 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIB-R++: Learning to Predict Lighting and Material with a Hybrid Differentiable Renderer
Oct 30, 2021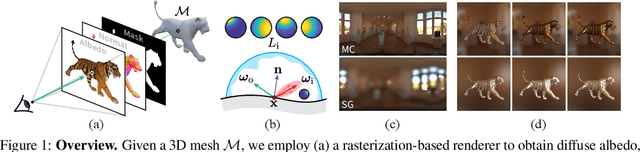
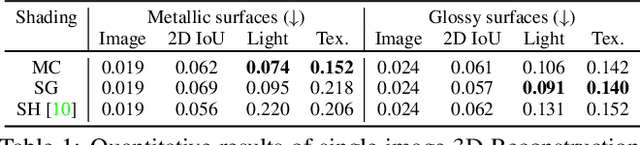
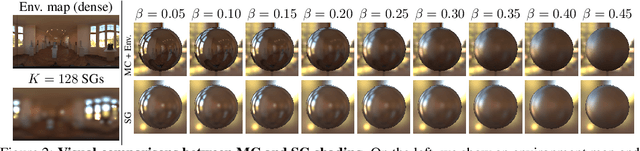

We consider the challenging problem of predicting intrinsic object properties from a single image by exploiting differentiable renderers. Many previous learning-based approaches for inverse graphics adopt rasterization-based renderers and assume naive lighting and material models, which often fail to account for non-Lambertian, specular reflections commonly observed in the wild. In this work, we propose DIBR++, a hybrid differentiable renderer which supports these photorealistic effects by combining rasterization and ray-tracing, taking the advantage of their respective strengths -- speed and realism. Our renderer incorporates environmental lighting and spatially-varying material models to efficiently approximate light transport, either through direct estimation or via spherical basis functions. Compared to more advanced physics-based differentiable renderers leveraging path tracing, DIBR++ is highly performant due to its compact and expressive shading model, which enables easy integration with learning frameworks for geometry, reflectance and lighting prediction from a single image without requiring any ground-truth. We experimentally demonstrate that our approach achieves superior material and lighting disentanglement on synthetic and real data compared to existing rasterization-based approaches and showcase several artistic applications including material editing and relighting.
3DStyleNet: Creating 3D Shapes with Geometric and Texture Style Variations
Aug 30, 2021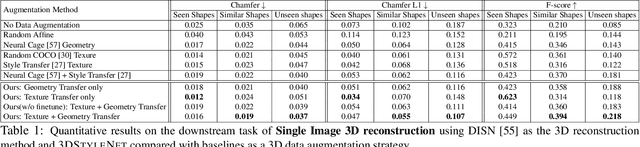
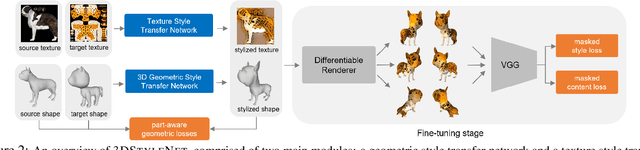
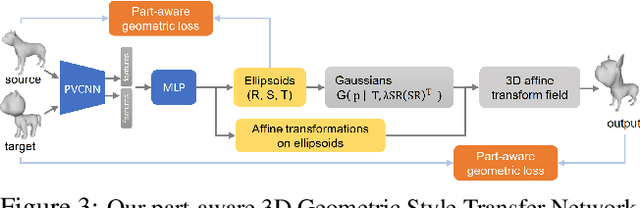
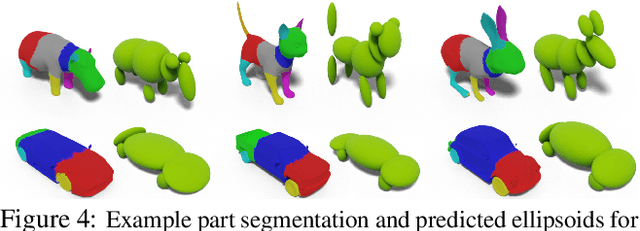
We propose a method to create plausible geometric and texture style variations of 3D objects in the quest to democratize 3D content creation. Given a pair of textured source and target objects, our method predicts a part-aware affine transformation field that naturally warps the source shape to imitate the overall geometric style of the target. In addition, the texture style of the target is transferred to the warped source object with the help of a multi-view differentiable renderer. Our model, 3DStyleNet, is composed of two sub-networks trained in two stages. First, the geometric style network is trained on a large set of untextured 3D shapes. Second, we jointly optimize our geometric style network and a pre-trained image style transfer network with losses defined over both the geometry and the rendering of the result. Given a small set of high-quality textured objects, our method can create many novel stylized shapes, resulting in effortless 3D content creation and style-ware data augmentation. We showcase our approach qualitatively on 3D content stylization, and provide user studies to validate the quality of our results. In addition, our method can serve as a valuable tool to create 3D data augmentations for computer vision tasks. Extensive quantitative analysis shows that 3DStyleNet outperforms alternative data augmentation techniques for the downstream task of single-image 3D reconstruction.
RePose: Learning Deep Kinematic Priors for Fast Human Pose Estimation
Feb 10, 2020
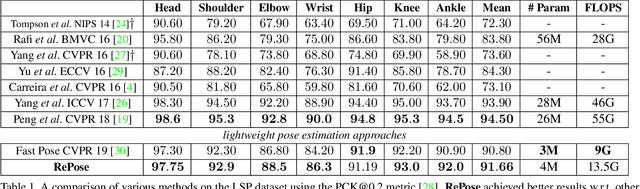
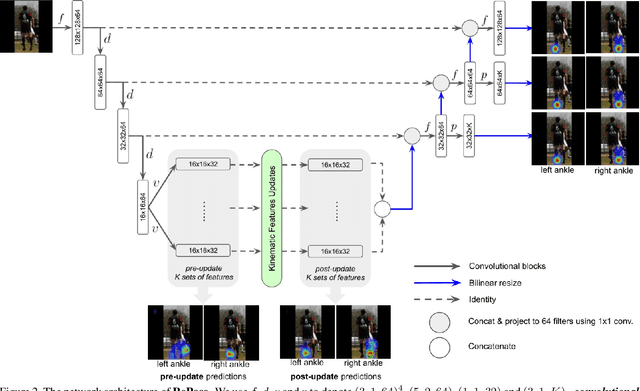
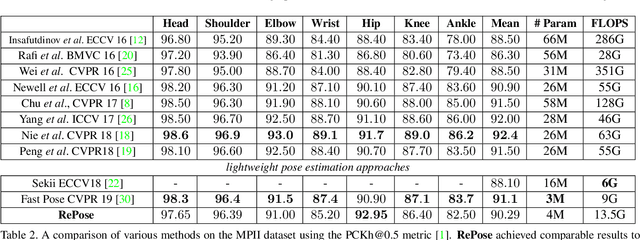
We propose a novel efficient and lightweight model for human pose estimation from a single image. Our model is designed to achieve competitive results at a fraction of the number of parameters and computational cost of various state-of-the-art methods. To this end, we explicitly incorporate part-based structural and geometric priors in a hierarchical prediction framework. At the coarsest resolution, and in a manner similar to classical part-based approaches, we leverage the kinematic structure of the human body to propagate convolutional feature updates between the keypoints or body parts. Unlike classical approaches, we adopt end-to-end training to learn this geometric prior through feature updates from data. We then propagate the feature representation at the coarsest resolution up the hierarchy to refine the predicted pose in a coarse-to-fine fashion. The final network effectively models the geometric prior and intuition within a lightweight deep neural network, yielding state-of-the-art results for a model of this size on two standard datasets, Leeds Sports Pose and MPII Human Pose.
Neural Rerendering in the Wild
Apr 08, 2019
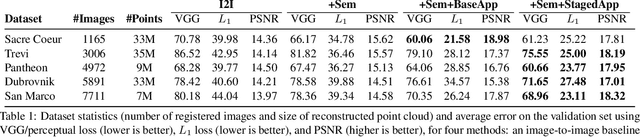

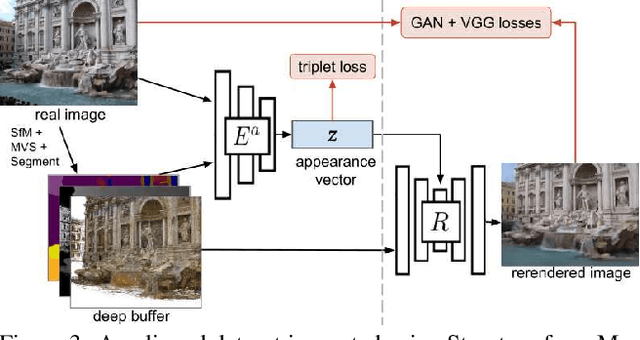
We explore total scene capture -- recording, modeling, and rerendering a scene under varying appearance such as season and time of day. Starting from internet photos of a tourist landmark, we apply traditional 3D reconstruction to register the photos and approximate the scene as a point cloud. For each photo, we render the scene points into a deep framebuffer, and train a neural network to learn the mapping of these initial renderings to the actual photos. This rerendering network also takes as input a latent appearance vector and a semantic mask indicating the location of transient objects like pedestrians. The model is evaluated on several datasets of publicly available images spanning a broad range of illumination conditions. We create short videos demonstrating realistic manipulation of the image viewpoint, appearance, and semantic labeling. We also compare results with prior work on scene reconstruction from internet photos.
LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering
Nov 12, 2018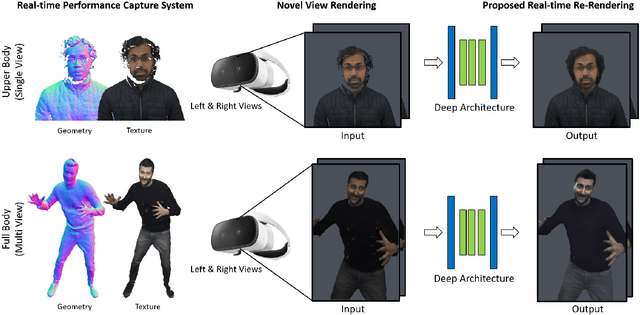



Motivated by augmented and virtual reality applications such as telepresence, there has been a recent focus in real-time performance capture of humans under motion. However, given the real-time constraint, these systems often suffer from artifacts in geometry and texture such as holes and noise in the final rendering, poor lighting, and low-resolution textures. We take the novel approach to augment such real-time performance capture systems with a deep architecture that takes a rendering from an arbitrary viewpoint, and jointly performs completion, super resolution, and denoising of the imagery in real-time. We call this approach neural (re-)rendering, and our live system "LookinGood". Our deep architecture is trained to produce high resolution and high quality images from a coarse rendering in real-time. First, we propose a self-supervised training method that does not require manual ground-truth annotation. We contribute a specialized reconstruction error that uses semantic information to focus on relevant parts of the subject, e.g. the face. We also introduce a salient reweighing scheme of the loss function that is able to discard outliers. We specifically design the system for virtual and augmented reality headsets where the consistency between the left and right eye plays a crucial role in the final user experience. Finally, we generate temporally stable results by explicitly minimizing the difference between two consecutive frames. We tested the proposed system in two different scenarios: one involving a single RGB-D sensor, and upper body reconstruction of an actor, the second consisting of full body 360 degree capture. Through extensive experimentation, we demonstrate how our system generalizes across unseen sequences and subjects. The supplementary video is available at http://youtu.be/Md3tdAKoLGU.
StereoNet: Guided Hierarchical Refinement for Real-Time Edge-Aware Depth Prediction
Jul 24, 2018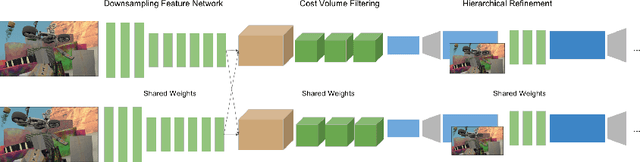
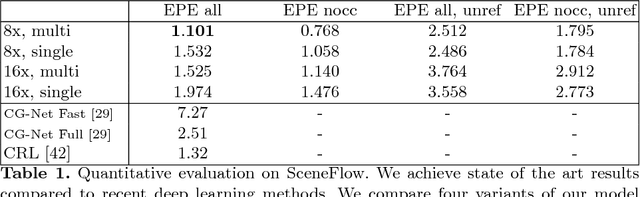
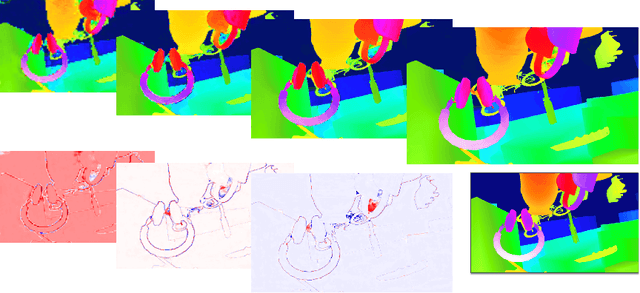
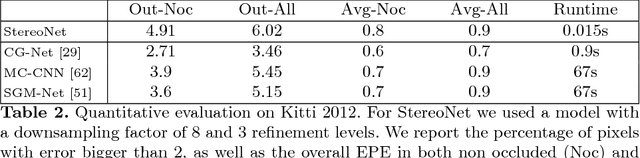
This paper presents StereoNet, the first end-to-end deep architecture for real-time stereo matching that runs at 60 fps on an NVidia Titan X, producing high-quality, edge-preserved, quantization-free disparity maps. A key insight of this paper is that the network achieves a sub-pixel matching precision than is a magnitude higher than those of traditional stereo matching approaches. This allows us to achieve real-time performance by using a very low resolution cost volume that encodes all the information needed to achieve high disparity precision. Spatial precision is achieved by employing a learned edge-aware upsampling function. Our model uses a Siamese network to extract features from the left and right image. A first estimate of the disparity is computed in a very low resolution cost volume, then hierarchically the model re-introduces high-frequency details through a learned upsampling function that uses compact pixel-to-pixel refinement networks. Leveraging color input as a guide, this function is capable of producing high-quality edge-aware output. We achieve compelling results on multiple benchmarks, showing how the proposed method offers extreme flexibility at an acceptable computational budget.
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems
Jul 16, 2018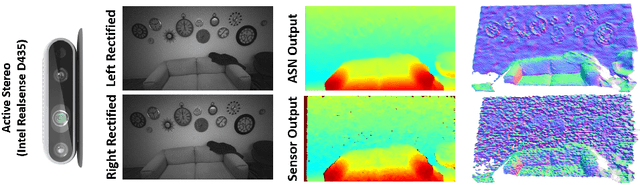
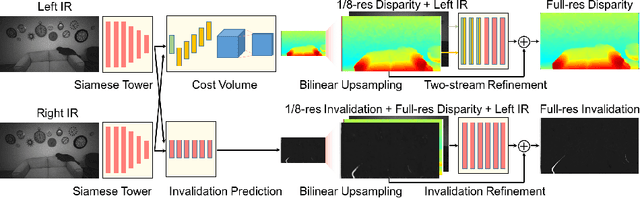

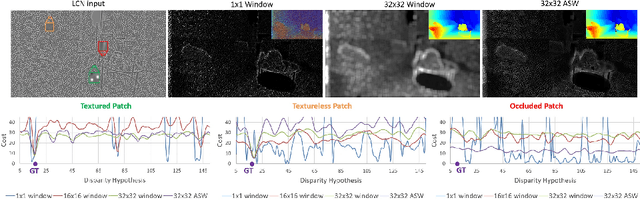
In this paper we present ActiveStereoNet, the first deep learning solution for active stereo systems. Due to the lack of ground truth, our method is fully self-supervised, yet it produces precise depth with a subpixel precision of $1/30th$ of a pixel; it does not suffer from the common over-smoothing issues; it preserves the edges; and it explicitly handles occlusions. We introduce a novel reconstruction loss that is more robust to noise and texture-less patches, and is invariant to illumination changes. The proposed loss is optimized using a window-based cost aggregation with an adaptive support weight scheme. This cost aggregation is edge-preserving and smooths the loss function, which is key to allow the network to reach compelling results. Finally we show how the task of predicting invalid regions, such as occlusions, can be trained end-to-end without ground-truth. This component is crucial to reduce blur and particularly improves predictions along depth discontinuities. Extensive quantitatively and qualitatively evaluations on real and synthetic data demonstrate state of the art results in many challenging scenes.
Parameterizing Region Covariance: An Efficient Way To Apply Sparse Codes On Second Order Statistics
Feb 09, 2016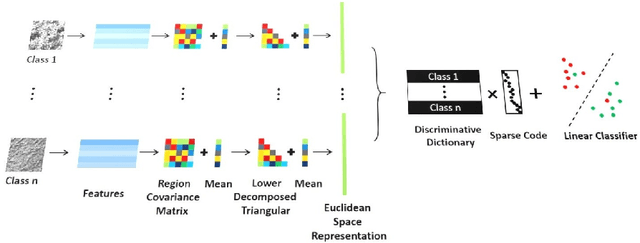
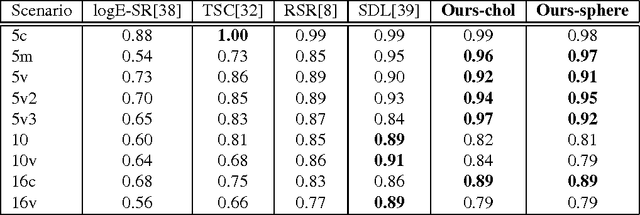

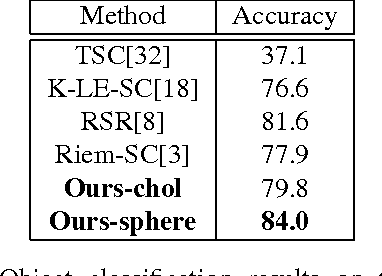
Sparse representations have been successfully applied to signal processing, computer vision and machine learning. Currently there is a trend to learn sparse models directly on structure data, such as region covariance. However, such methods when combined with region covariance often require complex computation. We present an approach to transform a structured sparse model learning problem to a traditional vectorized sparse modeling problem by constructing a Euclidean space representation for region covariance matrices. Our new representation has multiple advantages. Experiments on several vision tasks demonstrate competitive performance with the state-of-the-art methods.