 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing for Reading Times
Apr 20, 2026Probing has shown that language model representations encode rich linguistic information, but it remains unclear whether they also capture cognitive signals about human processing. In this work, we probe language model representations for human reading times. Using regularized linear regression on two eye-tracking corpora spanning five languages (English, Greek, Hebrew, Russian, and Turkish), we compare the representations from every model layer against scalar predictors -- surprisal, information value, and logit-lens surprisal. We find that the representations from early layers outperform surprisal in predicting early-pass measures such as first fixation and gaze duration. The concentration of predictive power in the early layers suggests that human-like processing signatures are captured by low-level structural or lexical representations, pointing to a functional alignment between model depth and the temporal stages of human reading. In contrast, for late-pass measures such as total reading time, scalar surprisal remains superior, despite its being a much more compressed representation. We also observe performance gains when using both surprisal and early-layer representations. Overall, we find that the best-performing predictor varies strongly depending on the language and eye-tracking measure.
A Survey on Gender Bias in Natural Language Processing
Dec 28, 2021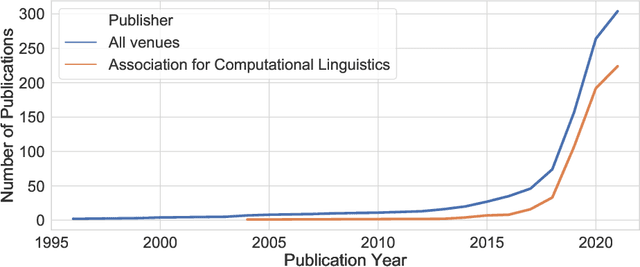
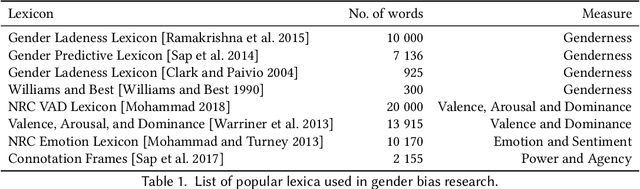


Language can be used as a means of reproducing and enforcing harmful stereotypes and biases and has been analysed as such in numerous research. In this paper, we present a survey of 304 papers on gender bias in natural language processing. We analyse definitions of gender and its categories within social sciences and connect them to formal definitions of gender bias in NLP research. We survey lexica and datasets applied in research on gender bias and then compare and contrast approaches to detecting and mitigating gender bias. We find that research on gender bias suffers from four core limitations. 1) Most research treats gender as a binary variable neglecting its fluidity and continuity. 2) Most of the work has been conducted in monolingual setups for English or other high-resource languages. 3) Despite a myriad of papers on gender bias in NLP methods, we find that most of the newly developed algorithms do not test their models for bias and disregard possible ethical considerations of their work. 4) Finally, methodologies developed in this line of research are fundamentally flawed covering very limited definitions of gender bias and lacking evaluation baselines and pipelines. We suggest recommendations towards overcoming these limitations as a guide for future research.