 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCefdet: Cognitive Effectiveness Network Based on Fuzzy Inference for Action Detection
Oct 08, 2024



Action detection and understanding provide the foundation for the generation and interaction of multimedia content. However, existing methods mainly focus on constructing complex relational inference networks, overlooking the judgment of detection effectiveness. Moreover, these methods frequently generate detection results with cognitive abnormalities. To solve the above problems, this study proposes a cognitive effectiveness network based on fuzzy inference (Cefdet), which introduces the concept of "cognition-based detection" to simulate human cognition. First, a fuzzy-driven cognitive effectiveness evaluation module (FCM) is established to introduce fuzzy inference into action detection. FCM is combined with human action features to simulate the cognition-based detection process, which clearly locates the position of frames with cognitive abnormalities. Then, a fuzzy cognitive update strategy (FCS) is proposed based on the FCM, which utilizes fuzzy logic to re-detect the cognition-based detection results and effectively update the results with cognitive abnormalities. Experimental results demonstrate that Cefdet exhibits superior performance against several mainstream algorithms on the public datasets, validating its effectiveness and superiority.
HazeSpace2M: A Dataset for Haze Aware Single Image Dehazing
Sep 25, 2024



Reducing the atmospheric haze and enhancing image clarity is crucial for computer vision applications. The lack of real-life hazy ground truth images necessitates synthetic datasets, which often lack diverse haze types, impeding effective haze type classification and dehazing algorithm selection. This research introduces the HazeSpace2M dataset, a collection of over 2 million images designed to enhance dehazing through haze type classification. HazeSpace2M includes diverse scenes with 10 haze intensity levels, featuring Fog, Cloud, and Environmental Haze (EH). Using the dataset, we introduce a technique of haze type classification followed by specialized dehazers to clear hazy images. Unlike conventional methods, our approach classifies haze types before applying type-specific dehazing, improving clarity in real-life hazy images. Benchmarking with state-of-the-art (SOTA) models, ResNet50 and AlexNet achieve 92.75\% and 92.50\% accuracy, respectively, against existing synthetic datasets. However, these models achieve only 80% and 70% accuracy, respectively, against our Real Hazy Testset (RHT), highlighting the challenging nature of our HazeSpace2M dataset. Additional experiments show that haze type classification followed by specialized dehazing improves results by 2.41% in PSNR, 17.14% in SSIM, and 10.2\% in MSE over general dehazers. Moreover, when testing with SOTA dehazing models, we found that applying our proposed framework significantly improves their performance. These results underscore the significance of HazeSpace2M and our proposed framework in addressing atmospheric haze in multimedia processing. Complete code and dataset is available on \href{https://github.com/tanvirnwu/HazeSpace2M} {\textcolor{blue}{\textbf{GitHub}}}.
* Accepted by ACM Multimedia 2024
Adversarial Attacks Assessment of Salient Object Detection via Symbolic Learning
Sep 12, 2023Machine learning is at the center of mainstream technology and outperforms classical approaches to handcrafted feature design. Aside from its learning process for artificial feature extraction, it has an end-to-end paradigm from input to output, reaching outstandingly accurate results. However, security concerns about its robustness to malicious and imperceptible perturbations have drawn attention since its prediction can be changed entirely. Salient object detection is a research area where deep convolutional neural networks have proven effective but whose trustworthiness represents a significant issue requiring analysis and solutions to hackers' attacks. Brain programming is a kind of symbolic learning in the vein of good old-fashioned artificial intelligence. This work provides evidence that symbolic learning robustness is crucial in designing reliable visual attention systems since it can withstand even the most intense perturbations. We test this evolutionary computation methodology against several adversarial attacks and noise perturbations using standard databases and a real-world problem of a shorebird called the Snowy Plover portraying a visual attention task. We compare our methodology with five different deep learning approaches, proving that they do not match the symbolic paradigm regarding robustness. All neural networks suffer significant performance losses, while brain programming stands its ground and remains unaffected. Also, by studying the Snowy Plover, we remark on the importance of security in surveillance activities regarding wildlife protection and conservation.
Localization of Unmanned Aerial Vehicles in Corridor Environments using Deep Learning
Mar 21, 2019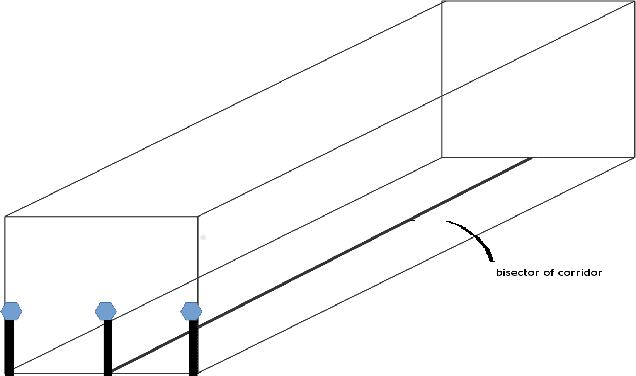
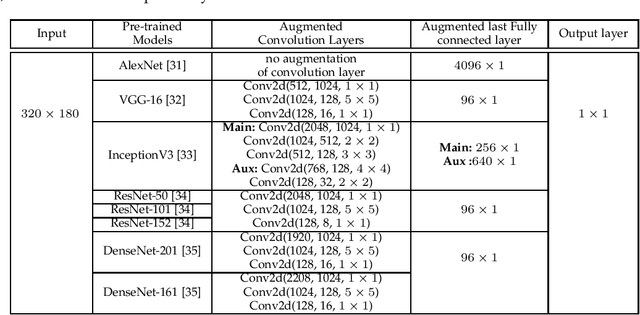

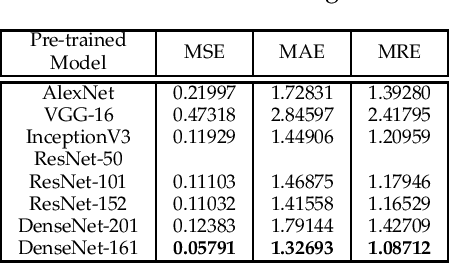
Vision-based pose estimation of Unmanned Aerial Vehicles (UAV) in unknown environments is a rapidly growing research area in the field of robot vision. The task becomes more complex when the only available sensor is a static single camera (monocular vision). In this regard, we propose a monocular vision assisted localization algorithm, that will help a UAV to navigate safely in indoor corridor environments. Always, the aim is to navigate the UAV through a corridor in the forward direction by keeping it at the center with no orientation either to the left or right side. The algorithm makes use of the RGB image, captured from the UAV front camera, and passes it through a trained deep neural network (DNN) to predict the position of the UAV as either on the left or center or right side of the corridor. Depending upon the divergence of the UAV with respect to the central bisector line (CBL) of the corridor, a suitable command is generated to bring the UAV to the center. When the UAV is at the center of the corridor, a new image is passed through another trained DNN to predict the orientation of the UAV with respect to the CBL of the corridor. If the UAV is either left or right tilted, an appropriate command is generated to rectify the orientation. We also propose a new corridor dataset, named NITRCorrV1, which contains images as captured by the UAV front camera when the UAV is at all possible locations of a variety of corridors. An exhaustive set of experiments in different corridors reveal the efficacy of the proposed algorithm.
The Unconstrained Ear Recognition Challenge 2019 - ArXiv Version With Appendix
Mar 14, 2019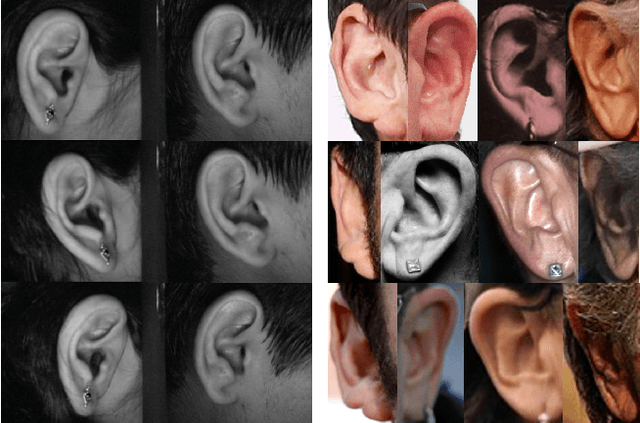

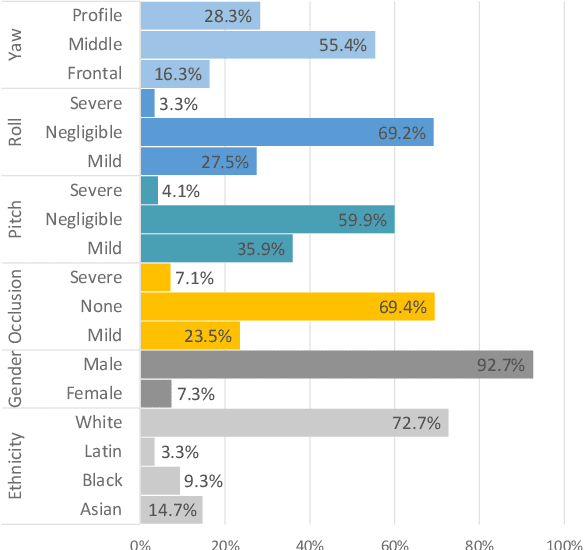
This paper presents a summary of the 2019 Unconstrained Ear Recognition Challenge (UERC), the second in a series of group benchmarking efforts centered around the problem of person recognition from ear images captured in uncontrolled settings. The goal of the challenge is to assess the performance of existing ear recognition techniques on a challenging large-scale ear dataset and to analyze performance of the technology from various viewpoints, such as generalization abilities to unseen data characteristics, sensitivity to rotations, occlusions and image resolution and performance bias on sub-groups of subjects, selected based on demographic criteria, i.e. gender and ethnicity. Research groups from 12 institutions entered the competition and submitted a total of 13 recognition approaches ranging from descriptor-based methods to deep-learning models. The majority of submissions focused on ensemble based methods combining either representations from multiple deep models or hand-crafted with learned image descriptors. Our analysis shows that methods incorporating deep learning models clearly outperform techniques relying solely on hand-crafted descriptors, even though both groups of techniques exhibit similar behaviour when it comes to robustness to various covariates, such presence of occlusions, changes in (head) pose, or variability in image resolution. The results of the challenge also show that there has been considerable progress since the first UERC in 2017, but that there is still ample room for further research in this area.
Forensic Shoe-print Identification: A Brief Survey
Jan 05, 2019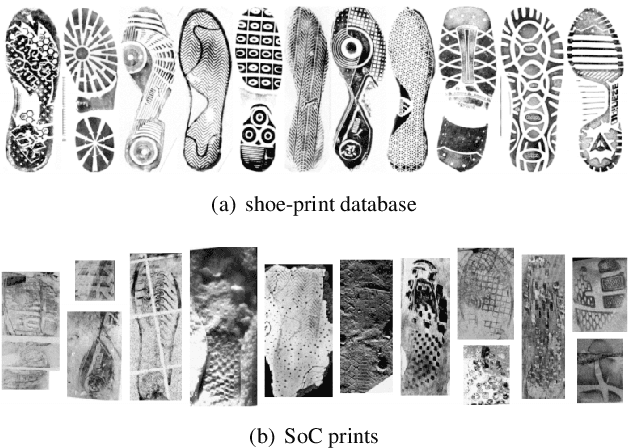
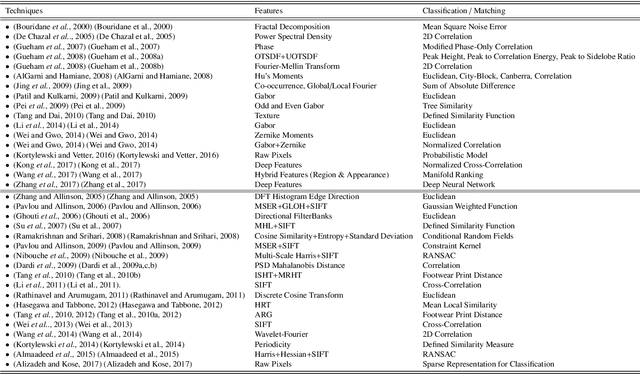
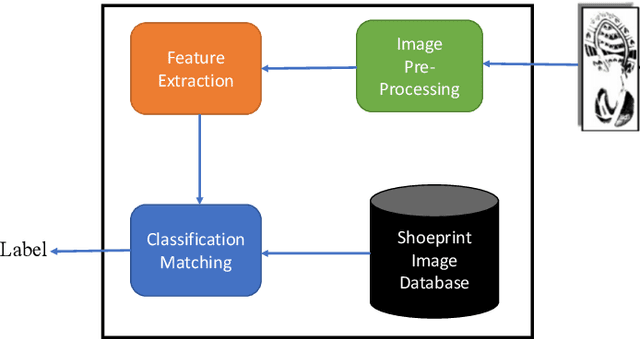
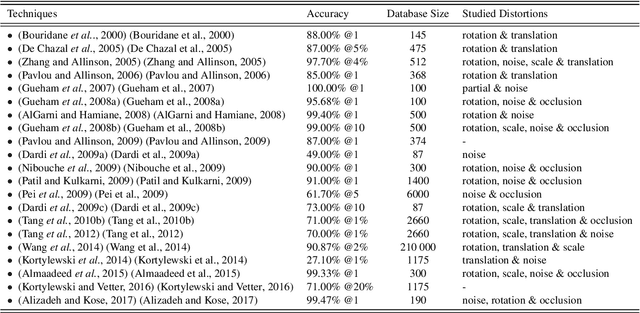
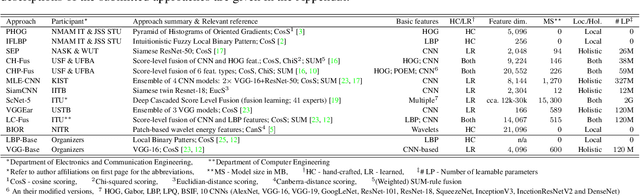
As an advanced research topic in forensics science, automatic shoe-print identification has been extensively studied in the last two decades, since shoe marks are the clues most frequently left in a crime scene. Hence, these impressions provide a pertinent evidence for the proper progress of investigations in order to identify the potential criminals. The main goal of this survey is to provide a cohesive overview of the research carried out in forensic shoe-print identification and its basic background. Apart defining the problem and describing the phases that typically compose the processing chain of shoe-print identification, we provide a summary/comparison of the state-of-the-art approaches, in order to guide the neophyte and help to advance the research topic. This is done through introducing simple and basic taxonomies as well as summaries of the state-of-the-art performance. Lastly, we discuss the current open problems and challenges in this research topic, point out for promising directions in this field.
Stratified SIFT Matching for Human Iris Recognition
Jan 06, 2013

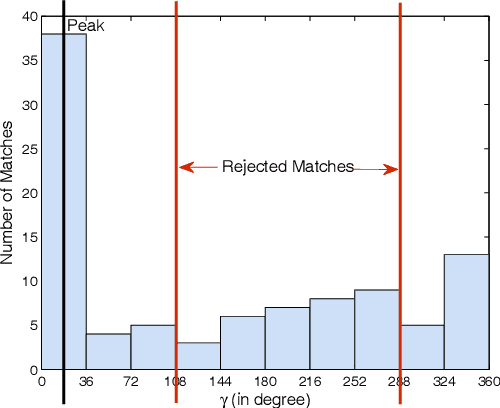
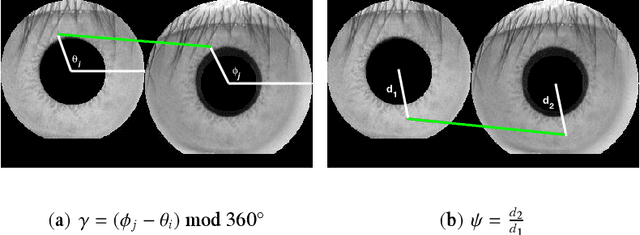
This paper proposes an efficient three fold stratified SIFT matching for iris recognition. The objective is to filter wrongly paired conventional SIFT matches. In Strata I, the keypoints from gallery and probe iris images are paired using traditional SIFT approach. Due to high image similarity at different regions of iris there may be some impairments. These are detected and filtered by finding gradient of paired keypoints in Strata II. Further, the scaling factor of paired keypoints is used to remove impairments in Strata III. The pairs retained after Strata III are likely to be potential matches for iris recognition. The proposed system performs with an accuracy of 96.08% and 97.15% on publicly available CASIAV3 and BATH databases respectively. This marks significant improvement of accuracy and FAR over the existing SIFT matching for iris.
* 7 pages