 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher Guided Training: An Efficient Framework for Knowledge Transfer
Aug 14, 2022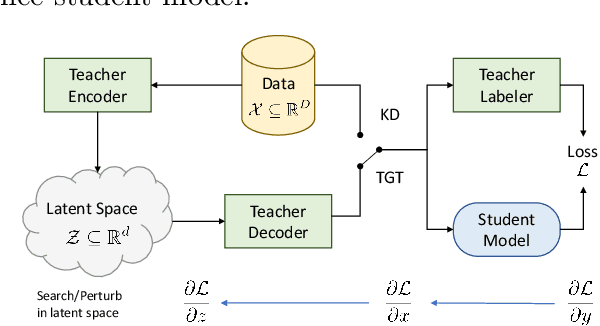
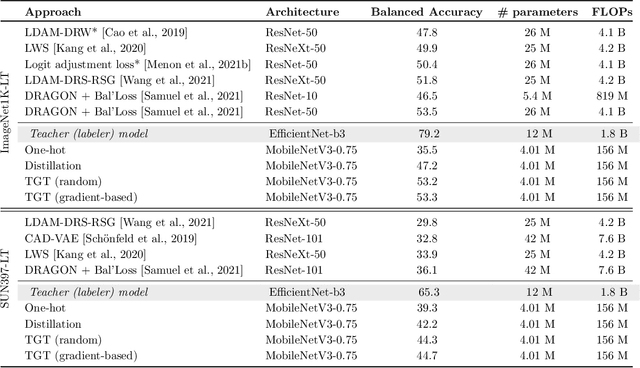
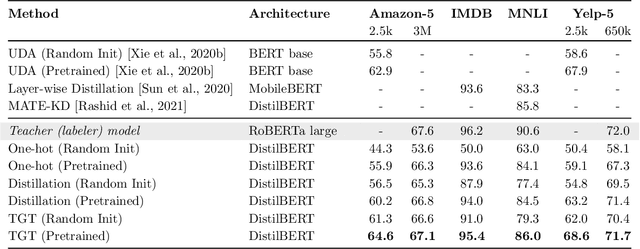
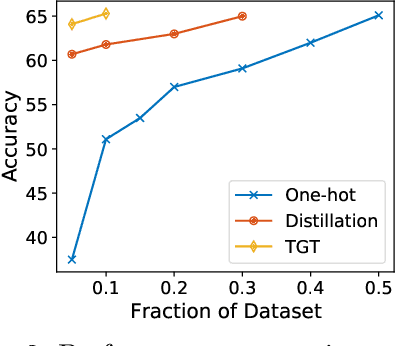
The remarkable performance gains realized by large pretrained models, e.g., GPT-3, hinge on the massive amounts of data they are exposed to during training. Analogously, distilling such large models to compact models for efficient deployment also necessitates a large amount of (labeled or unlabeled) training data. In this paper, we propose the teacher-guided training (TGT) framework for training a high-quality compact model that leverages the knowledge acquired by pretrained generative models, while obviating the need to go through a large volume of data. TGT exploits the fact that the teacher has acquired a good representation of the underlying data domain, which typically corresponds to a much lower dimensional manifold than the input space. Furthermore, we can use the teacher to explore input space more efficiently through sampling or gradient-based methods; thus, making TGT especially attractive for limited data or long-tail settings. We formally capture this benefit of proposed data-domain exploration in our generalization bounds. We find that TGT can improve accuracy on several image classification benchmarks as well as a range of text classification and retrieval tasks.
TPU-KNN: K Nearest Neighbor Search at Peak FLOP/s
Jun 30, 2022
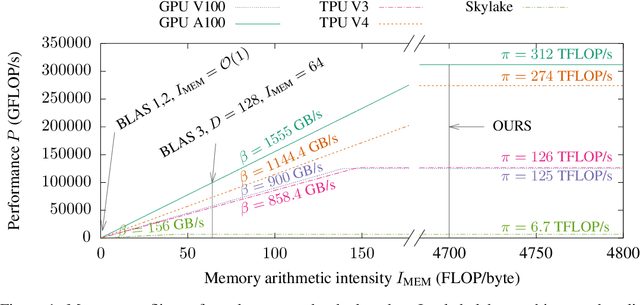
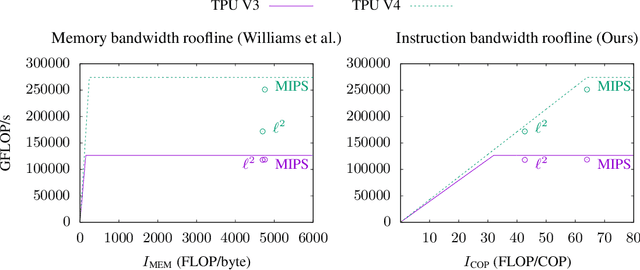
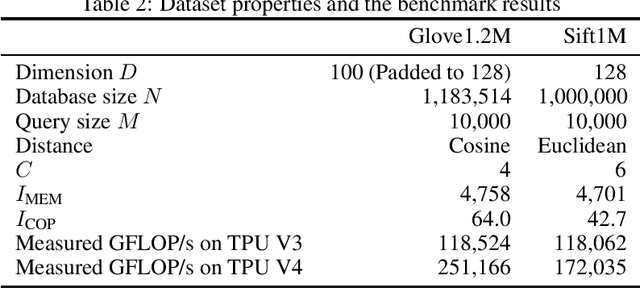
This paper presents a novel nearest neighbor search algorithm achieving TPU (Google Tensor Processing Unit) peak performance, outperforming state-of-the-art GPU algorithms with similar level of recall. The design of the proposed algorithm is motivated by an accurate accelerator performance model that takes into account both the memory and instruction bottlenecks. Our algorithm comes with an analytical guarantee of recall in expectation and does not require maintaining sophisticated index data structure or tuning, making it suitable for applications with frequent updates. Our work is available in the open-source package of Jax and Tensorflow on TPU.
ELM: Embedding and Logit Margins for Long-Tail Learning
Apr 27, 2022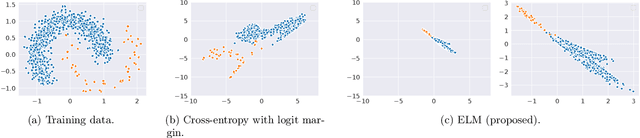
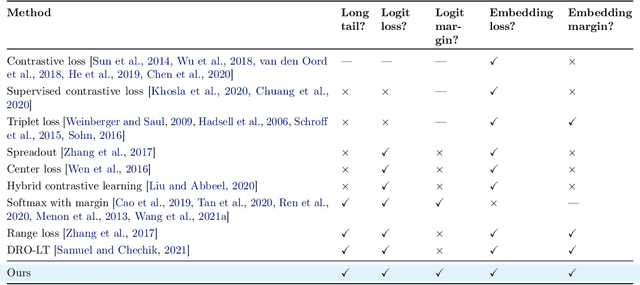
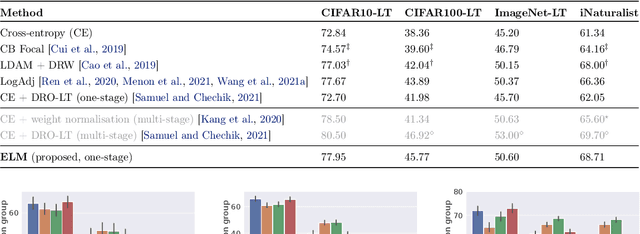
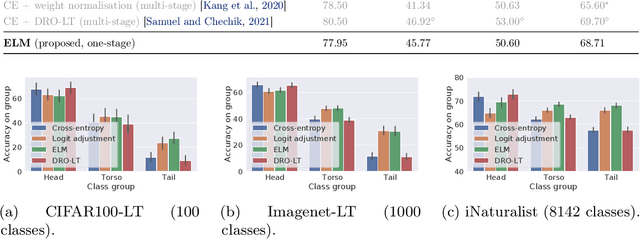
Long-tail learning is the problem of learning under skewed label distributions, which pose a challenge for standard learners. Several recent approaches for the problem have proposed enforcing a suitable margin in logit space. Such techniques are intuitive analogues of the guiding principle behind SVMs, and are equally applicable to linear models and neural models. However, when applied to neural models, such techniques do not explicitly control the geometry of the learned embeddings. This can be potentially sub-optimal, since embeddings for tail classes may be diffuse, resulting in poor generalization for these classes. We present Embedding and Logit Margins (ELM), a unified approach to enforce margins in logit space, and regularize the distribution of embeddings. This connects losses for long-tail learning to proposals in the literature on metric embedding, and contrastive learning. We theoretically show that minimising the proposed ELM objective helps reduce the generalisation gap. The ELM method is shown to perform well empirically, and results in tighter tail class embeddings.
Predicting on the Edge: Identifying Where a Larger Model Does Better
Feb 15, 2022Much effort has been devoted to making large and more accurate models, but relatively little has been put into understanding which examples are benefiting from the added complexity. In this paper, we demonstrate and analyze the surprisingly tight link between a model's predictive uncertainty on individual examples and the likelihood that larger models will improve prediction on them. Through extensive numerical studies on the T5 encoder-decoder architecture, we show that large models have the largest improvement on examples where the small model is most uncertain. On more certain examples, even those where the small model is not particularly accurate, large models are often unable to improve at all, and can even perform worse than the smaller model. Based on these findings, we show that a switcher model which defers examples to a larger model when a small model is uncertain can achieve striking improvements in performance and resource usage. We also explore committee-based uncertainty metrics that can be more effective but less practical.
Robust Training of Neural Networks using Scale Invariant Architectures
Feb 02, 2022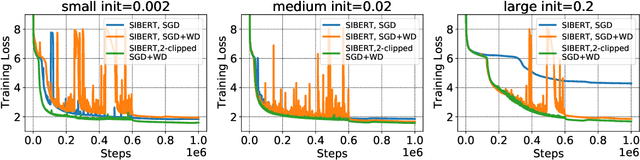
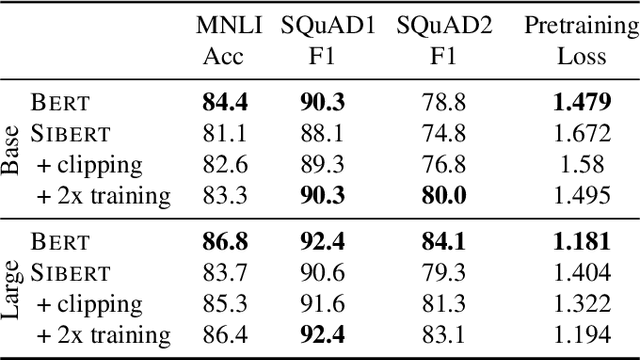
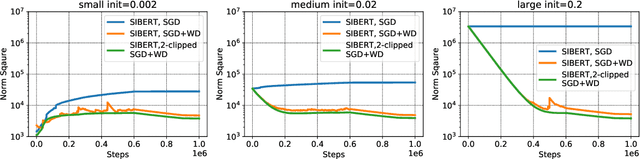

In contrast to SGD, adaptive gradient methods like Adam allow robust training of modern deep networks, especially large language models. However, the use of adaptivity not only comes at the cost of extra memory but also raises the fundamental question: can non-adaptive methods like SGD enjoy similar benefits? In this paper, we provide an affirmative answer to this question by proposing to achieve both robust and memory-efficient training via the following general recipe: (1) modify the architecture and make it scale invariant, i.e. the scale of parameter doesn't affect the output of the network, (2) train with SGD and weight decay, and optionally (3) clip the global gradient norm proportional to weight norm multiplied by $\sqrt{\tfrac{2\lambda}{\eta}}$, where $\eta$ is learning rate and $\lambda$ is weight decay. We show that this general approach is robust to rescaling of parameter and loss by proving that its convergence only depends logarithmically on the scale of initialization and loss, whereas the standard SGD might not even converge for many initializations. Following our recipe, we design a scale invariant version of BERT, called SIBERT, which when trained simply by vanilla SGD achieves performance comparable to BERT trained by adaptive methods like Adam on downstream tasks.
When in Doubt, Summon the Titans: Efficient Inference with Large Models
Oct 19, 2021
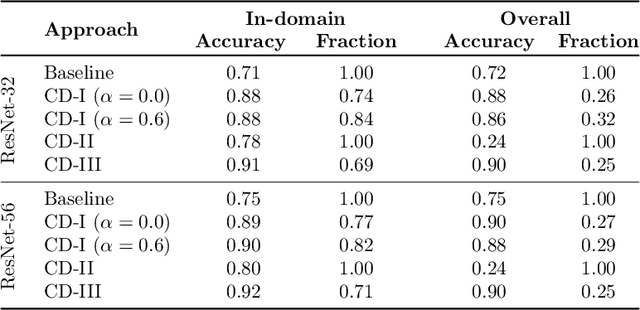
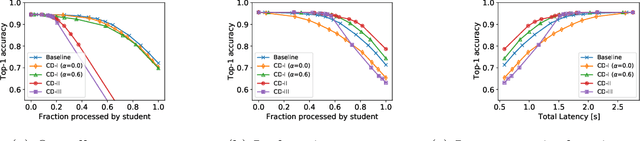
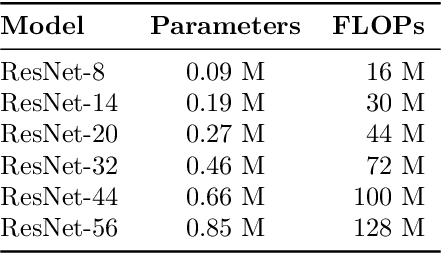
Scaling neural networks to "large" sizes, with billions of parameters, has been shown to yield impressive results on many challenging problems. However, the inference cost incurred by such large models often prevents their application in most real-world settings. In this paper, we propose a two-stage framework based on distillation that realizes the modelling benefits of the large models, while largely preserving the computational benefits of inference with more lightweight models. In a nutshell, we use the large teacher models to guide the lightweight student models to only make correct predictions on a subset of "easy" examples; for the "hard" examples, we fall-back to the teacher. Such an approach allows us to efficiently employ large models in practical scenarios where easy examples are much more frequent than rare hard examples. Our proposed use of distillation to only handle easy instances allows for a more aggressive trade-off in the student size, thereby reducing the amortized cost of inference and achieving better accuracy than standard distillation. Empirically, we demonstrate the benefits of our approach on both image classification and natural language processing benchmarks.
Leveraging redundancy in attention with Reuse Transformers
Oct 13, 2021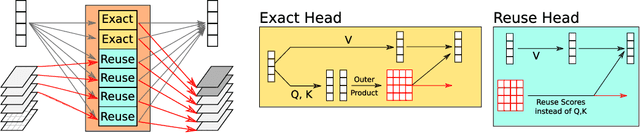
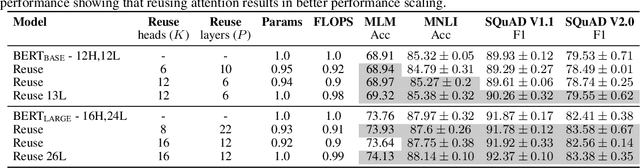
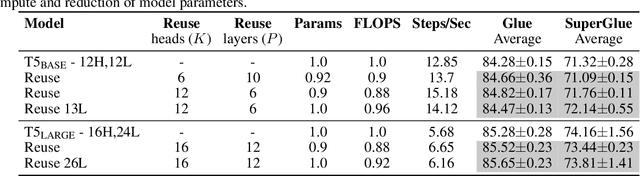
Pairwise dot product-based attention allows Transformers to exchange information between tokens in an input-dependent way, and is key to their success across diverse applications in language and vision. However, a typical Transformer model computes such pairwise attention scores repeatedly for the same sequence, in multiple heads in multiple layers. We systematically analyze the empirical similarity of these scores across heads and layers and find them to be considerably redundant, especially adjacent layers showing high similarity. Motivated by these findings, we propose a novel architecture that reuses attention scores computed in one layer in multiple subsequent layers. Experiments on a number of standard benchmarks show that reusing attention delivers performance equivalent to or better than standard transformers, while reducing both compute and memory usage.
Batch Active Learning at Scale
Jul 29, 2021
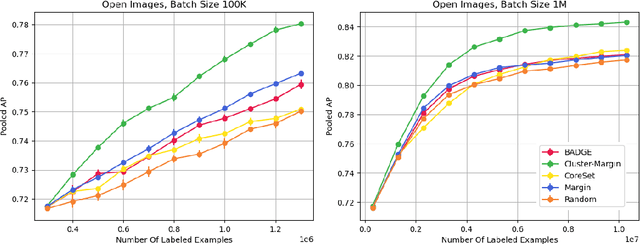
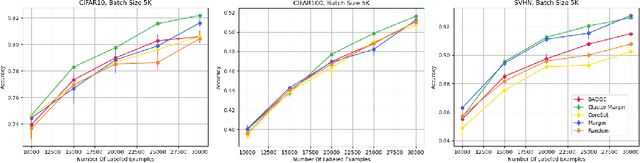
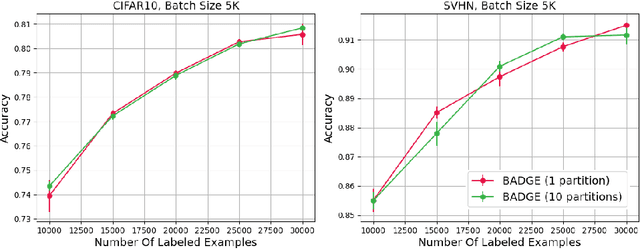
The ability to train complex and highly effective models often requires an abundance of training data, which can easily become a bottleneck in cost, time, and computational resources. Batch active learning, which adaptively issues batched queries to a labeling oracle, is a common approach for addressing this problem. The practical benefits of batch sampling come with the downside of less adaptivity and the risk of sampling redundant examples within a batch -- a risk that grows with the batch size. In this work, we analyze an efficient active learning algorithm, which focuses on the large batch setting. In particular, we show that our sampling method, which combines notions of uncertainty and diversity, easily scales to batch sizes (100K-1M) several orders of magnitude larger than used in previous studies and provides significant improvements in model training efficiency compared to recent baselines. Finally, we provide an initial theoretical analysis, proving label complexity guarantees for a related sampling method, which we show is approximately equivalent to our sampling method in specific settings.
Teacher's pet: understanding and mitigating biases in distillation
Jul 08, 2021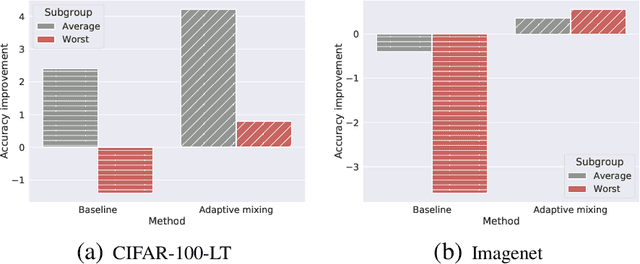

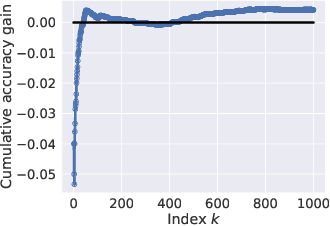
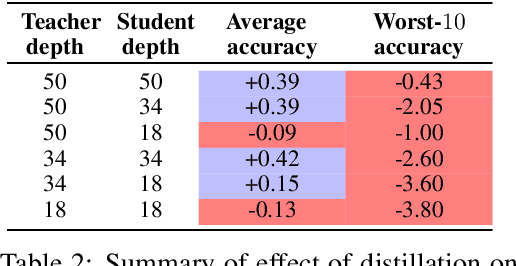
Knowledge distillation is widely used as a means of improving the performance of a relatively simple student model using the predictions from a complex teacher model. Several works have shown that distillation significantly boosts the student's overall performance; however, are these gains uniform across all data subgroups? In this paper, we show that distillation can harm performance on certain subgroups, e.g., classes with few associated samples. We trace this behaviour to errors made by the teacher distribution being transferred to and amplified by the student model. To mitigate this problem, we present techniques which soften the teacher influence for subgroups where it is less reliable. Experiments on several image classification benchmarks show that these modifications of distillation maintain boost in overall accuracy, while additionally ensuring improvement in subgroup performance.
Eigen Analysis of Self-Attention and its Reconstruction from Partial Computation
Jun 16, 2021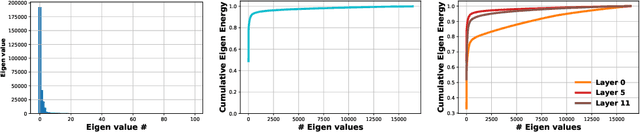
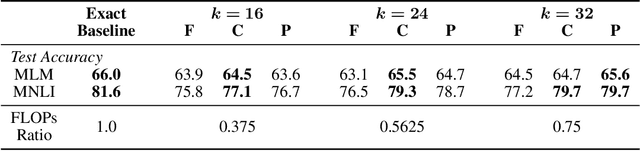
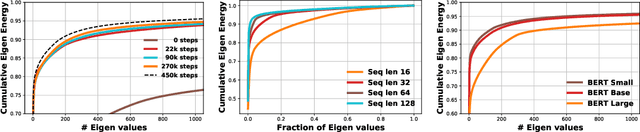
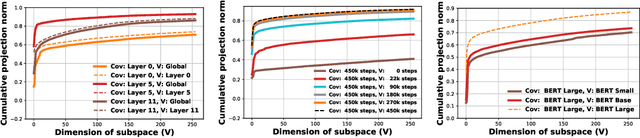
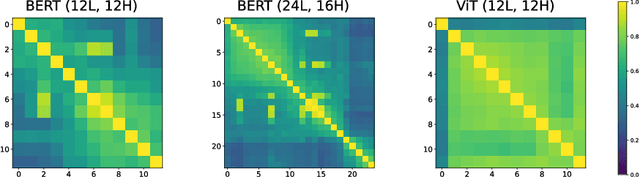
State-of-the-art transformer models use pairwise dot-product based self-attention, which comes at a computational cost quadratic in the input sequence length. In this paper, we investigate the global structure of attention scores computed using this dot product mechanism on a typical distribution of inputs, and study the principal components of their variation. Through eigen analysis of full attention score matrices, as well as of their individual rows, we find that most of the variation among attention scores lie in a low-dimensional eigenspace. Moreover, we find significant overlap between these eigenspaces for different layers and even different transformer models. Based on this, we propose to compute scores only for a partial subset of token pairs, and use them to estimate scores for the remaining pairs. Beyond investigating the accuracy of reconstructing attention scores themselves, we investigate training transformer models that employ these approximations, and analyze the effect on overall accuracy. Our analysis and the proposed method provide insights into how to balance the benefits of exact pair-wise attention and its significant computational expense.