinforcement learning, however, recent work has shown that modern deep model-based reinforcement-learning (MBRL) methods adapt poorly to such changes. An explanation for this mismatch is that MBRL methods are typically designed with sample-efficiency on a single task in mind and the requirements for effective adaptation are substantially higher, both in terms of the learned world model and the planning routine. One particularly challenging requirement is that the learned world model has to be sufficiently accurate throughout relevant parts of the state-space. This is challenging for deep-learning-based world models due to catastrophic forgetting. And while a replay buffer can mitigate the effects of catastrophic forgetting, the traditional first-in-first-out replay buffer precludes effective adaptation due to maintaining stale data. In this work, we show that a conceptually simple variation of this traditional replay buffer is able to overcome this limitation. By removing only samples from the buffer from the local neighbourhood of the newly observed samples, deep world models can be built that maintain their accuracy across the state-space, while also being able to effectively adapt to changes in the reward function. We demonstrate this by applying our replay-buffer variation to a deep version of the classical Dyna method, as well as to recent methods such as PlaNet and DreamerV2, demonstrating that deep model-based methods can adapt effectively as well to local changes in the environment.
Dealing With Non-stationarity in Decentralized Cooperative Multi-Agent Deep Reinforcement Learning via Multi-Timescale Learning
Feb 06, 2023



Decentralized cooperative multi-agent deep reinforcement learning (MARL) can be a versatile learning framework, particularly in scenarios where centralized training is either not possible or not practical. One of the key challenges in decentralized deep MARL is the non-stationarity of the learning environment when multiple agents are learning concurrently. A commonly used and efficient scheme for decentralized MARL is independent learning in which agents concurrently update their policies independent of each other. We first show that independent learning does not always converge, while sequential learning where agents update their policies one after another in a sequence is guaranteed to converge to an agent-by-agent optimal solution. In sequential learning, when one agent updates its policy, all other agent's policies are kept fixed, alleviating the challenge of non-stationarity due to concurrent updates in other agents' policies. However, it can be slow because only one agent is learning at any time. Therefore it might also not always be practical. In this work, we propose a decentralized cooperative MARL algorithm based on multi-timescale learning. In multi-timescale learning, all agents learn concurrently, but at different learning rates. In our proposed method, when one agent updates its policy, other agents are allowed to update their policies as well, but at a slower rate. This speeds up sequential learning, while also minimizing non-stationarity caused by other agents updating concurrently. Multi-timescale learning outperforms state-of-the-art decentralized learning methods on a set of challenging multi-agent cooperative tasks in the epymarl (papoudakis2020) benchmark. This can be seen as a first step towards more general decentralized cooperative deep MARL methods based on multi-timescale learning.
Deep Learning on a Healthy Data Diet: Finding Important Examples for Fairness
Nov 25, 2022



Data-driven predictive solutions predominant in commercial applications tend to suffer from biases and stereotypes, which raises equity concerns. Prediction models may discover, use, or amplify spurious correlations based on gender or other protected personal characteristics, thus discriminating against marginalized groups. Mitigating gender bias has become an important research focus in natural language processing (NLP) and is an area where annotated corpora are available. Data augmentation reduces gender bias by adding counterfactual examples to the training dataset. In this work, we show that some of the examples in the augmented dataset can be not important or even harmful for fairness. We hence propose a general method for pruning both the factual and counterfactual examples to maximize the model's fairness as measured by the demographic parity, equality of opportunity, and equality of odds. The fairness achieved by our method surpasses that of data augmentation on three text classification datasets, using no more than half of the examples in the augmented dataset. Our experiments are conducted using models of varying sizes and pre-training settings.
Sharpness-Aware Training for Accurate Inference on Noisy DNN Accelerators
Nov 18, 2022



Energy-efficient deep neural network (DNN) accelerators are prone to non-idealities that degrade DNN performance at inference time. To mitigate such degradation, existing methods typically add perturbations to the DNN weights during training to simulate inference on noisy hardware. However, this often requires knowledge about the target hardware and leads to a trade-off between DNN performance and robustness, decreasing the former to increase the latter. In this work, we show that applying sharpness-aware training by optimizing for both the loss value and the loss sharpness significantly improves robustness to noisy hardware at inference time while also increasing DNN performance. We further motivate our results by showing a high correlation between loss sharpness and model robustness. We show superior performance compared to injecting noise during training and aggressive weight clipping on multiple architectures, optimizers, datasets, and training regimes without relying on any assumptions about the target hardware. This is observed on a generic noise model as well as on accurate noise simulations from real hardware.