 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemper-Then-Tilt: Principled Unlearning for Generative Models through Tempering and Classifier Guidance
Feb 10, 2026We study machine unlearning in large generative models by framing the task as density ratio estimation to a target distribution rather than supervised fine-tuning. While classifier guidance is a standard approach for approximating this ratio and can succeed in general, we show it can fail to faithfully unlearn with finite samples when the forget set represents a sharp, concentrated data distribution. To address this, we introduce Temper-Then-Tilt Unlearning (T3-Unlearning), which freezes the base model and applies a two-step inference procedure: (i) tempering the base distribution to flatten high-confidence spikes, and (ii) tilting the tempered distribution using a lightweight classifier trained to distinguish retain from forget samples. Our theoretical analysis provides finite-sample guarantees linking the surrogate classifier's risk to unlearning error, proving that tempering is necessary to successfully unlearn for concentrated distributions. Empirical evaluations on the TOFU benchmark show that T3-Unlearning improves forget quality and generative utility over existing baselines, while training only a fraction of the parameters with a minimal runtime.
Machine Unlearning under Overparameterization
May 28, 2025Machine unlearning algorithms aim to remove the influence of specific training samples, ideally recovering the model that would have resulted from training on the remaining data alone. We study unlearning in the overparameterized setting, where many models interpolate the data, and defining the unlearning solution as any loss minimizer over the retained set$\unicode{x2013}$as in prior work in the underparameterized setting$\unicode{x2013}$is inadequate, since the original model may already interpolate the retained data and satisfy this condition. In this regime, loss gradients vanish, rendering prior methods based on gradient perturbations ineffective, motivating both new unlearning definitions and algorithms. For this setting, we define the unlearning solution as the minimum-complexity interpolator over the retained data and propose a new algorithmic framework that only requires access to model gradients on the retained set at the original solution. We minimize a regularized objective over perturbations constrained to be orthogonal to these model gradients, a first-order relaxation of the interpolation condition. For different model classes, we provide exact and approximate unlearning guarantees, and we demonstrate that an implementation of our framework outperforms existing baselines across various unlearning experiments.
Meta-Learning Adaptable Foundation Models
Oct 29, 2024


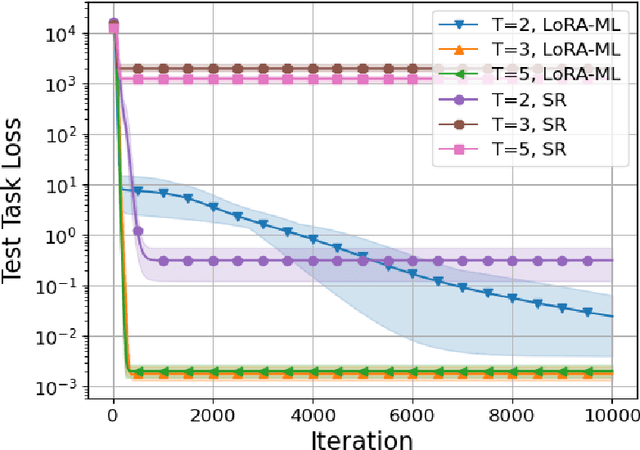
The power of foundation models (FMs) lies in their capacity to learn highly expressive representations that can be adapted to a broad spectrum of tasks. However, these pretrained models require multiple stages of fine-tuning to become effective for downstream applications. Conventionally, the model is first retrained on the aggregate of a diverse set of tasks of interest and then adapted to specific low-resource downstream tasks by utilizing a parameter-efficient fine-tuning (PEFT) scheme. While this two-phase procedure seems reasonable, the independence of the retraining and fine-tuning phases causes a major issue, as there is no guarantee the retrained model will achieve good performance post-fine-tuning. To explicitly address this issue, we introduce a meta-learning framework infused with PEFT in this intermediate retraining stage to learn a model that can be easily adapted to unseen tasks. For our theoretical results, we focus on linear models using low-rank adaptations. In this setting, we demonstrate the suboptimality of standard retraining for finding an adaptable set of parameters. Further, we prove that our method recovers the optimally adaptable parameters. We then apply these theoretical insights to retraining the RoBERTa model to predict the continuation of conversations between different personas within the ConvAI2 dataset. Empirically, we observe significant performance benefits using our proposed meta-learning scheme during retraining relative to the conventional approach.