 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenVC: Self-Supervised Zero-Shot Voice Conversion
Feb 06, 2025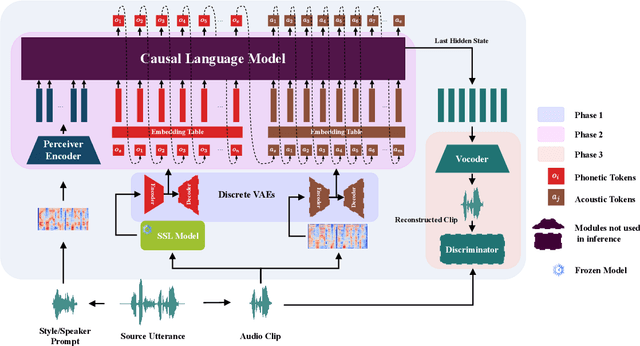
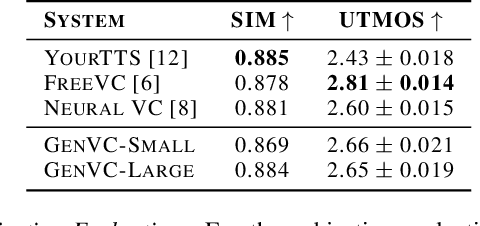
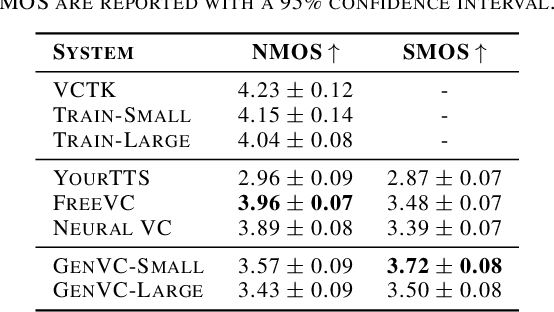
Zero-shot voice conversion has recently made substantial progress, but many models still depend on external supervised systems to disentangle speaker identity and linguistic content. Furthermore, current methods often use parallel conversion, where the converted speech inherits the source utterance's temporal structure, restricting speaker similarity and privacy. To overcome these limitations, we introduce GenVC, a generative zero-shot voice conversion model. GenVC learns to disentangle linguistic content and speaker style in a self-supervised manner, eliminating the need for external models and enabling efficient training on large, unlabeled datasets. Experimental results show that GenVC achieves state-of-the-art speaker similarity while maintaining naturalness competitive with leading approaches. Its autoregressive generation also allows the converted speech to deviate from the source utterance's temporal structure. This feature makes GenVC highly effective for voice anonymization, as it minimizes the preservation of source prosody and speaker characteristics, enhancing privacy protection.
DiCoW: Diarization-Conditioned Whisper for Target Speaker Automatic Speech Recognition
Dec 30, 2024



Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a significant challenge, particularly when systems conditioned on speaker embeddings fail to generalize to unseen speakers. In this work, we propose Diarization-Conditioned Whisper (DiCoW), a novel approach to target-speaker ASR that leverages speaker diarization outputs as conditioning information. DiCoW extends the pre-trained Whisper model by integrating diarization labels directly, eliminating reliance on speaker embeddings and reducing the need for extensive speaker-specific training data. Our method introduces frame-level diarization-dependent transformations (FDDT) and query-key biasing (QKb) techniques to refine the model's focus on target speakers while effectively handling overlapping speech. By leveraging diarization outputs as conditioning signals, DiCoW simplifies the workflow for multi-speaker ASR, improves generalization to unseen speakers and enables more reliable transcription in real-world multi-speaker recordings. Additionally, we explore the integration of a connectionist temporal classification (CTC) head to Whisper and demonstrate its ability to improve transcription efficiency through hybrid decoding. Notably, we show that our approach is not limited to Whisper; it also provides similar benefits when applied to the Branchformer model. We validate DiCoW on real-world datasets, including AMI and NOTSOFAR-1 from CHiME-8 challenge, as well as synthetic benchmarks such as Libri2Mix and LibriCSS, enabling direct comparisons with previous methods. Results demonstrate that DiCoW enhances the model's target-speaker ASR capabilities while maintaining Whisper's accuracy and robustness on single-speaker data.
HLTCOE JHU Submission to the Voice Privacy Challenge 2024
Sep 17, 2024



We present a number of systems for the Voice Privacy Challenge, including voice conversion based systems such as the kNN-VC method and the WavLM voice Conversion method, and text-to-speech (TTS) based systems including Whisper-VITS. We found that while voice conversion systems better preserve emotional content, they struggle to conceal speaker identity in semi-white-box attack scenarios; conversely, TTS methods perform better at anonymization and worse at emotion preservation. Finally, we propose a random admixture system which seeks to balance out the strengths and weaknesses of the two category of systems, achieving a strong EER of over 40% while maintaining UAR at a respectable 47%.
Target Speaker ASR with Whisper
Sep 14, 2024



We propose a novel approach to enable the use of large, single speaker ASR models, such as Whisper, for target speaker ASR. The key insight of this method is that it is much easier to model relative differences among speakers by learning to condition on frame-level diarization outputs, than to learn the space of all speaker embeddings. We find that adding even a single bias term per diarization output type before the first transformer block can transform single speaker ASR models, into target speaker ASR models. Our target-speaker ASR model can be used for speaker attributed ASR by producing, in sequence, a transcript for each hypothesized speaker in a diarization output. This simplified model for speaker attributed ASR using only a single microphone outperforms cascades of speech separation and diarization by 11% absolute ORC-WER on the NOTSOFAR-1 dataset.
Clean Label Attacks against SLU Systems
Sep 13, 2024



Poisoning backdoor attacks involve an adversary manipulating the training data to induce certain behaviors in the victim model by inserting a trigger in the signal at inference time. We adapted clean label backdoor (CLBD)-data poisoning attacks, which do not modify the training labels, on state-of-the-art speech recognition models that support/perform a Spoken Language Understanding task, achieving 99.8% attack success rate by poisoning 10% of the training data. We analyzed how varying the signal-strength of the poison, percent of samples poisoned, and choice of trigger impact the attack. We also found that CLBD attacks are most successful when applied to training samples that are inherently hard for a proxy model. Using this strategy, we achieved an attack success rate of 99.3% by poisoning a meager 1.5% of the training data. Finally, we applied two previously developed defenses against gradient-based attacks, and found that they attain mixed success against poisoning.
Privacy versus Emotion Preservation Trade-offs in Emotion-Preserving Speaker Anonymization
Sep 05, 2024Advances in speech technology now allow unprecedented access to personally identifiable information through speech. To protect such information, the differential privacy field has explored ways to anonymize speech while preserving its utility, including linguistic and paralinguistic aspects. However, anonymizing speech while maintaining emotional state remains challenging. We explore this problem in the context of the VoicePrivacy 2024 challenge. Specifically, we developed various speaker anonymization pipelines and find that approaches either excel at anonymization or preserving emotion state, but not both simultaneously. Achieving both would require an in-domain emotion recognizer. Additionally, we found that it is feasible to train a semi-effective speaker verification system using only emotion representations, demonstrating the challenge of separating these two modalities.
Improving Neural Biasing for Contextual Speech Recognition by Early Context Injection and Text Perturbation
Jul 14, 2024Existing research suggests that automatic speech recognition (ASR) models can benefit from additional contexts (e.g., contact lists, user specified vocabulary). Rare words and named entities can be better recognized with contexts. In this work, we propose two simple yet effective techniques to improve context-aware ASR models. First, we inject contexts into the encoders at an early stage instead of merely at their last layers. Second, to enforce the model to leverage the contexts during training, we perturb the reference transcription with alternative spellings so that the model learns to rely on the contexts to make correct predictions. On LibriSpeech, our techniques together reduce the rare word error rate by 60% and 25% relatively compared to no biasing and shallow fusion, making the new state-of-the-art performance. On SPGISpeech and a real-world dataset ConEC, our techniques also yield good improvements over the baselines.
Multi-Channel Multi-Speaker ASR Using Target Speaker's Solo Segment
Jun 17, 2024



In the field of multi-channel, multi-speaker Automatic Speech Recognition (ASR), the task of discerning and accurately transcribing a target speaker's speech within background noise remains a formidable challenge. Traditional approaches often rely on microphone array configurations and the information of the target speaker's location or voiceprint. This study introduces the Solo Spatial Feature (Solo-SF), an innovative method that utilizes a target speaker's isolated speech segment to enhance ASR performance, thereby circumventing the need for conventional inputs like microphone array layouts. We explore effective strategies for selecting optimal solo segments, a crucial aspect for Solo-SF's success. Through evaluations conducted on the AliMeeting dataset and AISHELL-1 simulations, Solo-SF demonstrates superior performance over existing techniques, significantly lowering Character Error Rates (CER) in various test conditions. Our findings highlight Solo-SF's potential as an effective solution for addressing the complexities of multi-channel, multi-speaker ASR tasks.
Acoustic modeling for Overlapping Speech Recognition: JHU Chime-5 Challenge System
May 17, 2024This paper summarizes our acoustic modeling efforts in the Johns Hopkins University speech recognition system for the CHiME-5 challenge to recognize highly-overlapped dinner party speech recorded by multiple microphone arrays. We explore data augmentation approaches, neural network architectures, front-end speech dereverberation, beamforming and robust i-vector extraction with comparisons of our in-house implementations and publicly available tools. We finally achieved a word error rate of 69.4% on the development set, which is a 11.7% absolute improvement over the previous baseline of 81.1%, and release this improved baseline with refined techniques/tools as an advanced CHiME-5 recipe.
* Published in: ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Kreyòl-MT: Building MT for Latin American, Caribbean and Colonial African Creole Languages
May 08, 2024



A majority of language technologies are tailored for a small number of high-resource languages, while relatively many low-resource languages are neglected. One such group, Creole languages, have long been marginalized in academic study, though their speakers could benefit from machine translation (MT). These languages are predominantly used in much of Latin America, Africa and the Caribbean. We present the largest cumulative dataset to date for Creole language MT, including 14.5M unique Creole sentences with parallel translations -- 11.6M of which we release publicly, and the largest bitexts gathered to date for 41 languages -- the first ever for 21. In addition, we provide MT models supporting all 41 Creole languages in 172 translation directions. Given our diverse dataset, we produce a model for Creole language MT exposed to more genre diversity than ever before, which outperforms a genre-specific Creole MT model on its own benchmark for 23 of 34 translation directions.