 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing for Reading Times
Apr 20, 2026Probing has shown that language model representations encode rich linguistic information, but it remains unclear whether they also capture cognitive signals about human processing. In this work, we probe language model representations for human reading times. Using regularized linear regression on two eye-tracking corpora spanning five languages (English, Greek, Hebrew, Russian, and Turkish), we compare the representations from every model layer against scalar predictors -- surprisal, information value, and logit-lens surprisal. We find that the representations from early layers outperform surprisal in predicting early-pass measures such as first fixation and gaze duration. The concentration of predictive power in the early layers suggests that human-like processing signatures are captured by low-level structural or lexical representations, pointing to a functional alignment between model depth and the temporal stages of human reading. In contrast, for late-pass measures such as total reading time, scalar surprisal remains superior, despite its being a much more compressed representation. We also observe performance gains when using both surprisal and early-layer representations. Overall, we find that the best-performing predictor varies strongly depending on the language and eye-tracking measure.
Ensembling Language Models with Sequential Monte Carlo
Mar 05, 2026Practitioners have access to an abundance of language models and prompting strategies for solving many language modeling tasks; yet prior work shows that modeling performance is highly sensitive to both choices. Classical machine learning ensembling techniques offer a principled approach: aggregate predictions from multiple sources to achieve better performance than any single one. However, applying ensembling to language models during decoding is challenging: naively aggregating next-token probabilities yields samples from a locally normalized, biased approximation of the generally intractable ensemble distribution over strings. In this work, we introduce a unified framework for composing $K$ language models into $f$-ensemble distributions for a wide range of functions $f\colon\mathbb{R}_{\geq 0}^{K}\to\mathbb{R}_{\geq 0}$. To sample from these distributions, we propose a byte-level sequential Monte Carlo (SMC) algorithm that operates in a shared character space, enabling ensembles of models with mismatching vocabularies and consistent sampling in the limit. We evaluate a family of $f$-ensembles across prompt and model combinations for various structured text generation tasks, highlighting the benefits of alternative aggregation strategies over traditional probability averaging, and showing that better posterior approximations can yield better ensemble performance.
Transducing Language Models
Mar 05, 2026Modern language models define distributions over strings, but downstream tasks often require different output formats. For instance, a model that generates byte-pair strings does not directly produce word-level predictions, and a DNA model does not directly produce amino-acid sequences. In such cases, a deterministic string-to-string transformation can convert the model's output to the desired form. This is a familiar pattern in probability theory: applying a function $f$ to a random variable $X\sim p$ yields a transformed random variable $f(X)$ with an induced distribution. While such transformations are occasionally used in language modeling, prior work does not treat them as yielding new, fully functional language models. We formalize this perspective and introduce a general framework for language models derived from deterministic string-to-string transformations. We focus on transformations representable as finite-state transducers -- a commonly used state-machine abstraction for efficient string-to-string mappings. We develop algorithms that compose a language model with an FST to *marginalize* over source strings mapping to a given target, propagating probabilities through the transducer without altering model parameters and enabling *conditioning* on transformed outputs. We present an exact algorithm, an efficient approximation, and a theoretical analysis. We conduct experiments in three domains: converting language models from tokens to bytes, from tokens to words, and from DNA to amino acids. These experiments demonstrate inference-time adaptation of pretrained language models to match application-specific output requirements.
The Harmonic Structure of Information Contours
Jun 04, 2025



The uniform information density (UID) hypothesis proposes that speakers aim to distribute information evenly throughout a text, balancing production effort and listener comprehension difficulty. However, language typically does not maintain a strictly uniform information rate; instead, it fluctuates around a global average. These fluctuations are often explained by factors such as syntactic constraints, stylistic choices, or audience design. In this work, we explore an alternative perspective: that these fluctuations may be influenced by an implicit linguistic pressure towards periodicity, where the information rate oscillates at regular intervals, potentially across multiple frequencies simultaneously. We apply harmonic regression and introduce a novel extension called time scaling to detect and test for such periodicity in information contours. Analyzing texts in English, Spanish, German, Dutch, Basque, and Brazilian Portuguese, we find consistent evidence of periodic patterns in information rate. Many dominant frequencies align with discourse structure, suggesting these oscillations reflect meaningful linguistic organization. Beyond highlighting the connection between information rate and discourse structure, our approach offers a general framework for uncovering structural pressures at various levels of linguistic granularity.
Reverse-Engineering the Reader
Oct 16, 2024Numerous previous studies have sought to determine to what extent language models, pretrained on natural language text, can serve as useful models of human cognition. In this paper, we are interested in the opposite question: whether we can directly optimize a language model to be a useful cognitive model by aligning it to human psychometric data. To achieve this, we introduce a novel alignment technique in which we fine-tune a language model to implicitly optimize the parameters of a linear regressor that directly predicts humans' reading times of in-context linguistic units, e.g., phonemes, morphemes, or words, using surprisal estimates derived from the language model. Using words as a test case, we evaluate our technique across multiple model sizes and datasets and find that it improves language models' psychometric predictive power. However, we find an inverse relationship between psychometric power and a model's performance on downstream NLP tasks as well as its perplexity on held-out test data. While this latter trend has been observed before (Oh et al., 2022; Shain et al., 2024), we are the first to induce it by manipulating a model's alignment to psychometric data.
Reading Task Classification Using EEG and Eye-Tracking Data
Dec 12, 2021
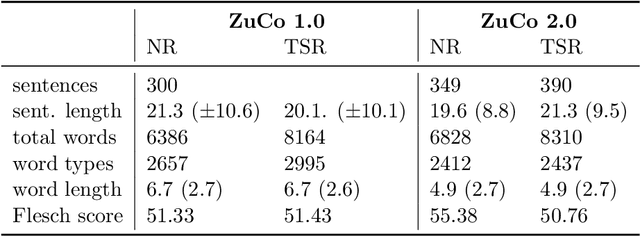

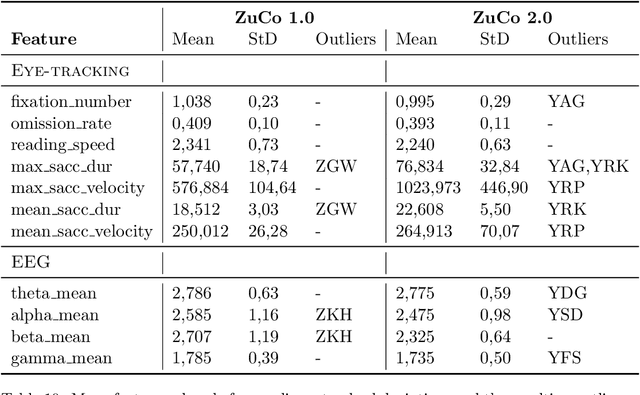
The Zurich Cognitive Language Processing Corpus (ZuCo) provides eye-tracking and EEG signals from two reading paradigms, normal reading and task-specific reading. We analyze whether machine learning methods are able to classify these two tasks using eye-tracking and EEG features. We implement models with aggregated sentence-level features as well as fine-grained word-level features. We test the models in within-subject and cross-subject evaluation scenarios. All models are tested on the ZuCo 1.0 and ZuCo 2.0 data subsets, which are characterized by differing recording procedures and thus allow for different levels of generalizability. Finally, we provide a series of control experiments to analyze the results in more detail.
Revisiting the Weaknesses of Reinforcement Learning for Neural Machine Translation
Jun 16, 2021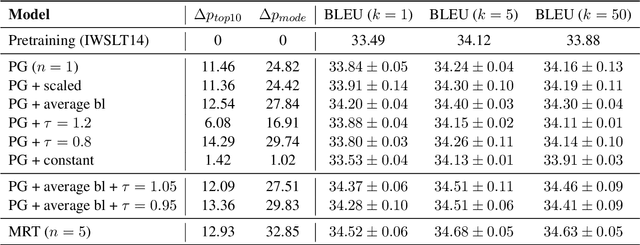
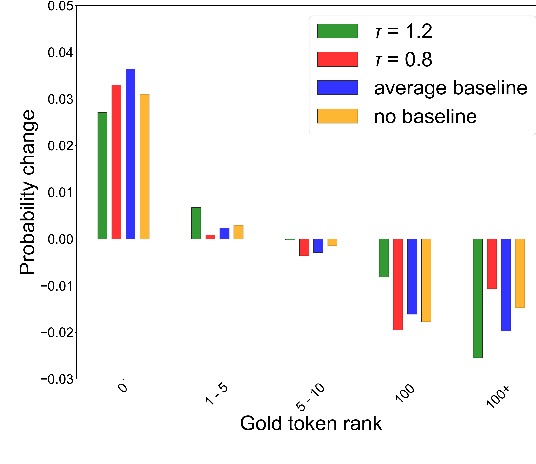
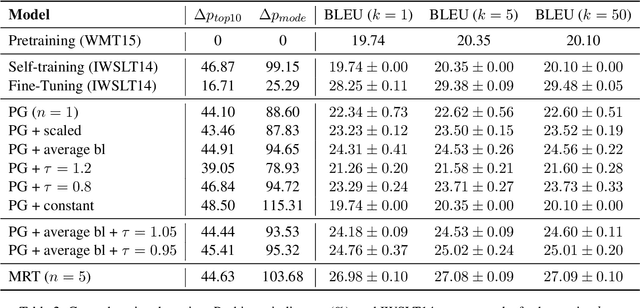
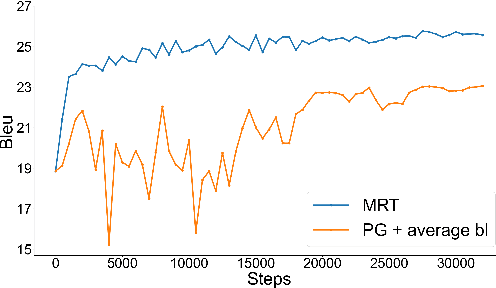
Policy gradient algorithms have found wide adoption in NLP, but have recently become subject to criticism, doubting their suitability for NMT. Choshen et al. (2020) identify multiple weaknesses and suspect that their success is determined by the shape of output distributions rather than the reward. In this paper, we revisit these claims and study them under a wider range of configurations. Our experiments on in-domain and cross-domain adaptation reveal the importance of exploration and reward scaling, and provide empirical counter-evidence to these claims.