 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Hierarchical Agglomerative Clustering to Billion-sized Datasets
May 25, 2021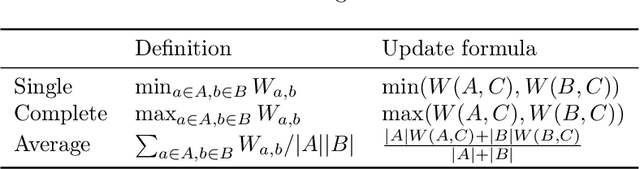
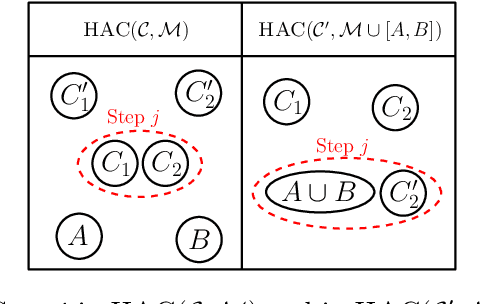

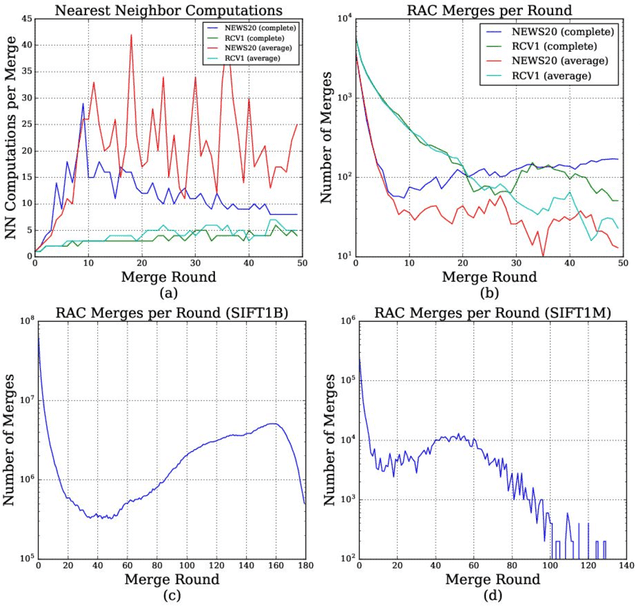
Hierarchical Agglomerative Clustering (HAC) is one of the oldest but still most widely used clustering methods. However, HAC is notoriously hard to scale to large data sets as the underlying complexity is at least quadratic in the number of data points and many algorithms to solve HAC are inherently sequential. In this paper, we propose {Reciprocal Agglomerative Clustering (RAC)}, a distributed algorithm for HAC, that uses a novel strategy to efficiently merge clusters in parallel. We prove theoretically that RAC recovers the exact solution of HAC. Furthermore, under clusterability and balancedness assumption we show provable speedups in total runtime due to the parallelism. We also show that these speedups are achievable for certain probabilistic data models. In extensive experiments, we show that this parallelism is achieved on real world data sets and that the proposed RAC algorithm can recover the HAC hierarchy on billions of data points connected by trillions of edges in less than an hour.
Balancing Robustness and Sensitivity using Feature Contrastive Learning
May 19, 2021
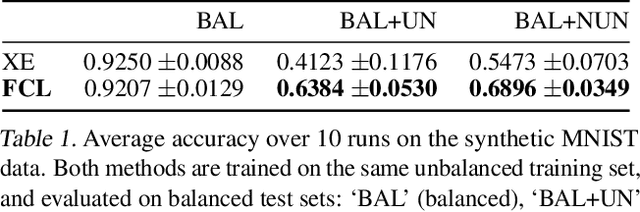
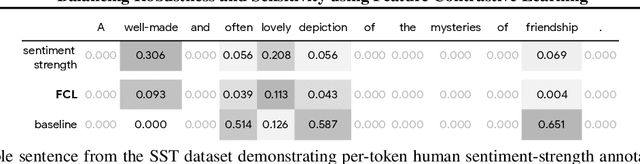
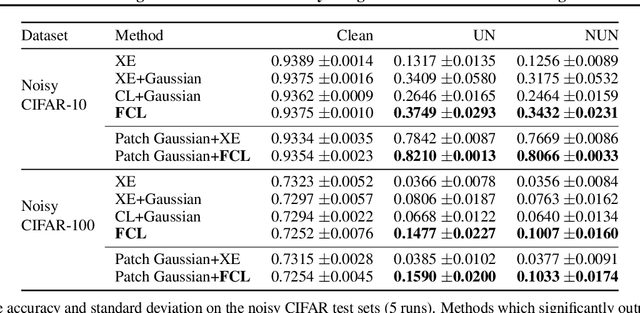
It is generally believed that robust training of extremely large networks is critical to their success in real-world applications. However, when taken to the extreme, methods that promote robustness can hurt the model's sensitivity to rare or underrepresented patterns. In this paper, we discuss this trade-off between sensitivity and robustness to natural (non-adversarial) perturbations by introducing two notions: contextual feature utility and contextual feature sensitivity. We propose Feature Contrastive Learning (FCL) that encourages a model to be more sensitive to the features that have higher contextual utility. Empirical results demonstrate that models trained with FCL achieve a better balance of robustness and sensitivity, leading to improved generalization in the presence of noise on both vision and NLP datasets.
Disentangling Sampling and Labeling Bias for Learning in Large-Output Spaces
May 12, 2021
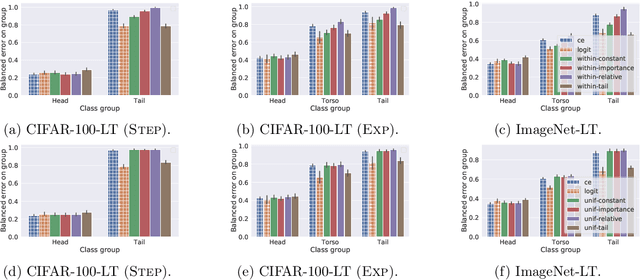

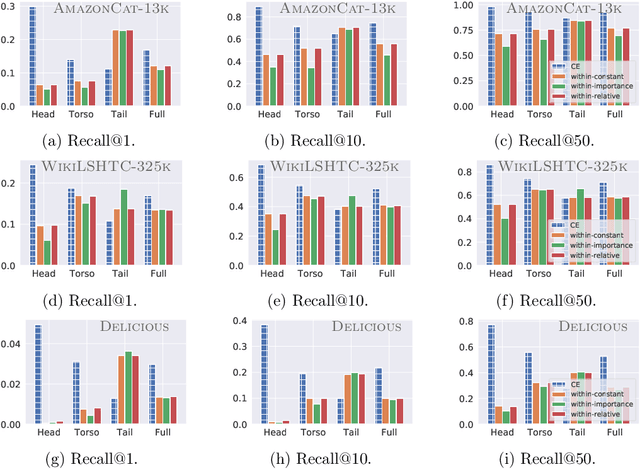
Negative sampling schemes enable efficient training given a large number of classes, by offering a means to approximate a computationally expensive loss function that takes all labels into account. In this paper, we present a new connection between these schemes and loss modification techniques for countering label imbalance. We show that different negative sampling schemes implicitly trade-off performance on dominant versus rare labels. Further, we provide a unified means to explicitly tackle both sampling bias, arising from working with a subset of all labels, and labeling bias, which is inherent to the data due to label imbalance. We empirically verify our findings on long-tail classification and retrieval benchmarks.
Balancing Constraints and Submodularity in Data Subset Selection
Apr 26, 2021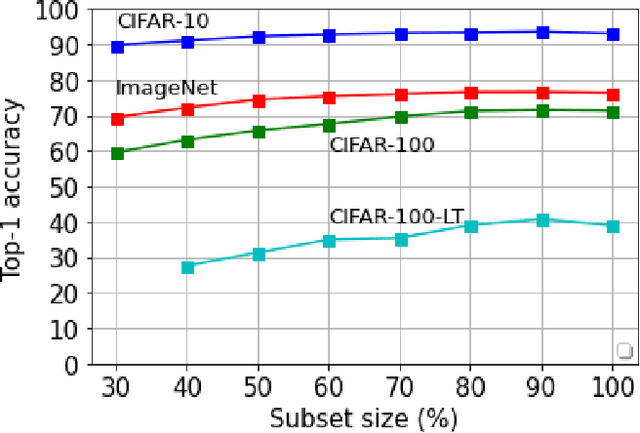
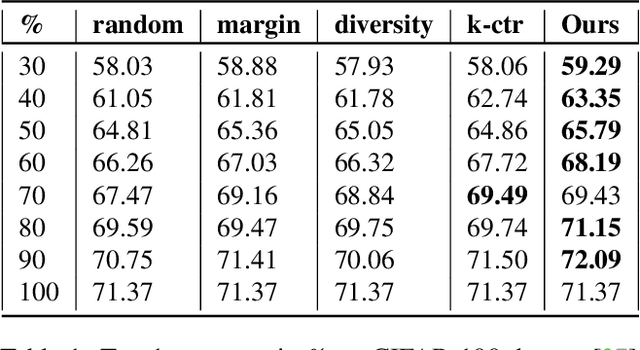
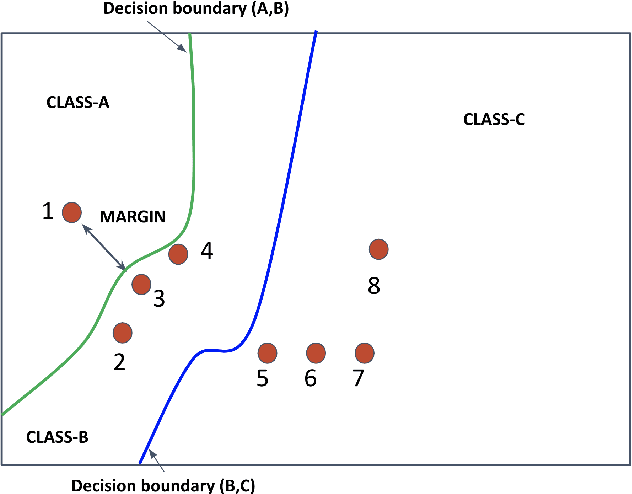
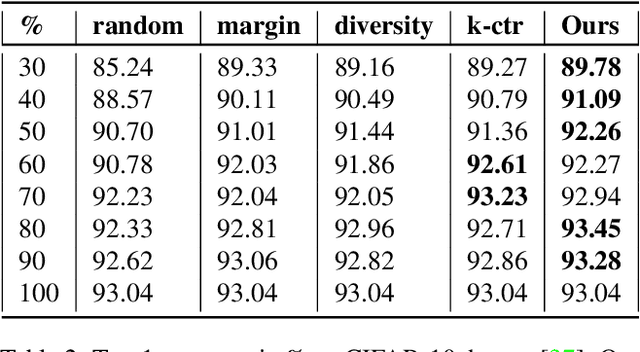
Deep learning has yielded extraordinary results in vision and natural language processing, but this achievement comes at a cost. Most deep learning models require enormous resources during training, both in terms of computation and in human labeling effort. In this paper, we show that one can achieve similar accuracy to traditional deep-learning models, while using less training data. Much of the previous work in this area relies on using uncertainty or some form of diversity to select subsets of a larger training set. Submodularity, a discrete analogue of convexity, has been exploited to model diversity in various settings including data subset selection. In contrast to prior methods, we propose a novel diversity driven objective function, and balancing constraints on class labels and decision boundaries using matroids. This allows us to use efficient greedy algorithms with approximation guarantees for subset selection. We outperform baselines on standard image classification datasets such as CIFAR-10, CIFAR-100, and ImageNet. In addition, we also show that the proposed balancing constraints can play a key role in boosting the performance in long-tailed datasets such as CIFAR-100-LT.
On the Reproducibility of Neural Network Predictions
Feb 05, 2021

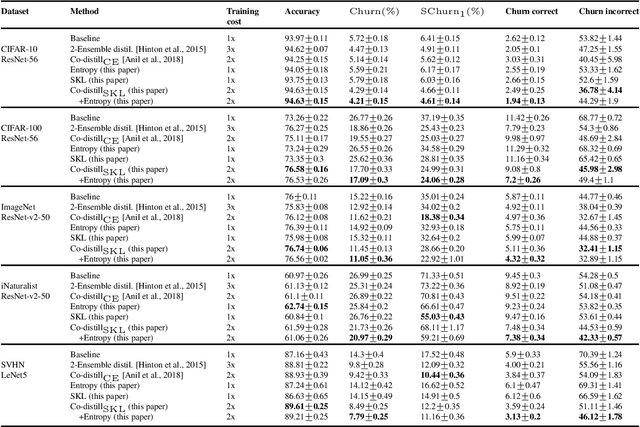
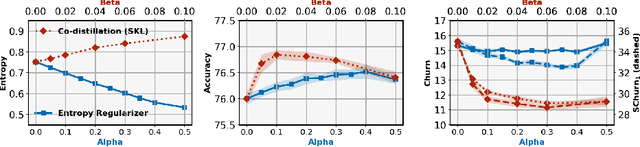
Standard training techniques for neural networks involve multiple sources of randomness, e.g., initialization, mini-batch ordering and in some cases data augmentation. Given that neural networks are heavily over-parameterized in practice, such randomness can cause {\em churn} -- for the same input, disagreements between predictions of the two models independently trained by the same algorithm, contributing to the `reproducibility challenges' in modern machine learning. In this paper, we study this problem of churn, identify factors that cause it, and propose two simple means of mitigating it. We first demonstrate that churn is indeed an issue, even for standard image classification tasks (CIFAR and ImageNet), and study the role of the different sources of training randomness that cause churn. By analyzing the relationship between churn and prediction confidences, we pursue an approach with two components for churn reduction. First, we propose using \emph{minimum entropy regularizers} to increase prediction confidences. Second, \changes{we present a novel variant of co-distillation approach~\citep{anil2018large} to increase model agreement and reduce churn}. We present empirical results showing the effectiveness of both techniques in reducing churn while improving the accuracy of the underlying model.
Kernelized Classification in Deep Networks
Dec 08, 2020

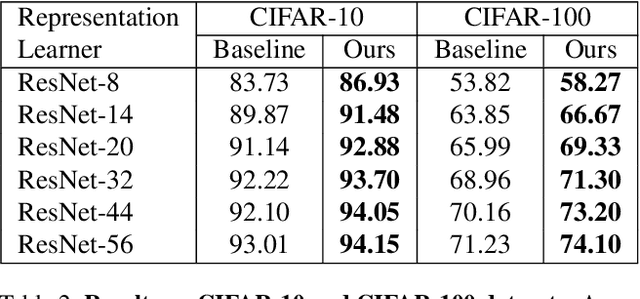
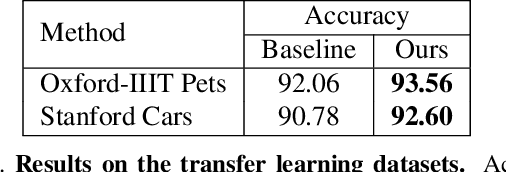
In this paper, we propose a kernelized classification layer for deep networks. Although conventional deep networks introduce an abundance of nonlinearity for representation (feature) learning, they almost universally use a linear classifier on the learned feature vectors. We introduce a nonlinear classification layer by using the kernel trick on the softmax cross-entropy loss function during training and the scorer function during testing. Furthermore, we study the choice of kernel functions one could use with this framework and show that the optimal kernel function for a given problem can be learned automatically within the deep network itself using the usual backpropagation and gradient descent methods. To this end, we exploit a classic mathematical result on the positive definite kernels on the unit n-sphere embedded in the (n+1)-dimensional Euclidean space. We show the usefulness of the proposed nonlinear classification layer on several vision datasets and tasks.
Modifying Memories in Transformer Models
Dec 01, 2020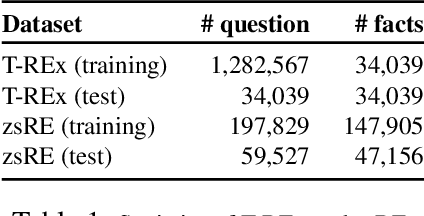

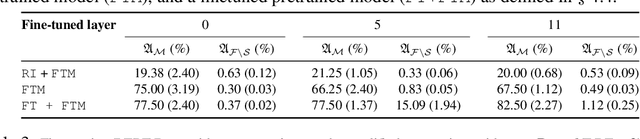
Large Transformer models have achieved impressive performance in many natural language tasks. In particular, Transformer based language models have been shown to have great capabilities in encoding factual knowledge in their vast amount of parameters. While the tasks of improving the memorization and generalization of Transformers have been widely studied, it is not well known how to make transformers forget specific old facts and memorize new ones. In this paper, we propose a new task of \emph{explicitly modifying specific factual knowledge in Transformer models while ensuring the model performance does not degrade on the unmodified facts}. This task is useful in many scenarios, such as updating stale knowledge, protecting privacy, and eliminating unintended biases stored in the models. We benchmarked several approaches that provide natural baseline performances on this task. This leads to the discovery of key components of a Transformer model that are especially effective for knowledge modifications. The work also provides insights into the role that different training phases (such as pretraining and fine-tuning) play towards memorization and knowledge modification.
Coping with Label Shift via Distributionally Robust Optimisation
Oct 23, 2020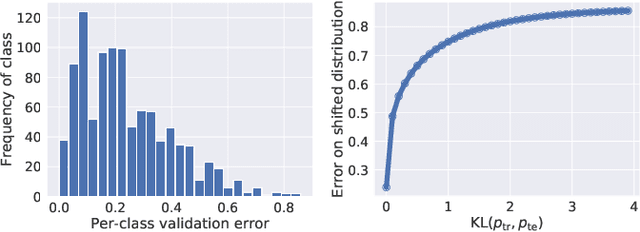

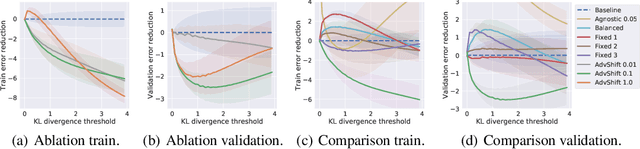
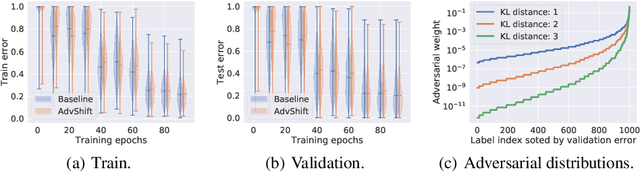
The label shift problem refers to the supervised learning setting where the train and test label distributions do not match. Existing work addressing label shift usually assumes access to an \emph{unlabelled} test sample. This sample may be used to estimate the test label distribution, and to then train a suitably re-weighted classifier. While approaches using this idea have proven effective, their scope is limited as it is not always feasible to access the target domain; further, they require repeated retraining if the model is to be deployed in \emph{multiple} test environments. Can one instead learn a \emph{single} classifier that is robust to arbitrary label shifts from a broad family? In this paper, we answer this question by proposing a model that minimises an objective based on distributionally robust optimisation (DRO). We then design and analyse a gradient descent-proximal mirror ascent algorithm tailored for large-scale problems to optimise the proposed objective. %, and establish its convergence. Finally, through experiments on CIFAR-100 and ImageNet, we show that our technique can significantly improve performance over a number of baselines in settings where label shift is present.
Semantic Label Smoothing for Sequence to Sequence Problems
Oct 15, 2020
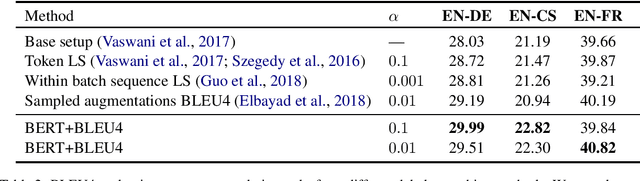

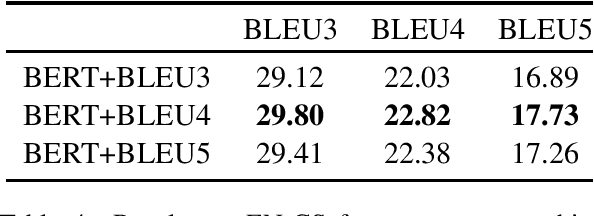
Label smoothing has been shown to be an effective regularization strategy in classification, that prevents overfitting and helps in label de-noising. However, extending such methods directly to seq2seq settings, such as Machine Translation, is challenging: the large target output space of such problems makes it intractable to apply label smoothing over all possible outputs. Most existing approaches for seq2seq settings either do token level smoothing, or smooth over sequences generated by randomly substituting tokens in the target sequence. Unlike these works, in this paper, we propose a technique that smooths over \emph{well formed} relevant sequences that not only have sufficient n-gram overlap with the target sequence, but are also \emph{semantically similar}. Our method shows a consistent and significant improvement over the state-of-the-art techniques on different datasets.
Learning discrete distributions: user vs item-level privacy
Jul 28, 2020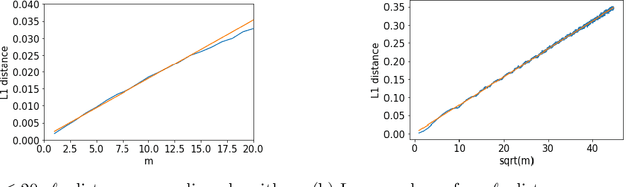
Much of the literature on differential privacy focuses on item-level privacy, where loosely speaking, the goal is to provide privacy per item or training example. However, recently many practical applications such as federated learning require preserving privacy for all items of a single user, which is much harder to achieve. Therefore understanding the theoretical limit of user-level privacy becomes crucial. We study the fundamental problem of learning discrete distributions over $k$ symbols with user-level differential privacy. If each user has $m$ samples, we show that straightforward applications of Laplace or Gaussian mechanisms require the number of users to be $\mathcal{O}(k/(m\alpha^2) + k/\epsilon\alpha)$ to achieve an $\ell_1$ distance of $\alpha$ between the true and estimated distributions, with the privacy-induced penalty $k/\epsilon\alpha$ independent of the number of samples per user $m$. Moreover, we show that any mechanism that only operates on the final aggregate should require a user complexity of the same order. We then propose a mechanism such that the number of users scales as $\tilde{\mathcal{O}}(k/(m\alpha^2) + k/\sqrt{m}\epsilon\alpha)$ and further show that it is nearly-optimal under certain regimes. Thus the privacy penalty is $\mathcal{O}(\sqrt{m})$ times smaller compared to the standard mechanisms. We also propose general techniques for obtaining lower bounds on restricted differentially private estimators and a lower bound on the total variation between binomial distributions, both of which might be of independent interest.