 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructional Segment Embedding: Improving LLM Safety with Instruction Hierarchy
Oct 09, 2024



Large Language Models (LLMs) are susceptible to security and safety threats, such as prompt injection, prompt extraction, and harmful requests. One major cause of these vulnerabilities is the lack of an instruction hierarchy. Modern LLM architectures treat all inputs equally, failing to distinguish between and prioritize various types of instructions, such as system messages, user prompts, and data. As a result, lower-priority user prompts may override more critical system instructions, including safety protocols. Existing approaches to achieving instruction hierarchy, such as delimiters and instruction-based training, do not address this issue at the architectural level. We introduce the Instructional Segment Embedding (ISE) technique, inspired by BERT, to modern large language models, which embeds instruction priority information directly into the model. This approach enables models to explicitly differentiate and prioritize various instruction types, significantly improving safety against malicious prompts that attempt to override priority rules. Our experiments on the Structured Query and Instruction Hierarchy benchmarks demonstrate an average robust accuracy increase of up to 15.75% and 18.68%, respectively. Furthermore, we observe an improvement in instruction-following capability of up to 4.1% evaluated on AlpacaEval. Overall, our approach offers a promising direction for enhancing the safety and effectiveness of LLM architectures.
SFTMix: Elevating Language Model Instruction Tuning with Mixup Recipe
Oct 07, 2024



To induce desired behaviors in large language models (LLMs) for interaction-driven tasks, the instruction-tuning stage typically trains LLMs on instruction-response pairs using the next-token prediction (NTP) loss. Previous work aiming to improve instruction-tuning performance often emphasizes the need for higher-quality supervised fine-tuning (SFT) datasets, which typically involves expensive data filtering with proprietary LLMs or labor-intensive data generation by human annotators. However, these approaches do not fully leverage the datasets' intrinsic properties, resulting in high computational and labor costs, thereby limiting scalability and performance gains. In this paper, we propose SFTMix, a novel recipe that elevates instruction-tuning performance beyond the conventional NTP paradigm, without the need for well-curated datasets. Observing that LLMs exhibit uneven confidence across the semantic representation space, we argue that examples with different confidence levels should play distinct roles during the instruction-tuning process. Based on this insight, SFTMix leverages training dynamics to identify examples with varying confidence levels, then applies a Mixup-based regularization to mitigate overfitting on confident examples while propagating supervision signals to improve learning on relatively unconfident ones. This approach enables SFTMix to significantly outperform NTP across a wide range of instruction-following and healthcare domain-specific SFT tasks, demonstrating its adaptability to diverse LLM families and scalability to datasets of any size. Comprehensive ablation studies further verify the robustness of SFTMix's design choices, underscoring its versatility in consistently enhancing performance across different LLMs and datasets in broader natural language processing applications.
WPO: Enhancing RLHF with Weighted Preference Optimization
Jun 17, 2024Reinforcement learning from human feedback (RLHF) is a promising solution to align large language models (LLMs) more closely with human values. Off-policy preference optimization, where the preference data is obtained from other models, is widely adopted due to its cost efficiency and scalability. However, off-policy preference optimization often suffers from a distributional gap between the policy used for data collection and the target policy, leading to suboptimal optimization. In this paper, we propose a novel strategy to mitigate this problem by simulating on-policy learning with off-policy preference data. Our Weighted Preference Optimization (WPO) method adapts off-policy data to resemble on-policy data more closely by reweighting preference pairs according to their probability under the current policy. This method not only addresses the distributional gap problem but also enhances the optimization process without incurring additional costs. We validate our method on instruction following benchmarks including Alpaca Eval 2 and MT-bench. WPO not only outperforms Direct Preference Optimization (DPO) by up to 5.6% on Alpaca Eval 2 but also establishes a remarkable length-controlled winning rate against GPT-4-turbo of 48.6% based on Llama-3-8B-Instruct, making it the strongest 8B model on the leaderboard. We will release the code and models at https://github.com/wzhouad/WPO.
An Empirical Study on Neural Keyphrase Generation
Sep 22, 2020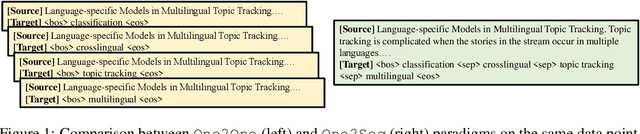
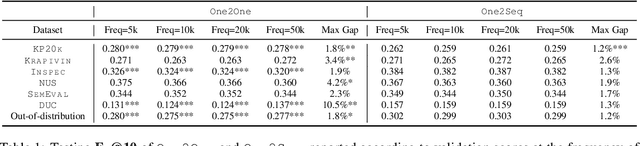
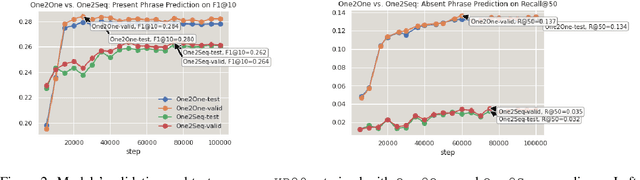
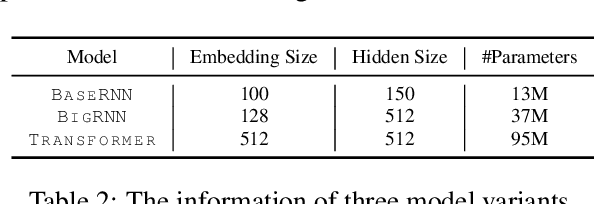
Recent years have seen a flourishing of neural keyphrase generation works, including the release of several large-scale datasets and a host of new models to tackle them. Model performance on keyphrase generation tasks has increased significantly with evolving deep learning research. However, there lacks a comprehensive comparison among models, and an investigation on related factors (e.g., architectural choice, decoding strategy) that may affect a keyphrase generation system's performance. In this empirical study, we aim to fill this gap by providing extensive experimental results and analyzing the most crucial factors impacting the performance of keyphrase generation models. We hope this study can help clarify some of the uncertainties surrounding the keyphrase generation task and facilitate future research on this topic.
Diversifying Dialogue Generation with Non-Conversational Text
May 13, 2020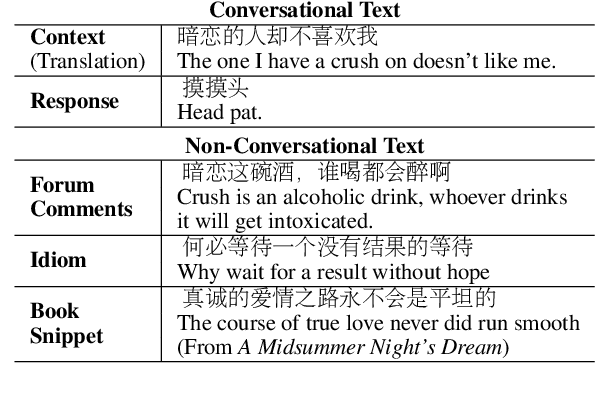
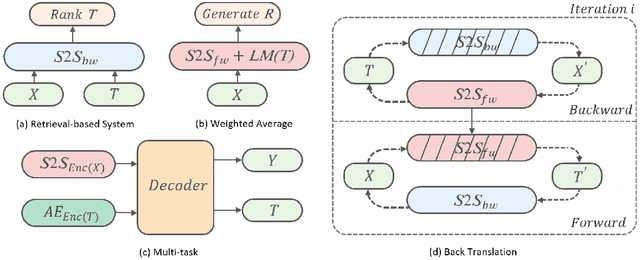
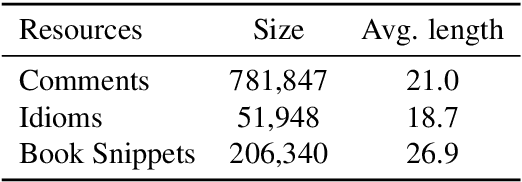
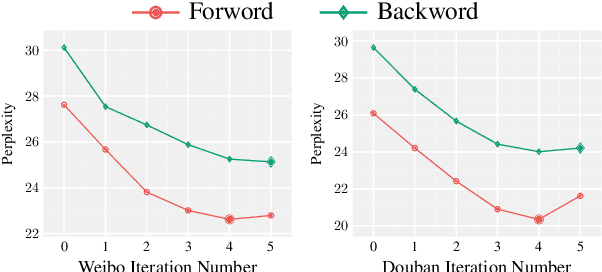
Neural network-based sequence-to-sequence (seq2seq) models strongly suffer from the low-diversity problem when it comes to open-domain dialogue generation. As bland and generic utterances usually dominate the frequency distribution in our daily chitchat, avoiding them to generate more interesting responses requires complex data filtering, sampling techniques or modifying the training objective. In this paper, we propose a new perspective to diversify dialogue generation by leveraging non-conversational text. Compared with bilateral conversations, non-conversational text are easier to obtain, more diverse and cover a much broader range of topics. We collect a large-scale non-conversational corpus from multi sources including forum comments, idioms and book snippets. We further present a training paradigm to effectively incorporate these text via iterative back translation. The resulting model is tested on two conversational datasets and is shown to produce significantly more diverse responses without sacrificing the relevance with context.
Extreme Language Model Compression with Optimal Subwords and Shared Projections
Sep 25, 2019


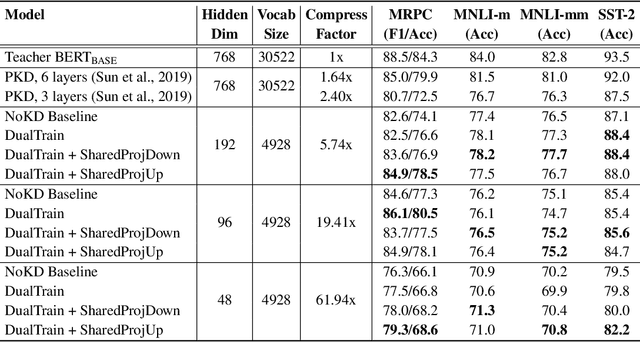
Pre-trained deep neural network language models such as ELMo, GPT, BERT and XLNet have recently achieved state-of-the-art performance on a variety of language understanding tasks. However, their size makes them impractical for a number of scenarios, especially on mobile and edge devices. In particular, the input word embedding matrix accounts for a significant proportion of the model's memory footprint, due to the large input vocabulary and embedding dimensions. Knowledge distillation techniques have had success at compressing large neural network models, but they are ineffective at yielding student models with vocabularies different from the original teacher models. We introduce a novel knowledge distillation technique for training a student model with a significantly smaller vocabulary as well as lower embedding and hidden state dimensions. Specifically, we employ a dual-training mechanism that trains the teacher and student models simultaneously to obtain optimal word embeddings for the student vocabulary. We combine this approach with learning shared projection matrices that transfer layer-wise knowledge from the teacher model to the student model. Our method is able to compress the BERT_BASE model by more than 60x, with only a minor drop in downstream task metrics, resulting in a language model with a footprint of under 7MB. Experimental results also demonstrate higher compression efficiency and accuracy when compared with other state-of-the-art compression techniques.
Informative Image Captioning with External Sources of Information
Jun 20, 2019
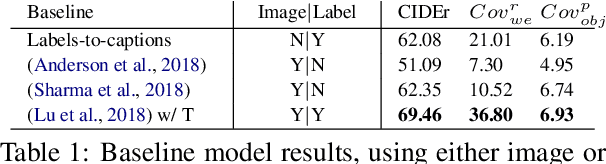
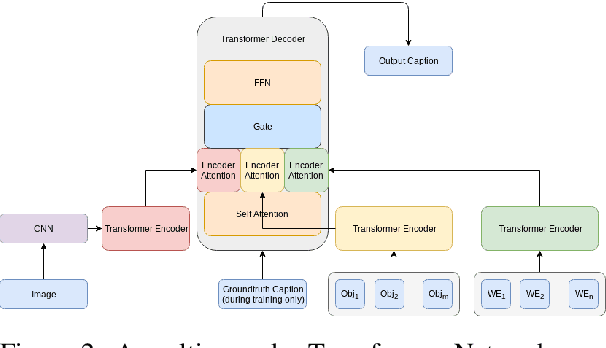
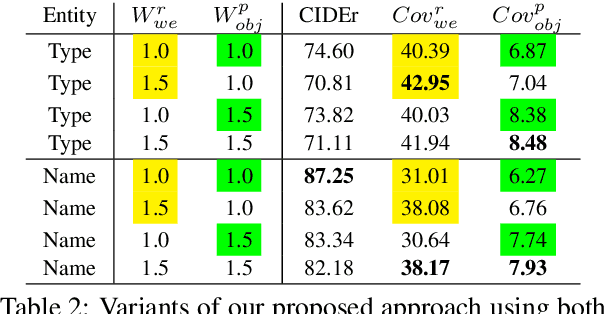
An image caption should fluently present the essential information in a given image, including informative, fine-grained entity mentions and the manner in which these entities interact. However, current captioning models are usually trained to generate captions that only contain common object names, thus falling short on an important "informativeness" dimension. We present a mechanism for integrating image information together with fine-grained labels (assumed to be generated by some upstream models) into a caption that describes the image in a fluent and informative manner. We introduce a multimodal, multi-encoder model based on Transformer that ingests both image features and multiple sources of entity labels. We demonstrate that we can learn to control the appearance of these entity labels in the output, resulting in captions that are both fluent and informative.
Integrating Transformer and Paraphrase Rules for Sentence Simplification
Oct 26, 2018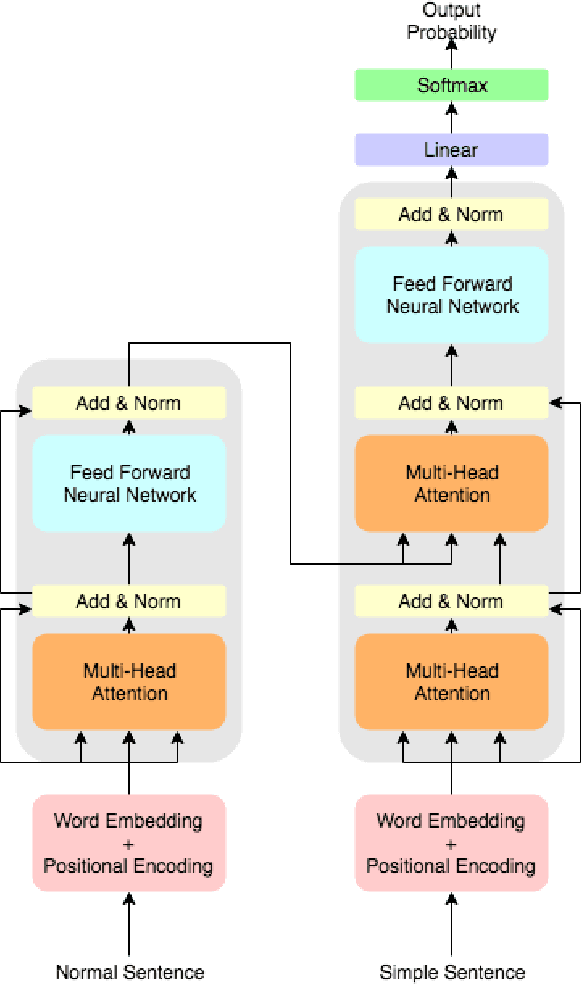
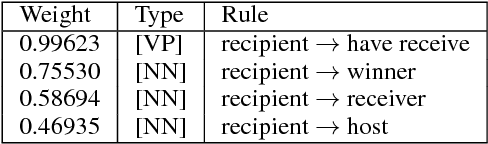
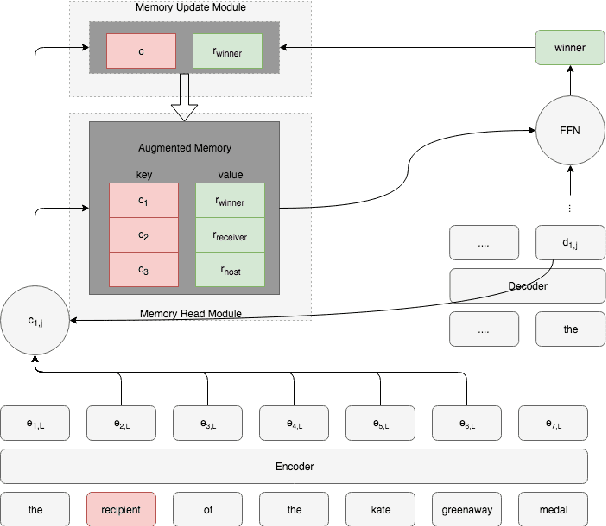
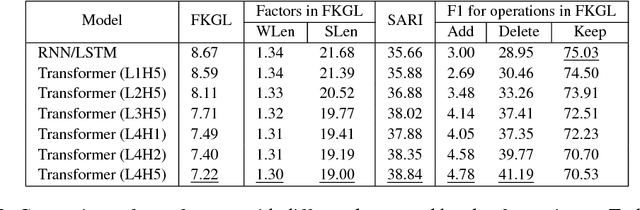
Sentence simplification aims to reduce the complexity of a sentence while retaining its original meaning. Current models for sentence simplification adopted ideas from ma- chine translation studies and implicitly learned simplification mapping rules from normal- simple sentence pairs. In this paper, we explore a novel model based on a multi-layer and multi-head attention architecture and we pro- pose two innovative approaches to integrate the Simple PPDB (A Paraphrase Database for Simplification), an external paraphrase knowledge base for simplification that covers a wide range of real-world simplification rules. The experiments show that the integration provides two major benefits: (1) the integrated model outperforms multiple state- of-the-art baseline models for sentence simplification in the literature (2) through analysis of the rule utilization, the model seeks to select more accurate simplification rules. The code and models used in the paper are available at https://github.com/ Sanqiang/text_simplification.
Deep Keyphrase Generation
Sep 18, 2018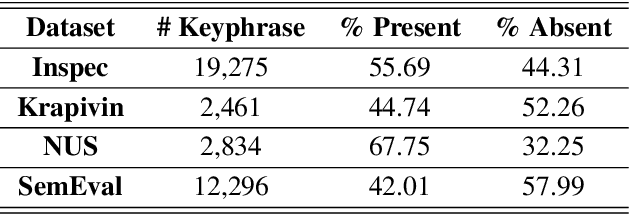

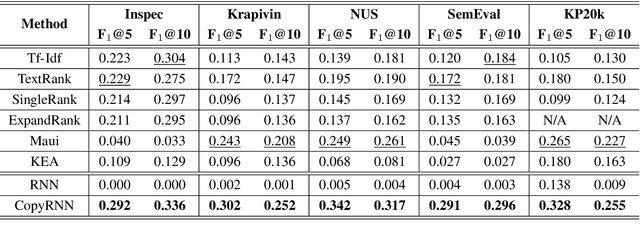
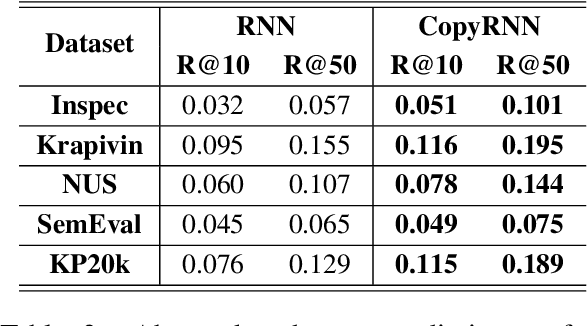
Keyphrase provides highly-summative information that can be effectively used for understanding, organizing and retrieving text content. Though previous studies have provided many workable solutions for automated keyphrase extraction, they commonly divided the to-be-summarized content into multiple text chunks, then ranked and selected the most meaningful ones. These approaches could neither identify keyphrases that do not appear in the text, nor capture the real semantic meaning behind the text. We propose a generative model for keyphrase prediction with an encoder-decoder framework, which can effectively overcome the above drawbacks. We name it as deep keyphrase generation since it attempts to capture the deep semantic meaning of the content with a deep learning method. Empirical analysis on six datasets demonstrates that our proposed model not only achieves a significant performance boost on extracting keyphrases that appear in the source text, but also can generate absent keyphrases based on the semantic meaning of the text. Code and dataset are available at https://github.com/memray/seq2seq-keyphrase.