 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Compositional Shape Priors for Few-Shot 3D Reconstruction
Jun 16, 2021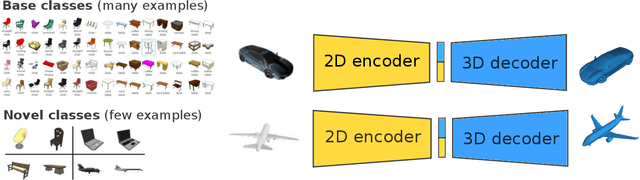
The impressive performance of deep convolutional neural networks in single-view 3D reconstruction suggests that these models perform non-trivial reasoning about the 3D structure of the output space. Recent work has challenged this belief, showing that, on standard benchmarks, complex encoder-decoder architectures perform similarly to nearest-neighbor baselines or simple linear decoder models that exploit large amounts of per-category data. However, building large collections of 3D shapes for supervised training is a laborious process; a more realistic and less constraining task is inferring 3D shapes for categories with few available training examples, calling for a model that can successfully generalize to novel object classes. In this work we experimentally demonstrate that naive baselines fail in this few-shot learning setting, in which the network must learn informative shape priors for inference of new categories. We propose three ways to learn a class-specific global shape prior, directly from data. Using these techniques, we are able to capture multi-scale information about the 3D shape, and account for intra-class variability by virtue of an implicit compositional structure. Experiments on the popular ShapeNet dataset show that our method outperforms a zero-shot baseline by over 40%, and the current state-of-the-art by over 10%, in terms of relative performance, in the few-shot setting.
Probabilistic 3D surface reconstruction from sparse MRI information
Oct 05, 2020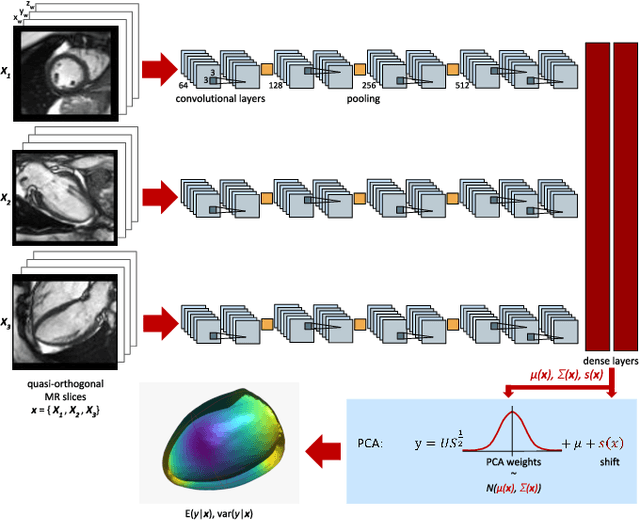
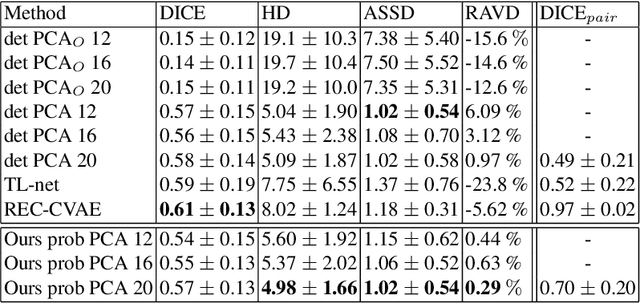

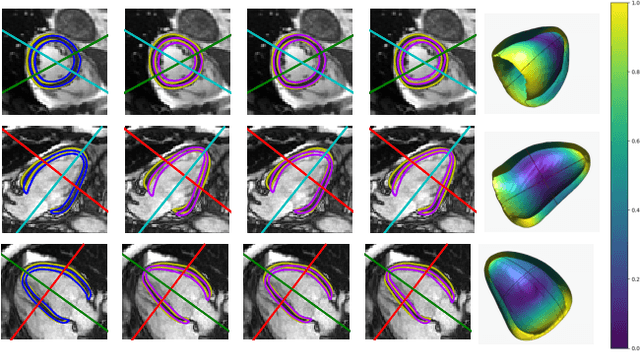
Surface reconstruction from magnetic resonance (MR) imaging data is indispensable in medical image analysis and clinical research. A reliable and effective reconstruction tool should: be fast in prediction of accurate well localised and high resolution models, evaluate prediction uncertainty, work with as little input data as possible. Current deep learning state of the art (SOTA) 3D reconstruction methods, however, often only produce shapes of limited variability positioned in a canonical position or lack uncertainty evaluation. In this paper, we present a novel probabilistic deep learning approach for concurrent 3D surface reconstruction from sparse 2D MR image data and aleatoric uncertainty prediction. Our method is capable of reconstructing large surface meshes from three quasi-orthogonal MR imaging slices from limited training sets whilst modelling the location of each mesh vertex through a Gaussian distribution. Prior shape information is encoded using a built-in linear principal component analysis (PCA) model. Extensive experiments on cardiac MR data show that our probabilistic approach successfully assesses prediction uncertainty while at the same time qualitatively and quantitatively outperforms SOTA methods in shape prediction. Compared to SOTA, we are capable of properly localising and orientating the prediction via the use of a spatially aware neural network.
Many-shot from Low-shot: Learning to Annotate using Mixed Supervision for Object Detection
Aug 26, 2020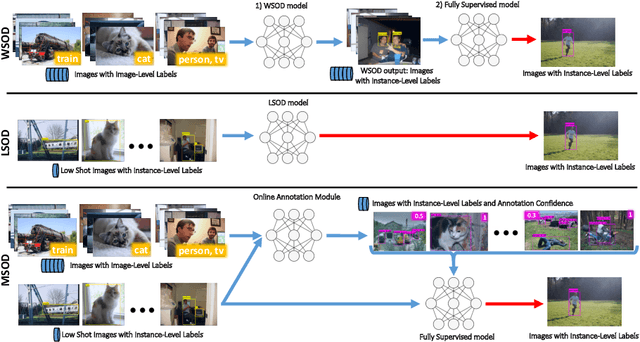
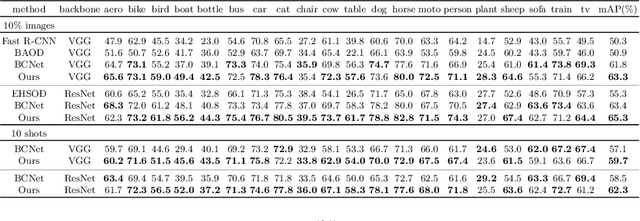
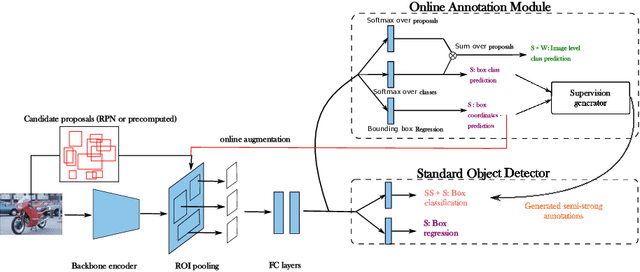
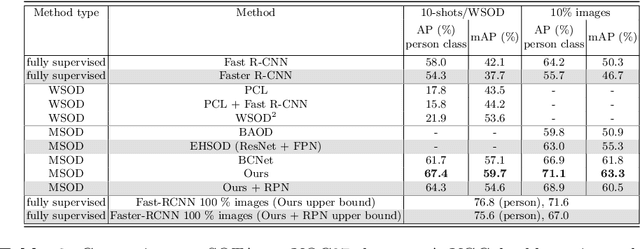
Object detection has witnessed significant progress by relying on large, manually annotated datasets. Annotating such datasets is highly time consuming and expensive, which motivates the development of weakly supervised and few-shot object detection methods. However, these methods largely underperform with respect to their strongly supervised counterpart, as weak training signals \emph{often} result in partial or oversized detections. Towards solving this problem we introduce, for the first time, an online annotation module (OAM) that learns to generate a many-shot set of \emph{reliable} annotations from a larger volume of weakly labelled images. Our OAM can be jointly trained with any fully supervised two-stage object detection method, providing additional training annotations on the fly. This results in a fully end-to-end strategy that only requires a low-shot set of fully annotated images. The integration of the OAM with Fast(er) R-CNN improves their performance by $17\%$ mAP, $9\%$ AP50 on PASCAL VOC 2007 and MS-COCO benchmarks, and significantly outperforms competing methods using mixed supervision.
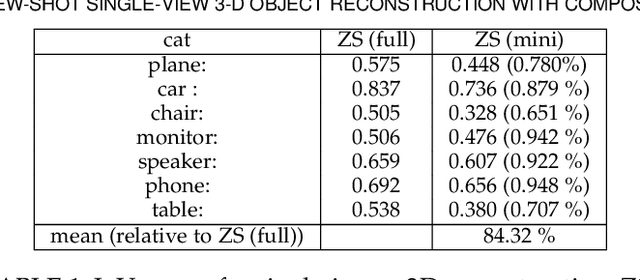
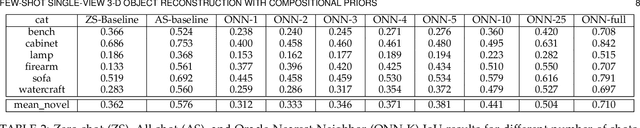
Few-Shot Single-View 3-D Object Reconstruction with Compositional Priors
May 03, 2020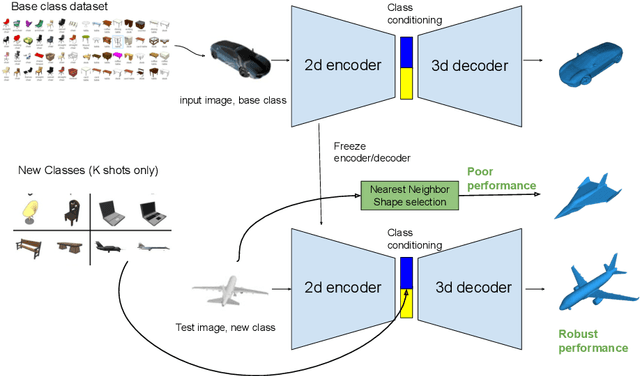
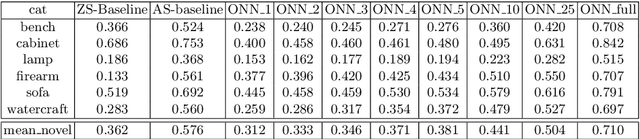
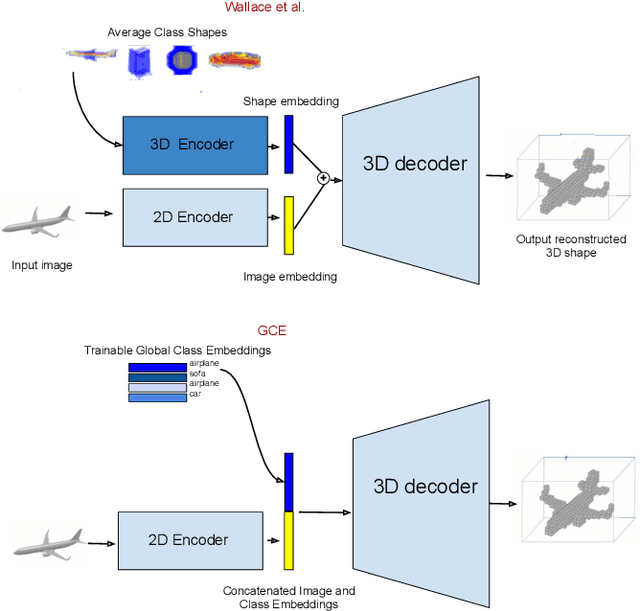
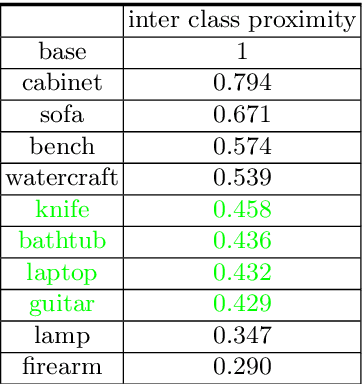
The impressive performance of deep convolutional neural networks in single-view 3D reconstruction suggests that these models perform non-trivial reasoning about the 3D structure of the output space. However, recent work has challenged this belief, showing that complex encoder-decoder architectures perform similarly to nearest-neighbor baselines or simple linear decoder models that exploit large amounts of per category data in standard benchmarks. On the other hand settings where 3D shape must be inferred for new categories with few examples are more natural and require models that generalize about shapes. In this work we demonstrate experimentally that naive baselines do not apply when the goal is to learn to reconstruct novel objects using very few examples, and that in a \emph{few-shot} learning setting, the network must learn concepts that can be applied to new categories, avoiding rote memorization. To address deficiencies in existing approaches to this problem, we propose three approaches that efficiently integrate a class prior into a 3D reconstruction model, allowing to account for intra-class variability and imposing an implicit compositional structure that the model should learn. Experiments on the popular ShapeNet database demonstrate that our method significantly outperform existing baselines on this task in the few-shot setting.
DeepLPF: Deep Local Parametric Filters for Image Enhancement
Mar 31, 2020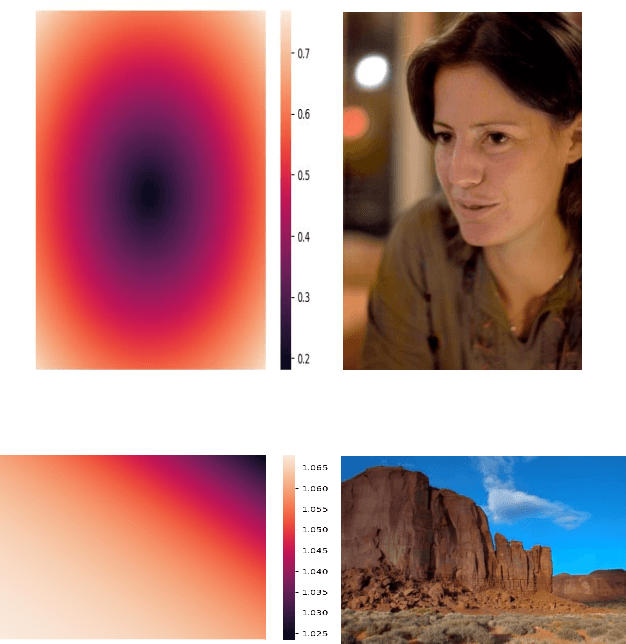


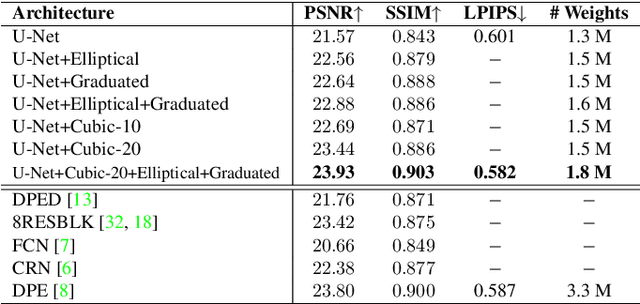
Digital artists often improve the aesthetic quality of digital photographs through manual retouching. Beyond global adjustments, professional image editing programs provide local adjustment tools operating on specific parts of an image. Options include parametric (graduated, radial filters) and unconstrained brush tools. These highly expressive tools enable a diverse set of local image enhancements. However, their use can be time consuming, and requires artistic capability. State-of-the-art automated image enhancement approaches typically focus on learning pixel-level or global enhancements. The former can be noisy and lack interpretability, while the latter can fail to capture fine-grained adjustments. In this paper, we introduce a novel approach to automatically enhance images using learned spatially local filters of three different types (Elliptical Filter, Graduated Filter, Polynomial Filter). We introduce a deep neural network, dubbed Deep Local Parametric Filters (DeepLPF), which regresses the parameters of these spatially localized filters that are then automatically applied to enhance the image. DeepLPF provides a natural form of model regularization and enables interpretable, intuitive adjustments that lead to visually pleasing results. We report on multiple benchmarks and show that DeepLPF produces state-of-the-art performance on two variants of the MIT-Adobe-5K dataset, often using a fraction of the parameters required for competing methods.
Unsupervised Model Personalization while Preserving Privacy and Scalability: An Open Problem
Mar 30, 2020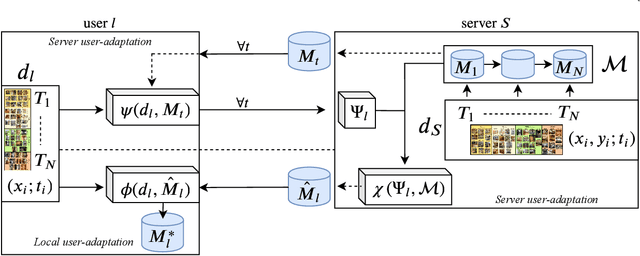
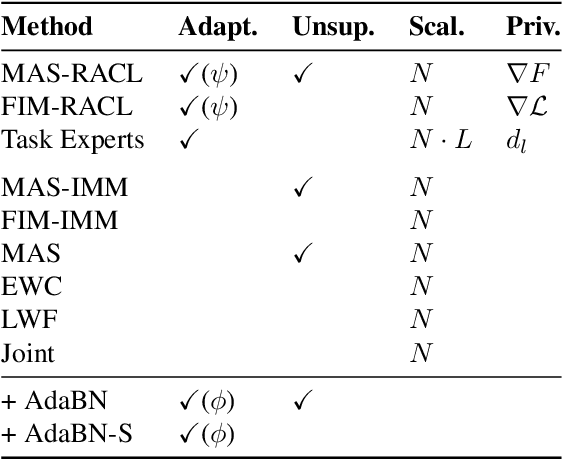

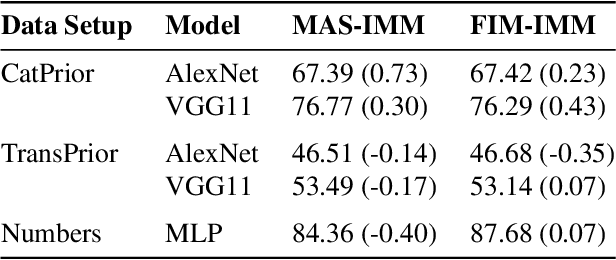
This work investigates the task of unsupervised model personalization, adapted to continually evolving, unlabeled local user images. We consider the practical scenario where a high capacity server interacts with a myriad of resource-limited edge devices, imposing strong requirements on scalability and local data privacy. We aim to address this challenge within the continual learning paradigm and provide a novel Dual User-Adaptation framework (DUA) to explore the problem. This framework flexibly disentangles user-adaptation into model personalization on the server and local data regularization on the user device, with desirable properties regarding scalability and privacy constraints. First, on the server, we introduce incremental learning of task-specific expert models, subsequently aggregated using a concealed unsupervised user prior. Aggregation avoids retraining, whereas the user prior conceals sensitive raw user data, and grants unsupervised adaptation. Second, local user-adaptation incorporates a domain adaptation point of view, adapting regularizing batch normalization parameters to the user data. We explore various empirical user configurations with different priors in categories and a tenfold of transforms for MIT Indoor Scene recognition, and classify numbers in a combined MNIST and SVHN setup. Extensive experiments yield promising results for data-driven local adaptation and elicit user priors for server adaptation to depend on the model rather than user data. Hence, although user-adaptation remains a challenging open problem, the DUA framework formalizes a principled foundation for personalizing both on server and user device, while maintaining privacy and scalability.
A Multi-Hypothesis Approach to Color Constancy
Mar 02, 2020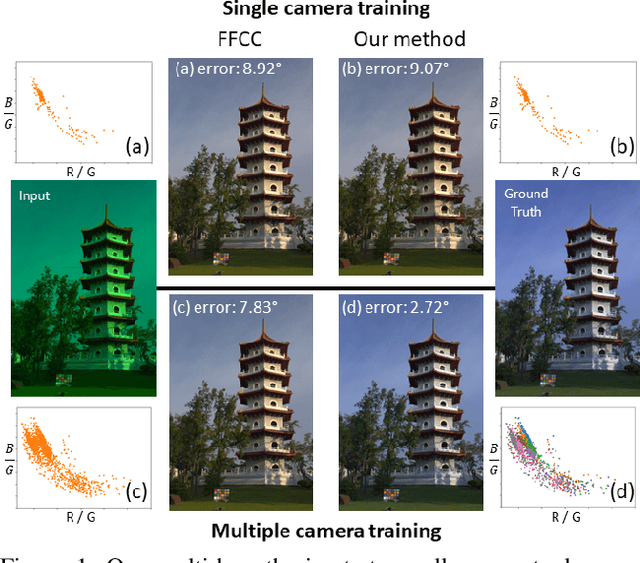
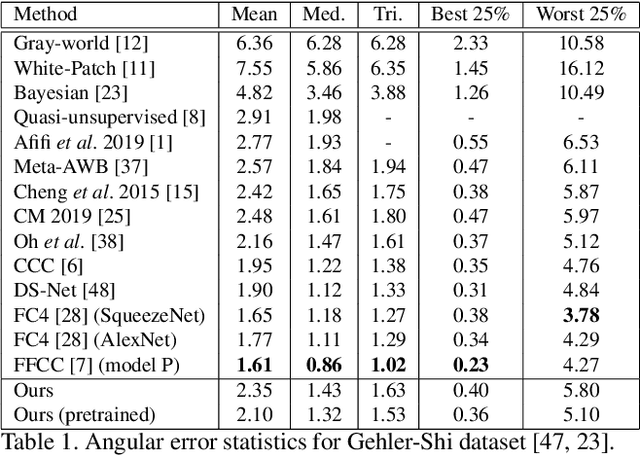
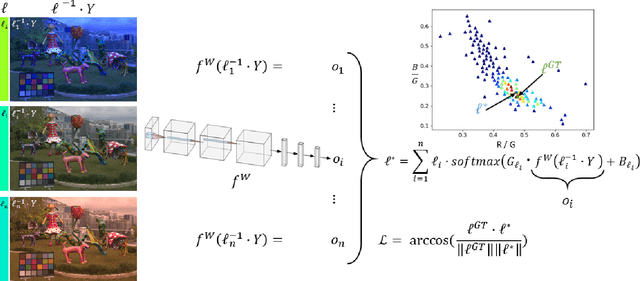
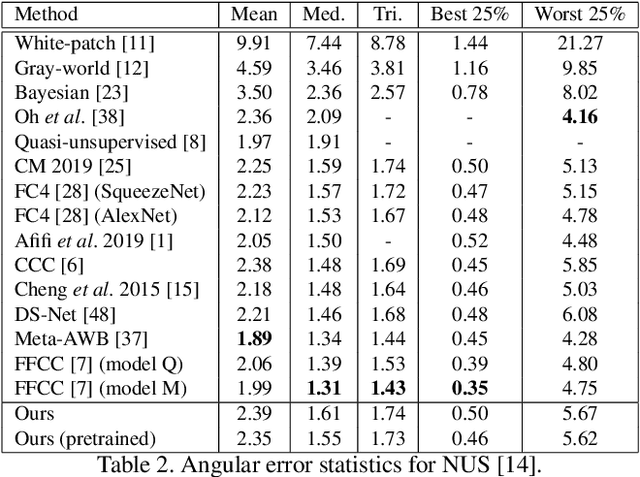
Contemporary approaches frame the color constancy problem as learning camera specific illuminant mappings. While high accuracy can be achieved on camera specific data, these models depend on camera spectral sensitivity and typically exhibit poor generalisation to new devices. Additionally, regression methods produce point estimates that do not explicitly account for potential ambiguities among plausible illuminant solutions, due to the ill-posed nature of the problem. We propose a Bayesian framework that naturally handles color constancy ambiguity via a multi-hypothesis strategy. Firstly, we select a set of candidate scene illuminants in a data-driven fashion and apply them to a target image to generate of set of corrected images. Secondly, we estimate, for each corrected image, the likelihood of the light source being achromatic using a camera-agnostic CNN. Finally, our method explicitly learns a final illumination estimate from the generated posterior probability distribution. Our likelihood estimator learns to answer a camera-agnostic question and thus enables effective multi-camera training by disentangling illuminant estimation from the supervised learning task. We extensively evaluate our proposed approach and additionally set a benchmark for novel sensor generalisation without re-training. Our method provides state-of-the-art accuracy on multiple public datasets (up to 11% median angular error improvement) while maintaining real-time execution.
EHSOD: CAM-Guided End-to-end Hybrid-Supervised Object Detection with Cascade Refinement
Feb 18, 2020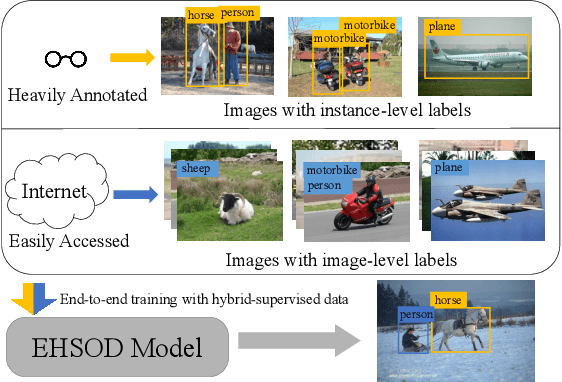
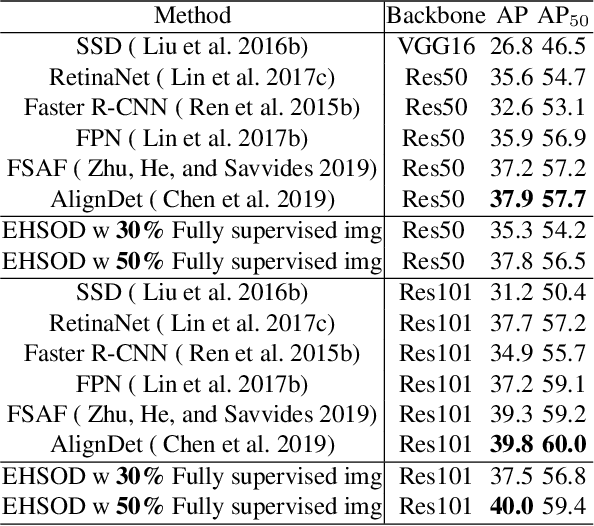
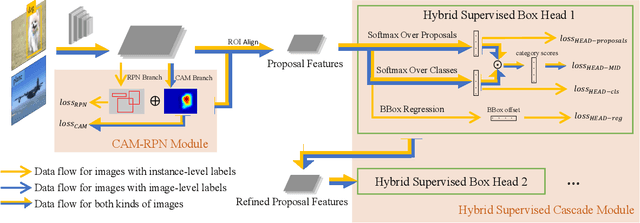
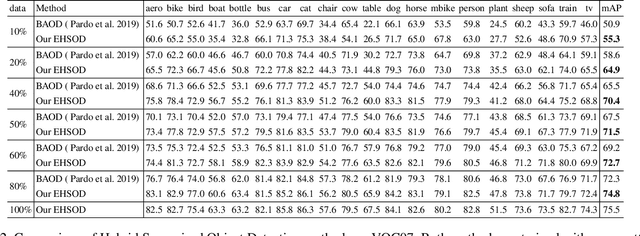
Object detectors trained on fully-annotated data currently yield state of the art performance but require expensive manual annotations. On the other hand, weakly-supervised detectors have much lower performance and cannot be used reliably in a realistic setting. In this paper, we study the hybrid-supervised object detection problem, aiming to train a high quality detector with only a limited amount of fullyannotated data and fully exploiting cheap data with imagelevel labels. State of the art methods typically propose an iterative approach, alternating between generating pseudo-labels and updating a detector. This paradigm requires careful manual hyper-parameter tuning for mining good pseudo labels at each round and is quite time-consuming. To address these issues, we present EHSOD, an end-to-end hybrid-supervised object detection system which can be trained in one shot on both fully and weakly-annotated data. Specifically, based on a two-stage detector, we proposed two modules to fully utilize the information from both kinds of labels: 1) CAMRPN module aims at finding foreground proposals guided by a class activation heat-map; 2) hybrid-supervised cascade module further refines the bounding-box position and classification with the help of an auxiliary head compatible with image-level data. Extensive experiments demonstrate the effectiveness of the proposed method and it achieves comparable results on multiple object detection benchmarks with only 30% fully-annotated data, e.g. 37.5% mAP on COCO. We will release the code and the trained models.
Continual learning: A comparative study on how to defy forgetting in classification tasks
Sep 18, 2019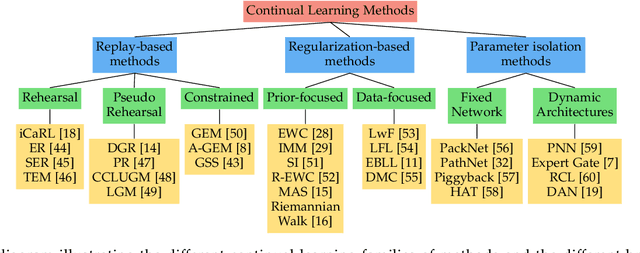


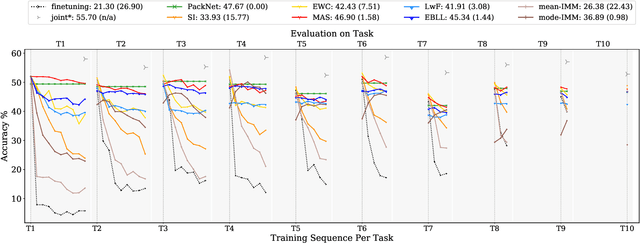
Artificial neural networks thrive in solving the classification problem for a particular rigid task, where the network resembles a static entity of knowledge, acquired through generalized learning behaviour from a distinct training phase. However, endeavours to extend this knowledge without targeting the original task usually result in a catastrophic forgetting of this task. Continual learning shifts this paradigm towards a network that can continually accumulate knowledge over different tasks without the need for retraining from scratch, with methods in particular aiming to alleviate forgetting. We focus on task-incremental classification, where tasks arrive in a batch-like fashion, and are delineated by clear boundaries. Our main contributions concern 1) a taxonomy and extensive overview of the state-of-the-art, 2) a novel framework to continually determine stability-plasticity trade-off of the continual learner, 3) a comprehensive experimental comparison of 10 state-of-the-art continual learning methods and 4 baselines. We empirically scrutinize which method performs best, both on balanced Tiny Imagenet and a large-scale unbalanced iNaturalist datasets. We study the influence of model capacity, weight decay and dropout regularization, and the order in which the tasks are presented, and qualitatively compare methods in terms of required memory, computation time and storage.
Meta-Learning for Few-shot Camera-Adaptive Color Constancy
Nov 28, 2018
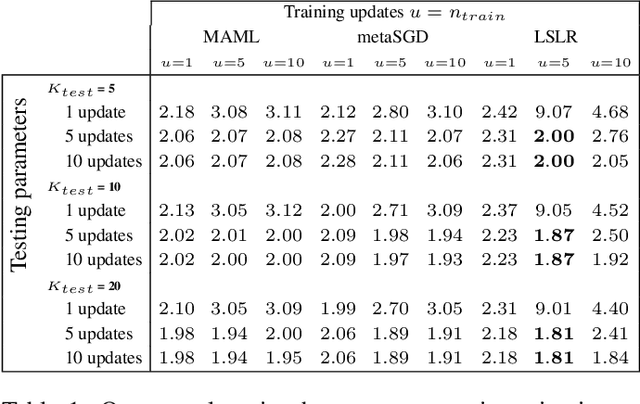
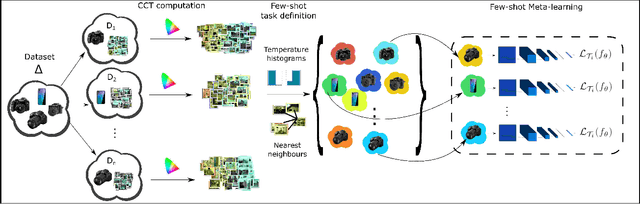
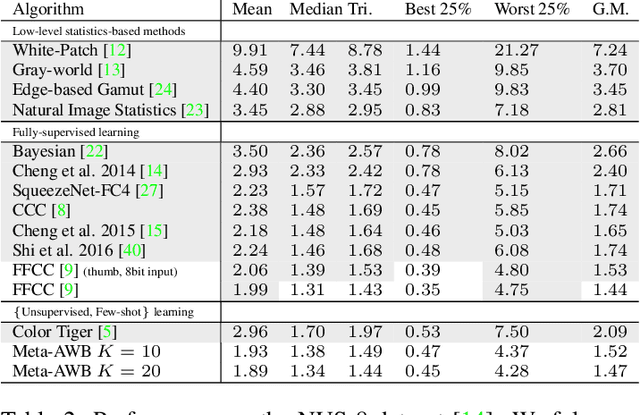
Digital camera pipelines employ color constancy methods to estimate an unknown scene illuminant, enabling the generation of canonical images under an achromatic light source. By taking advantage of large amounts of labelled images, learning-based color constancy methods provide state-of-the-art estimation accuracy. However, for a new sensor, data collection is typically arduous, as it requires both imaging physical calibration objects across different settings (such as indoor and outdoor scenes), as well as manual image annotation to produce ground truth labels. In this work, we address sensor generalisation by framing color constancy as a meta-learning problem. Using an unsupervised strategy driven by color temperature grouping, we define many related, yet distinct, illuminant estimation tasks, aggregating data from four public datasets with different camera sensors and diverse scene content. Experimental results demonstrate it is possible to produce a few-shot color constancy method competitive with the fully-supervised, camera-specific state-of-the-art.