 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Data Collection for Machine Learning
Oct 03, 2022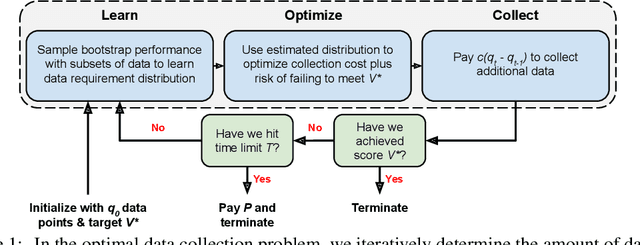
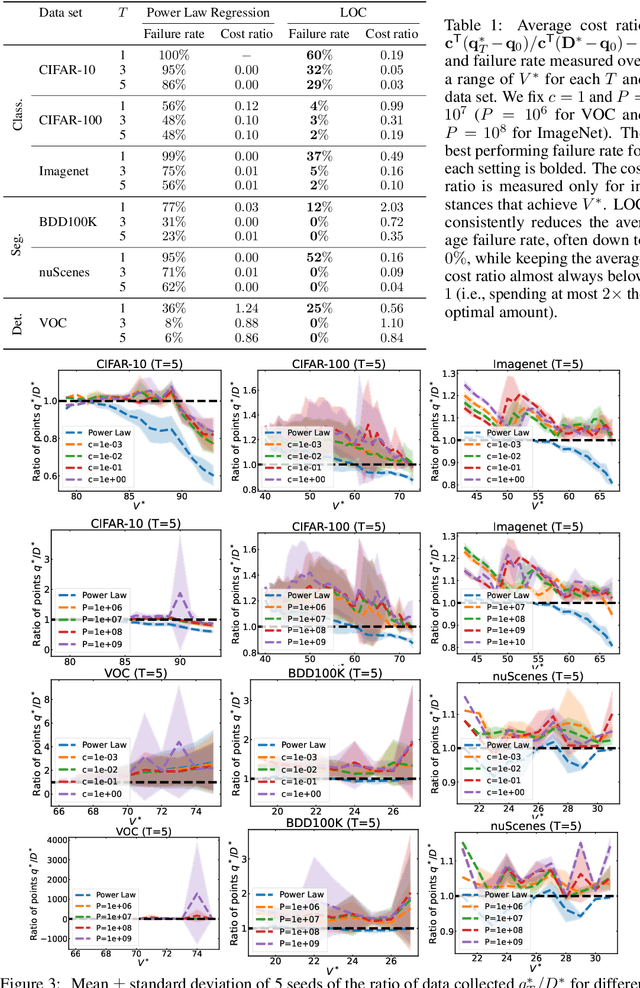
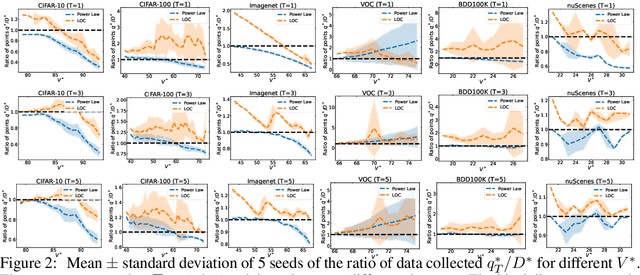
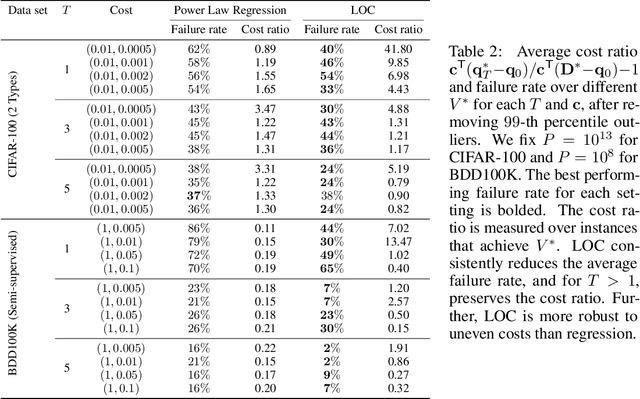
Modern deep learning systems require huge data sets to achieve impressive performance, but there is little guidance on how much or what kind of data to collect. Over-collecting data incurs unnecessary present costs, while under-collecting may incur future costs and delay workflows. We propose a new paradigm for modeling the data collection workflow as a formal optimal data collection problem that allows designers to specify performance targets, collection costs, a time horizon, and penalties for failing to meet the targets. Additionally, this formulation generalizes to tasks requiring multiple data sources, such as labeled and unlabeled data used in semi-supervised learning. To solve our problem, we develop Learn-Optimize-Collect (LOC), which minimizes expected future collection costs. Finally, we numerically compare our framework to the conventional baseline of estimating data requirements by extrapolating from neural scaling laws. We significantly reduce the risks of failing to meet desired performance targets on several classification, segmentation, and detection tasks, while maintaining low total collection costs.
EPIC-KITCHENS VISOR Benchmark: VIdeo Segmentations and Object Relations
Sep 26, 2022
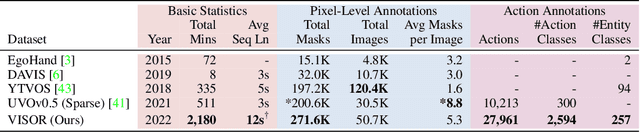
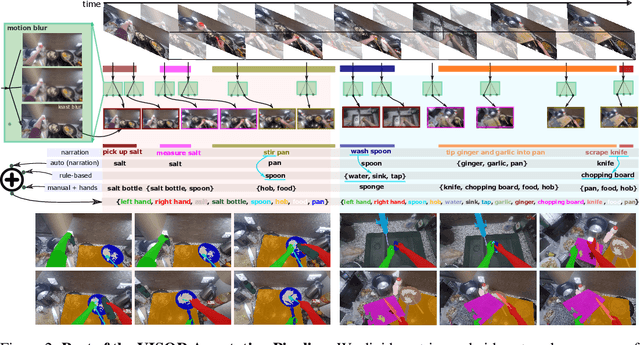
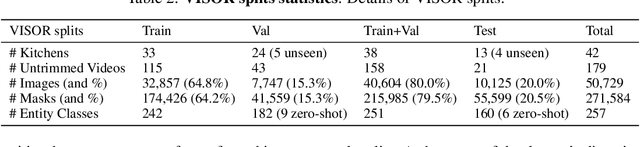
We introduce VISOR, a new dataset of pixel annotations and a benchmark suite for segmenting hands and active objects in egocentric video. VISOR annotates videos from EPIC-KITCHENS, which comes with a new set of challenges not encountered in current video segmentation datasets. Specifically, we need to ensure both short- and long-term consistency of pixel-level annotations as objects undergo transformative interactions, e.g. an onion is peeled, diced and cooked - where we aim to obtain accurate pixel-level annotations of the peel, onion pieces, chopping board, knife, pan, as well as the acting hands. VISOR introduces an annotation pipeline, AI-powered in parts, for scalability and quality. In total, we publicly release 272K manual semantic masks of 257 object classes, 9.9M interpolated dense masks, 67K hand-object relations, covering 36 hours of 179 untrimmed videos. Along with the annotations, we introduce three challenges in video object segmentation, interaction understanding and long-term reasoning. For data, code and leaderboards: http://epic-kitchens.github.io/VISOR
GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images
Sep 22, 2022



As several industries are moving towards modeling massive 3D virtual worlds, the need for content creation tools that can scale in terms of the quantity, quality, and diversity of 3D content is becoming evident. In our work, we aim to train performant 3D generative models that synthesize textured meshes which can be directly consumed by 3D rendering engines, thus immediately usable in downstream applications. Prior works on 3D generative modeling either lack geometric details, are limited in the mesh topology they can produce, typically do not support textures, or utilize neural renderers in the synthesis process, which makes their use in common 3D software non-trivial. In this work, we introduce GET3D, a Generative model that directly generates Explicit Textured 3D meshes with complex topology, rich geometric details, and high-fidelity textures. We bridge recent success in the differentiable surface modeling, differentiable rendering as well as 2D Generative Adversarial Networks to train our model from 2D image collections. GET3D is able to generate high-quality 3D textured meshes, ranging from cars, chairs, animals, motorbikes and human characters to buildings, achieving significant improvements over previous methods.
Neural Light Field Estimation for Street Scenes with Differentiable Virtual Object Insertion
Aug 19, 2022
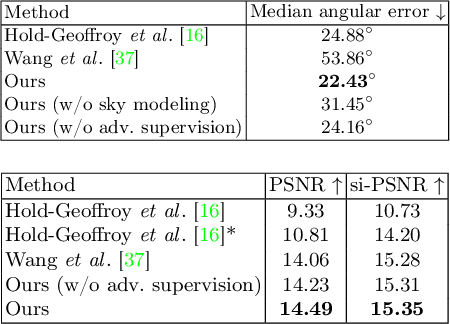


We consider the challenging problem of outdoor lighting estimation for the goal of photorealistic virtual object insertion into photographs. Existing works on outdoor lighting estimation typically simplify the scene lighting into an environment map which cannot capture the spatially-varying lighting effects in outdoor scenes. In this work, we propose a neural approach that estimates the 5D HDR light field from a single image, and a differentiable object insertion formulation that enables end-to-end training with image-based losses that encourage realism. Specifically, we design a hybrid lighting representation tailored to outdoor scenes, which contains an HDR sky dome that handles the extreme intensity of the sun, and a volumetric lighting representation that models the spatially-varying appearance of the surrounding scene. With the estimated lighting, our shadow-aware object insertion is fully differentiable, which enables adversarial training over the composited image to provide additional supervisory signal to the lighting prediction. We experimentally demonstrate that our hybrid lighting representation is more performant than existing outdoor lighting estimation methods. We further show the benefits of our AR object insertion in an autonomous driving application, where we obtain performance gains for a 3D object detector when trained on our augmented data.
* Webpage: https://nv-tlabs.github.io/outdoor-ar/
MvDeCor: Multi-view Dense Correspondence Learning for Fine-grained 3D Segmentation
Aug 18, 2022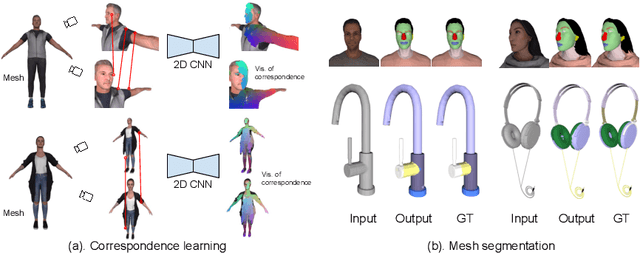
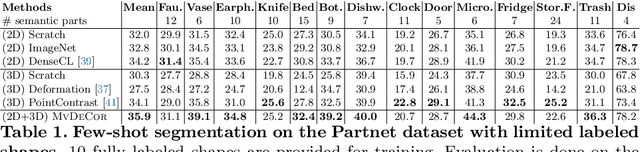
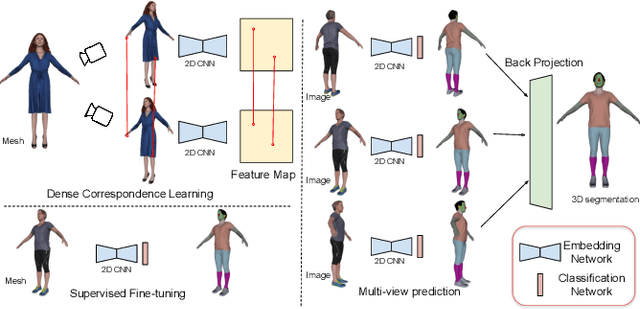
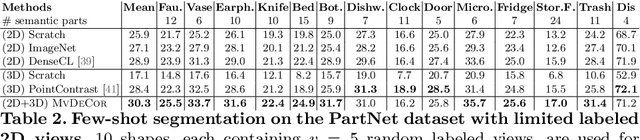
We propose to utilize self-supervised techniques in the 2D domain for fine-grained 3D shape segmentation tasks. This is inspired by the observation that view-based surface representations are more effective at modeling high-resolution surface details and texture than their 3D counterparts based on point clouds or voxel occupancy. Specifically, given a 3D shape, we render it from multiple views, and set up a dense correspondence learning task within the contrastive learning framework. As a result, the learned 2D representations are view-invariant and geometrically consistent, leading to better generalization when trained on a limited number of labeled shapes compared to alternatives that utilize self-supervision in 2D or 3D alone. Experiments on textured (RenderPeople) and untextured (PartNet) 3D datasets show that our method outperforms state-of-the-art alternatives in fine-grained part segmentation. The improvements over baselines are greater when only a sparse set of views is available for training or when shapes are textured, indicating that MvDeCor benefits from both 2D processing and 3D geometric reasoning.
How Much More Data Do I Need? Estimating Requirements for Downstream Tasks
Jul 13, 2022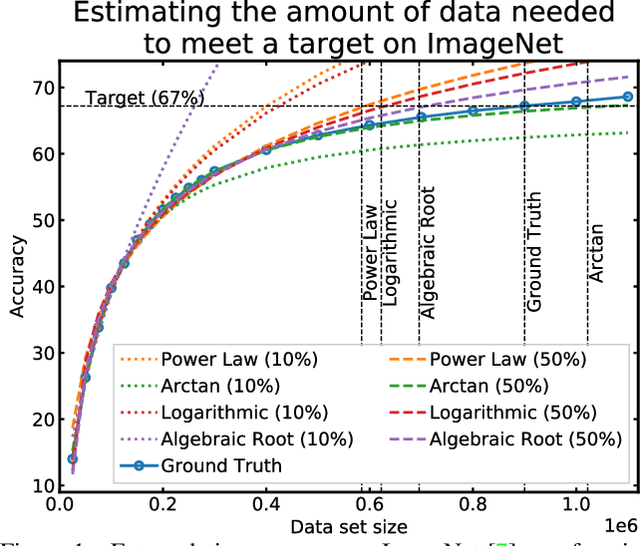

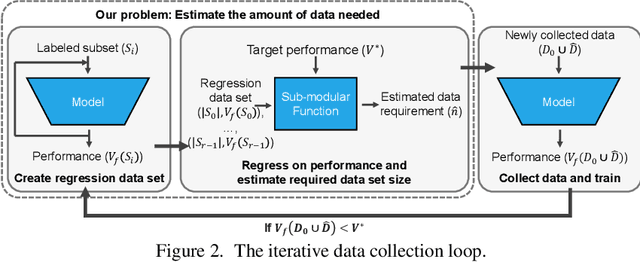
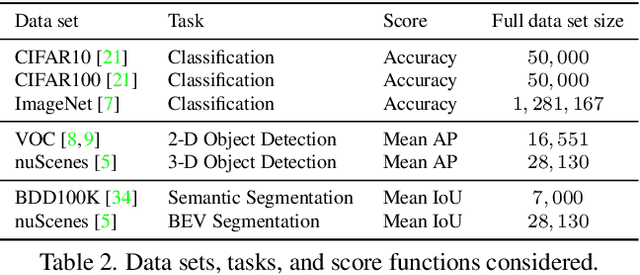
Given a small training data set and a learning algorithm, how much more data is necessary to reach a target validation or test performance? This question is of critical importance in applications such as autonomous driving or medical imaging where collecting data is expensive and time-consuming. Overestimating or underestimating data requirements incurs substantial costs that could be avoided with an adequate budget. Prior work on neural scaling laws suggest that the power-law function can fit the validation performance curve and extrapolate it to larger data set sizes. We find that this does not immediately translate to the more difficult downstream task of estimating the required data set size to meet a target performance. In this work, we consider a broad class of computer vision tasks and systematically investigate a family of functions that generalize the power-law function to allow for better estimation of data requirements. Finally, we show that incorporating a tuned correction factor and collecting over multiple rounds significantly improves the performance of the data estimators. Using our guidelines, practitioners can accurately estimate data requirements of machine learning systems to gain savings in both development time and data acquisition costs.
Improving Semantic Segmentation in Transformers using Hierarchical Inter-Level Attention
Jul 05, 2022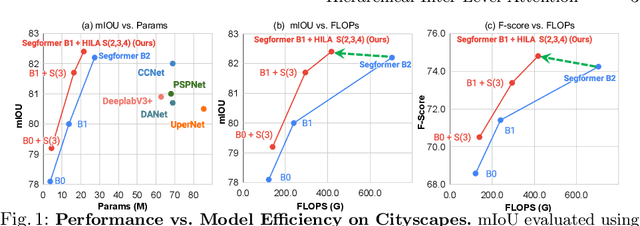
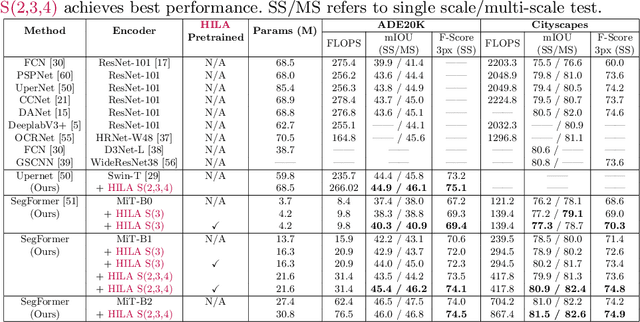
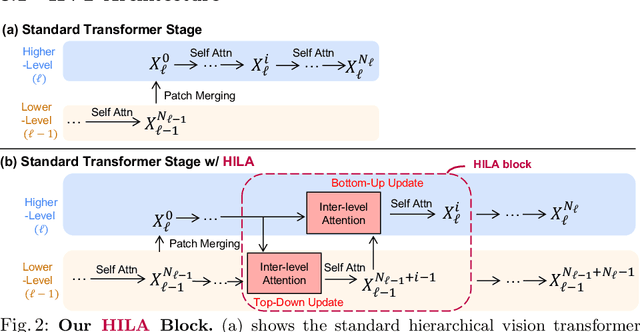
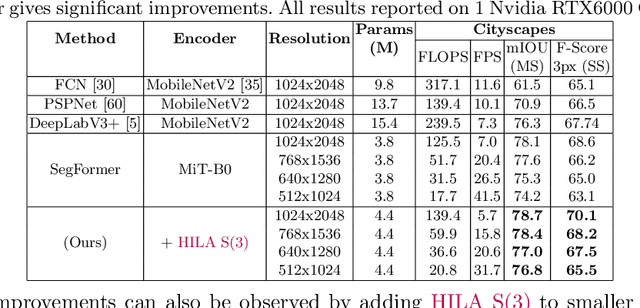
Existing transformer-based image backbones typically propagate feature information in one direction from lower to higher-levels. This may not be ideal since the localization ability to delineate accurate object boundaries, is most prominent in the lower, high-resolution feature maps, while the semantics that can disambiguate image signals belonging to one object vs. another, typically emerges in a higher level of processing. We present Hierarchical Inter-Level Attention (HILA), an attention-based method that captures Bottom-Up and Top-Down Updates between features of different levels. HILA extends hierarchical vision transformer architectures by adding local connections between features of higher and lower levels to the backbone encoder. In each iteration, we construct a hierarchy by having higher-level features compete for assignments to update lower-level features belonging to them, iteratively resolving object-part relationships. These improved lower-level features are then used to re-update the higher-level features. HILA can be integrated into the majority of hierarchical architectures without requiring any changes to the base model. We add HILA into SegFormer and the Swin Transformer and show notable improvements in accuracy in semantic segmentation with fewer parameters and FLOPS. Project website and code: https://www.cs.toronto.edu/~garyleung/hila/
Scalable Neural Data Server: A Data Recommender for Transfer Learning
Jun 19, 2022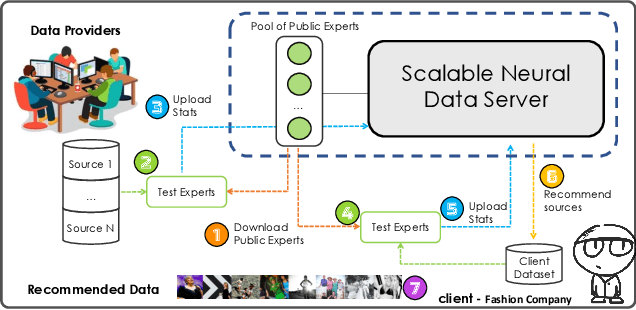
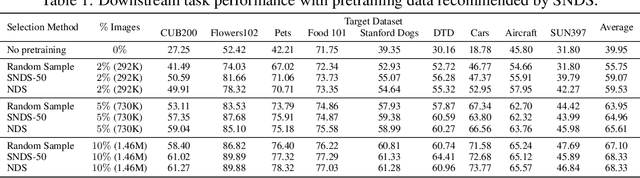
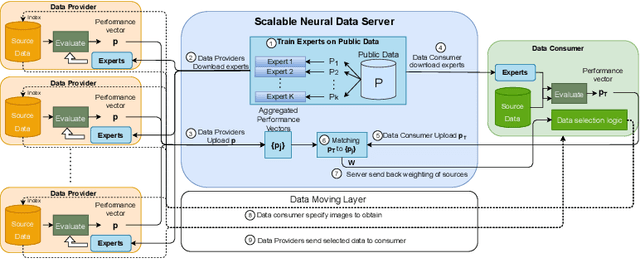
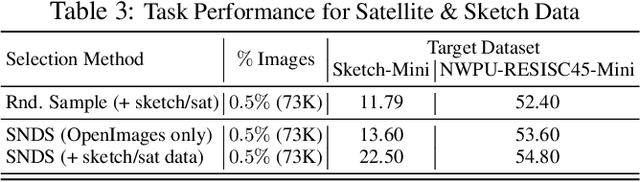
Absence of large-scale labeled data in the practitioner's target domain can be a bottleneck to applying machine learning algorithms in practice. Transfer learning is a popular strategy for leveraging additional data to improve the downstream performance, but finding the most relevant data to transfer from can be challenging. Neural Data Server (NDS), a search engine that recommends relevant data for a given downstream task, has been previously proposed to address this problem. NDS uses a mixture of experts trained on data sources to estimate similarity between each source and the downstream task. Thus, the computational cost to each user grows with the number of sources. To address these issues, we propose Scalable Neural Data Server (SNDS), a large-scale search engine that can theoretically index thousands of datasets to serve relevant ML data to end users. SNDS trains the mixture of experts on intermediary datasets during initialization, and represents both data sources and downstream tasks by their proximity to the intermediary datasets. As such, computational cost incurred by SNDS users remains fixed as new datasets are added to the server. We validate SNDS on a plethora of real world tasks and find that data recommended by SNDS improves downstream task performance over baselines. We also demonstrate the scalability of SNDS by showing its ability to select relevant data for transfer outside of the natural image setting.
* Neurips 2021
Variable Bitrate Neural Fields
Jun 15, 2022
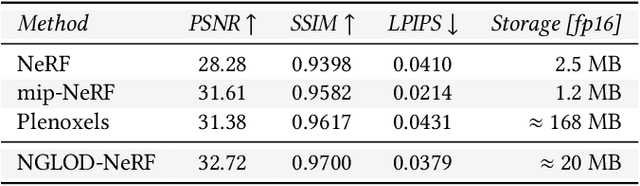

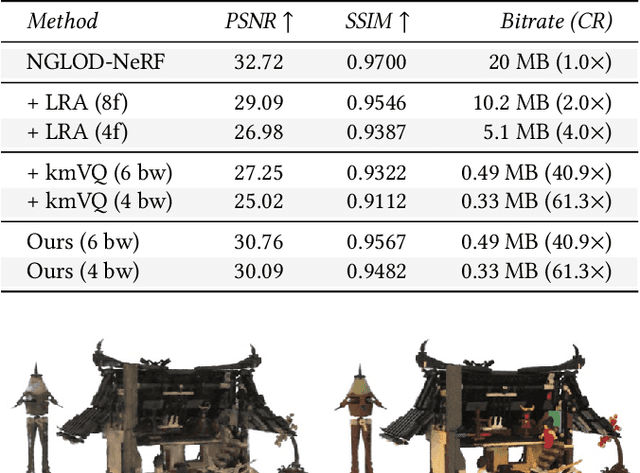
Neural approximations of scalar and vector fields, such as signed distance functions and radiance fields, have emerged as accurate, high-quality representations. State-of-the-art results are obtained by conditioning a neural approximation with a lookup from trainable feature grids that take on part of the learning task and allow for smaller, more efficient neural networks. Unfortunately, these feature grids usually come at the cost of significantly increased memory consumption compared to stand-alone neural network models. We present a dictionary method for compressing such feature grids, reducing their memory consumption by up to 100x and permitting a multiresolution representation which can be useful for out-of-core streaming. We formulate the dictionary optimization as a vector-quantized auto-decoder problem which lets us learn end-to-end discrete neural representations in a space where no direct supervision is available and with dynamic topology and structure. Our source code will be available at https://github.com/nv-tlabs/vqad.
Polymorphic-GAN: Generating Aligned Samples across Multiple Domains with Learned Morph Maps
Jun 06, 2022



Modern image generative models show remarkable sample quality when trained on a single domain or class of objects. In this work, we introduce a generative adversarial network that can simultaneously generate aligned image samples from multiple related domains. We leverage the fact that a variety of object classes share common attributes, with certain geometric differences. We propose Polymorphic-GAN which learns shared features across all domains and a per-domain morph layer to morph shared features according to each domain. In contrast to previous works, our framework allows simultaneous modelling of images with highly varying geometries, such as images of human faces, painted and artistic faces, as well as multiple different animal faces. We demonstrate that our model produces aligned samples for all domains and show how it can be used for applications such as segmentation transfer and cross-domain image editing, as well as training in low-data regimes. Additionally, we apply our Polymorphic-GAN on image-to-image translation tasks and show that we can greatly surpass previous approaches in cases where the geometric differences between domains are large.