 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan GPT-4 Perform Neural Architecture Search?
Apr 24, 2023



We investigate the potential of GPT-4~\cite{gpt4} to perform Neural Architecture Search (NAS) -- the task of designing effective neural architectures. Our proposed approach, \textbf{G}PT-4 \textbf{E}nhanced \textbf{N}eural arch\textbf{I}tect\textbf{U}re \textbf{S}earch (GENIUS), leverages the generative capabilities of GPT-4 as a black-box optimiser to quickly navigate the architecture search space, pinpoint promising candidates, and iteratively refine these candidates to improve performance. We assess GENIUS across several benchmarks, comparing it with existing state-of-the-art NAS techniques to illustrate its effectiveness. Rather than targeting state-of-the-art performance, our objective is to highlight GPT-4's potential to assist research on a challenging technical problem through a simple prompting scheme that requires relatively limited domain expertise\footnote{Code available at \href{https://github.com/mingkai-zheng/GENIUS}{https://github.com/mingkai-zheng/GENIUS}.}. More broadly, we believe our preliminary results point to future research that harnesses general purpose language models for diverse optimisation tasks. We also highlight important limitations to our study, and note implications for AI safety.
SATIN: A Multi-Task Metadataset for Classifying Satellite Imagery using Vision-Language Models
Apr 23, 2023



Interpreting remote sensing imagery enables numerous downstream applications ranging from land-use planning to deforestation monitoring. Robustly classifying this data is challenging due to the Earth's geographic diversity. While many distinct satellite and aerial image classification datasets exist, there is yet to be a benchmark curated that suitably covers this diversity. In this work, we introduce SATellite ImageNet (SATIN), a metadataset curated from 27 existing remotely sensed datasets, and comprehensively evaluate the zero-shot transfer classification capabilities of a broad range of vision-language (VL) models on SATIN. We find SATIN to be a challenging benchmark-the strongest method we evaluate achieves a classification accuracy of 52.0%. We provide a $\href{https://satinbenchmark.github.io}{\text{public leaderboard}}$ to guide and track the progress of VL models in this important domain.
Large Language Models are Few-shot Publication Scoopers
Apr 02, 2023Driven by recent advances AI, we passengers are entering a golden age of scientific discovery. But golden for whom? Confronting our insecurity that others may beat us to the most acclaimed breakthroughs of the era, we propose a novel solution to the long-standing personal credit assignment problem to ensure that it is golden for us. At the heart of our approach is a pip-to-the-post algorithm that assures adulatory Wikipedia pages without incurring the substantial capital and career risks of pursuing high impact science with conventional research methodologies. By leveraging the meta trend of leveraging large language models for everything, we demonstrate the unparalleled potential of our algorithm to scoop groundbreaking findings with the insouciance of a seasoned researcher at a dessert buffet.
DeepMIM: Deep Supervision for Masked Image Modeling
Mar 16, 2023Deep supervision, which involves extra supervisions to the intermediate features of a neural network, was widely used in image classification in the early deep learning era since it significantly reduces the training difficulty and eases the optimization like avoiding gradient vanish over the vanilla training. Nevertheless, with the emergence of normalization techniques and residual connection, deep supervision in image classification was gradually phased out. In this paper, we revisit deep supervision for masked image modeling (MIM) that pre-trains a Vision Transformer (ViT) via a mask-and-predict scheme. Experimentally, we find that deep supervision drives the shallower layers to learn more meaningful representations, accelerates model convergence, and expands attention diversities. Our approach, called DeepMIM, significantly boosts the representation capability of each layer. In addition, DeepMIM is compatible with many MIM models across a range of reconstruction targets. For instance, using ViT-B, DeepMIM on MAE achieves 84.2 top-1 accuracy on ImageNet, outperforming MAE by +0.6. By combining DeepMIM with a stronger tokenizer CLIP, our model achieves state-of-the-art performance on various downstream tasks, including image classification (85.6 top-1 accuracy on ImageNet-1K, outperforming MAE-CLIP by +0.8), object detection (52.8 APbox on COCO) and semantic segmentation (53.1 mIoU on ADE20K). Code and models are available at https://github.com/OliverRensu/DeepMIM.
SuS-X: Training-Free Name-Only Transfer of Vision-Language Models
Nov 28, 2022Contrastive Language-Image Pre-training (CLIP) has emerged as a simple yet effective way to train large-scale vision-language models. CLIP demonstrates impressive zero-shot classification and retrieval on diverse downstream tasks. However, to leverage its full potential, fine-tuning still appears to be necessary. Fine-tuning the entire CLIP model can be resource-intensive and unstable. Moreover, recent methods that aim to circumvent this need for fine-tuning still require access to images from the target distribution. In this paper, we pursue a different approach and explore the regime of training-free "name-only transfer" in which the only knowledge we possess about the downstream task comprises the names of downstream target categories. We propose a novel method, SuS-X, consisting of two key building blocks -- SuS and TIP-X, that requires neither intensive fine-tuning nor costly labelled data. SuS-X achieves state-of-the-art zero-shot classification results on 19 benchmark datasets. We further show the utility of TIP-X in the training-free few-shot setting, where we again achieve state-of-the-art results over strong training-free baselines. Code is available at https://github.com/vishaal27/SuS-X.
Weakly-supervised Fingerspelling Recognition in British Sign Language Videos
Nov 16, 2022



The goal of this work is to detect and recognize sequences of letters signed using fingerspelling in British Sign Language (BSL). Previous fingerspelling recognition methods have not focused on BSL, which has a very different signing alphabet (e.g., two-handed instead of one-handed) to American Sign Language (ASL). They also use manual annotations for training. In contrast to previous methods, our method only uses weak annotations from subtitles for training. We localize potential instances of fingerspelling using a simple feature similarity method, then automatically annotate these instances by querying subtitle words and searching for corresponding mouthing cues from the signer. We propose a Transformer architecture adapted to this task, with a multiple-hypothesis CTC loss function to learn from alternative annotation possibilities. We employ a multi-stage training approach, where we make use of an initial version of our trained model to extend and enhance our training data before re-training again to achieve better performance. Through extensive evaluations, we verify our method for automatic annotation and our model architecture. Moreover, we provide a human expert annotated test set of 5K video clips for evaluating BSL fingerspelling recognition methods to support sign language research.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Crosslingual Generalization through Multitask Finetuning
Nov 03, 2022Multitask prompted finetuning (MTF) has been shown to help large language models generalize to new tasks in a zero-shot setting, but so far explorations of MTF have focused on English data and models. We apply MTF to the pretrained multilingual BLOOM and mT5 model families to produce finetuned variants called BLOOMZ and mT0. We find finetuning large multilingual language models on English tasks with English prompts allows for task generalization to non-English languages that appear only in the pretraining corpus. Finetuning on multilingual tasks with English prompts further improves performance on English and non-English tasks leading to various state-of-the-art zero-shot results. We also investigate finetuning on multilingual tasks with prompts that have been machine-translated from English to match the language of each dataset. We find training on these machine-translated prompts leads to better performance on human-written prompts in the respective languages. Surprisingly, we find models are capable of zero-shot generalization to tasks in languages they have never intentionally seen. We conjecture that the models are learning higher-level capabilities that are both task- and language-agnostic. In addition, we introduce xP3, a composite of supervised datasets in 46 languages with English and machine-translated prompts. Our code, datasets and models are publicly available at https://github.com/bigscience-workshop/xmtf.
NamedMask: Distilling Segmenters from Complementary Foundation Models
Sep 22, 2022

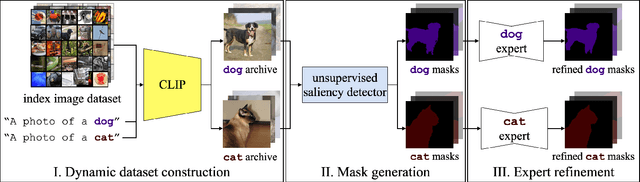
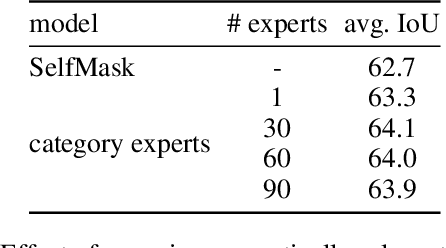
The goal of this work is to segment and name regions of images without access to pixel-level labels during training. To tackle this task, we construct segmenters by distilling the complementary strengths of two foundation models. The first, CLIP (Radford et al. 2021), exhibits the ability to assign names to image content but lacks an accessible representation of object structure. The second, DINO (Caron et al. 2021), captures the spatial extent of objects but has no knowledge of object names. Our method, termed NamedMask, begins by using CLIP to construct category-specific archives of images. These images are pseudo-labelled with a category-agnostic salient object detector bootstrapped from DINO, then refined by category-specific segmenters using the CLIP archive labels. Thanks to the high quality of the refined masks, we show that a standard segmentation architecture trained on these archives with appropriate data augmentation achieves impressive semantic segmentation abilities for both single-object and multi-object images. As a result, our proposed NamedMask performs favourably against a range of prior work on five benchmarks including the VOC2012, COCO and large-scale ImageNet-S datasets.
RLIP: Relational Language-Image Pre-training for Human-Object Interaction Detection
Sep 05, 2022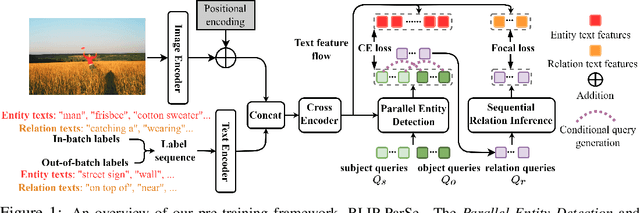
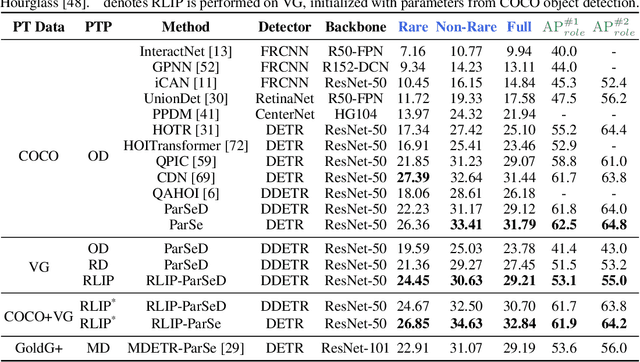
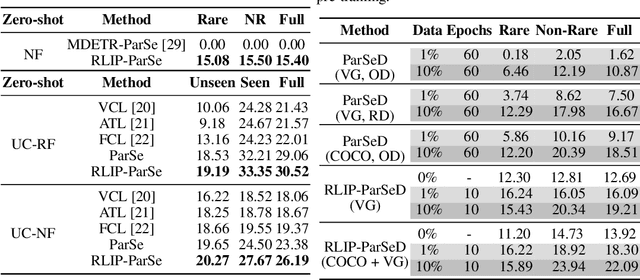

The task of Human-Object Interaction (HOI) detection targets fine-grained visual parsing of humans interacting with their environment, enabling a broad range of applications. Prior work has demonstrated the benefits of effective architecture design and integration of relevant cues for more accurate HOI detection. However, the design of an appropriate pre-training strategy for this task remains underexplored by existing approaches. To address this gap, we propose Relational Language-Image Pre-training (RLIP), a strategy for contrastive pre-training that leverages both entity and relation descriptions. To make effective use of such pre-training, we make three technical contributions: (1) a new Parallel entity detection and Sequential relation inference (ParSe) architecture that enables the use of both entity and relation descriptions during holistically optimized pre-training; (2) a synthetic data generation framework, Label Sequence Extension, that expands the scale of language data available within each minibatch; (3) mechanisms to account for ambiguity, Relation Quality Labels and Relation Pseudo-Labels, to mitigate the influence of ambiguous/noisy samples in the pre-training data. Through extensive experiments, we demonstrate the benefits of these contributions, collectively termed RLIP-ParSe, for improved zero-shot, few-shot and fine-tuning HOI detection performance as well as increased robustness to learning from noisy annotations. Code will be available at \url{https://github.com/JacobYuan7/RLIP}.