 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvSurf: a partially monotonic neural network for first-hitting time prediction of intermittently observed discrete and continuous sequential events
Apr 07, 2025



We propose a neural-network based survival model (SurvSurf) specifically designed for direct and simultaneous probabilistic prediction of the first hitting time of sequential events from baseline. Unlike existing models, SurvSurf is theoretically guaranteed to never violate the monotonic relationship between the cumulative incidence functions of sequential events, while allowing nonlinear influence from predictors. It also incorporates implicit truths for unobserved intermediate events in model fitting, and supports both discrete and continuous time and events. We also identified a variant of the Integrated Brier Score (IBS) that showed robust correlation with the mean squared error (MSE) between the true and predicted probabilities by accounting for implied truths about the missing intermediate events. We demonstrated the superiority of SurvSurf compared to modern and traditional predictive survival models in two simulated datasets and two real-world datasets, using MSE, the more robust IBS and by measuring the extent of monotonicity violation.
A study on the adequacy of common IQA measures for medical images
May 29, 2024



Image quality assessment (IQA) is standard practice in the development stage of novel machine learning algorithms that operate on images. The most commonly used IQA measures have been developed and tested for natural images, but not in the medical setting. Reported inconsistencies arising in medical images are not surprising, as they have different properties than natural images. In this study, we test the applicability of common IQA measures for medical image data by comparing their assessment to manually rated chest X-ray (5 experts) and photoacoustic image data (1 expert). Moreover, we include supplementary studies on grayscale natural images and accelerated brain MRI data. The results of all experiments show a similar outcome in line with previous findings for medical imaging: PSNR and SSIM in the default setting are in the lower range of the result list and HaarPSI outperforms the other tested measures in the overall performance. Also among the top performers in our medical experiments are the full reference measures DISTS, FSIM, LPIPS and MS-SSIM. Generally, the results on natural images yield considerably higher correlations, suggesting that the additional employment of tailored IQA measures for medical imaging algorithms is needed.
FedMAP: Unlocking Potential in Personalized Federated Learning through Bi-Level MAP Optimization
May 29, 2024



Federated Learning (FL) enables collaborative training of machine learning models on decentralized data while preserving data privacy. However, data across clients often differs significantly due to class imbalance, feature distribution skew, sample size imbalance, and other phenomena. Leveraging information from these not identically distributed (non-IID) datasets poses substantial challenges. FL methods based on a single global model cannot effectively capture the variations in client data and underperform in non-IID settings. Consequently, Personalized FL (PFL) approaches that adapt to each client's data distribution but leverage other clients' data are essential but currently underexplored. We propose a novel Bayesian PFL framework using bi-level optimization to tackle the data heterogeneity challenges. Our proposed framework utilizes the global model as a prior distribution within a Maximum A Posteriori (MAP) estimation of personalized client models. This approach facilitates PFL by integrating shared knowledge from the prior, thereby enhancing local model performance, generalization ability, and communication efficiency. We extensively evaluated our bi-level optimization approach on real-world and synthetic datasets, demonstrating significant improvements in model accuracy compared to existing methods while reducing communication overhead. This study contributes to PFL by establishing a solid theoretical foundation for the proposed method and offering a robust, ready-to-use framework that effectively addresses the challenges posed by non-IID data in FL.
A study of why we need to reassess full reference image quality assessment with medical images
May 29, 2024



Image quality assessment (IQA) is not just indispensable in clinical practice to ensure high standards, but also in the development stage of novel algorithms that operate on medical images with reference data. This paper provides a structured and comprehensive collection of examples where the two most common full reference (FR) image quality measures prove to be unsuitable for the assessment of novel algorithms using different kinds of medical images, including real-world MRI, CT, OCT, X-Ray, digital pathology and photoacoustic imaging data. In particular, the FR-IQA measures PSNR and SSIM are known and tested for working successfully in many natural imaging tasks, but discrepancies in medical scenarios have been noted in the literature. Inconsistencies arising in medical images are not surprising, as they have very different properties than natural images which have not been targeted nor tested in the development of the mentioned measures, and therefore might imply wrong judgement of novel methods for medical images. Therefore, improvement is urgently needed in particular in this era of AI to increase explainability, reproducibility and generalizability in machine learning for medical imaging and beyond. On top of the pitfalls we will provide ideas for future research as well as suggesting guidelines for the usage of FR-IQA measures applied to medical images.
The curious case of the test set AUROC
Dec 19, 2023



Whilst the size and complexity of ML models have rapidly and significantly increased over the past decade, the methods for assessing their performance have not kept pace. In particular, among the many potential performance metrics, the ML community stubbornly continues to use (a) the area under the receiver operating characteristic curve (AUROC) for a validation and test cohort (distinct from training data) or (b) the sensitivity and specificity for the test data at an optimal threshold determined from the validation ROC. However, we argue that considering scores derived from the test ROC curve alone gives only a narrow insight into how a model performs and its ability to generalise.
Recent Methodological Advances in Federated Learning for Healthcare
Oct 04, 2023



For healthcare datasets, it is often not possible to combine data samples from multiple sites due to ethical, privacy or logistical concerns. Federated learning allows for the utilisation of powerful machine learning algorithms without requiring the pooling of data. Healthcare data has many simultaneous challenges which require new methodologies to address, such as highly-siloed data, class imbalance, missing data, distribution shifts and non-standardised variables. Federated learning adds significant methodological complexity to conventional centralised machine learning, requiring distributed optimisation, communication between nodes, aggregation of models and redistribution of models. In this systematic review, we consider all papers on Scopus that were published between January 2015 and February 2023 and which describe new federated learning methodologies for addressing challenges with healthcare data. We performed a detailed review of the 89 papers which fulfilled these criteria. Significant systemic issues were identified throughout the literature which compromise the methodologies in many of the papers reviewed. We give detailed recommendations to help improve the quality of the methodology development for federated learning in healthcare.
Reinterpreting survival analysis in the universal approximator age
Jul 25, 2023



Survival analysis is an integral part of the statistical toolbox. However, while most domains of classical statistics have embraced deep learning, survival analysis only recently gained some minor attention from the deep learning community. This recent development is likely in part motivated by the COVID-19 pandemic. We aim to provide the tools needed to fully harness the potential of survival analysis in deep learning. On the one hand, we discuss how survival analysis connects to classification and regression. On the other hand, we provide technical tools. We provide a new loss function, evaluation metrics, and the first universal approximating network that provably produces survival curves without numeric integration. We show that the loss function and model outperform other approaches using a large numerical study.
SELTO: Sample-Efficient Learned Topology Optimization
Sep 12, 2022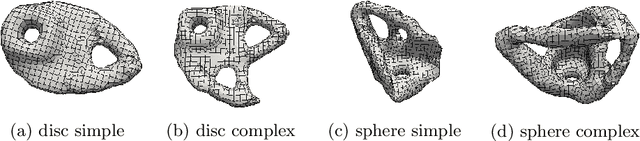
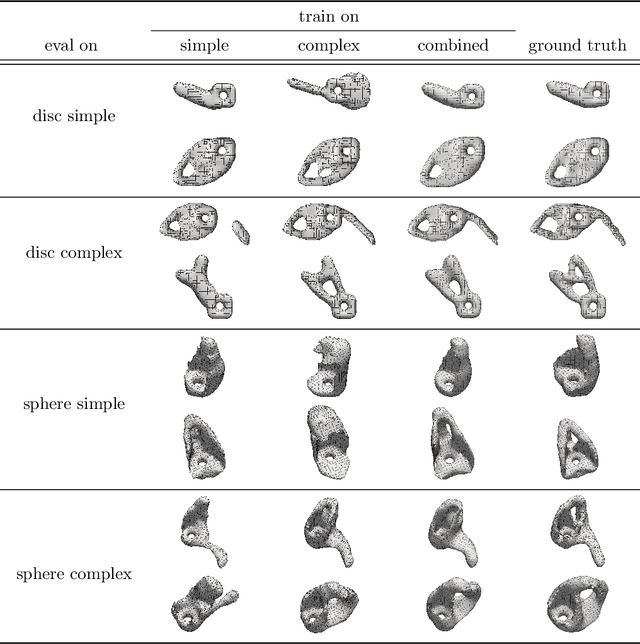
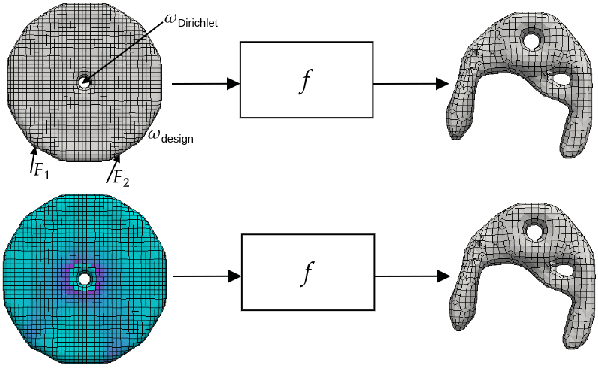
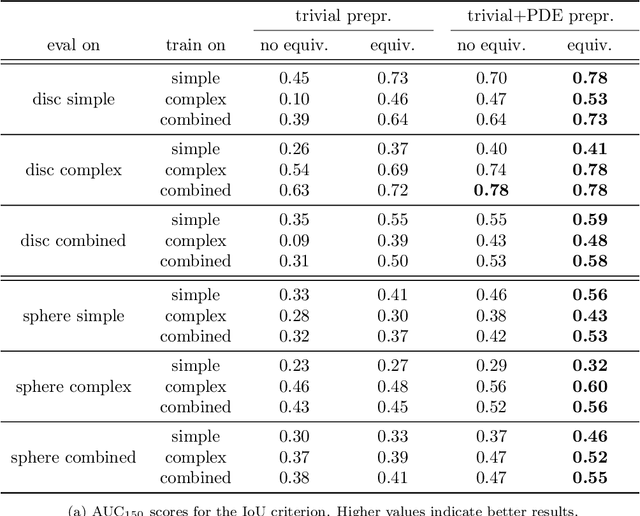
We present a sample-efficient deep learning strategy for topology optimization. Our end-to-end approach is supervised and includes physics-based preprocessing and equivariant networks. We analyze how different components of our deep learning pipeline influence the number of required training samples via a large-scale comparison. The results demonstrate that including physical concepts not only drastically improves the sample efficiency but also the predictions' physical correctness. Finally, we publish two topology optimization datasets containing problems and corresponding ground truth solutions. We are confident that these datasets will improve comparability and future progress in the field.
Classification of datasets with imputed missing values: does imputation quality matter?
Jun 16, 2022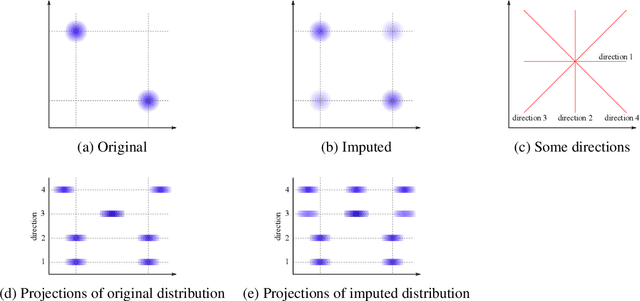


Classifying samples in incomplete datasets is a common aim for machine learning practitioners, but is non-trivial. Missing data is found in most real-world datasets and these missing values are typically imputed using established methods, followed by classification of the now complete, imputed, samples. The focus of the machine learning researcher is then to optimise the downstream classification performance. In this study, we highlight that it is imperative to consider the quality of the imputation. We demonstrate how the commonly used measures for assessing quality are flawed and propose a new class of discrepancy scores which focus on how well the method recreates the overall distribution of the data. To conclude, we highlight the compromised interpretability of classifier models trained using poorly imputed data.
Unsupervised Learning of the Total Variation Flow
Jun 09, 2022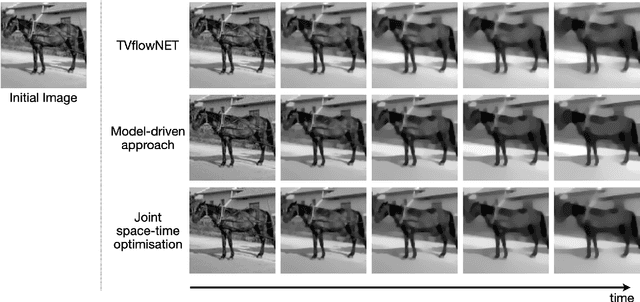

The total variation (TV) flow generates a scale-space representation of an image based on the TV functional. This gradient flow observes desirable features for images such as sharp edges and enables spectral, scale, and texture analysis. The standard numerical approach for TV flow requires solving multiple non-smooth optimisation problems. Even with state-of-the-art convex optimisation techniques, this is often prohibitively expensive and strongly motivates the use of alternative, faster approaches. Inspired by and extending the framework of physics-informed neural networks (PINNs), we propose the TVflowNET, a neural network approach to compute the solution of the TV flow given an initial image and a time instance. We significantly speed up the computation time by more than one order of magnitude and show that the TVflowNET approximates the TV flow solution with high fidelity. This is a preliminary report, more details are to follow.