 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Inductive Bias of Neural Language Models with Artificial Languages
Jun 02, 2021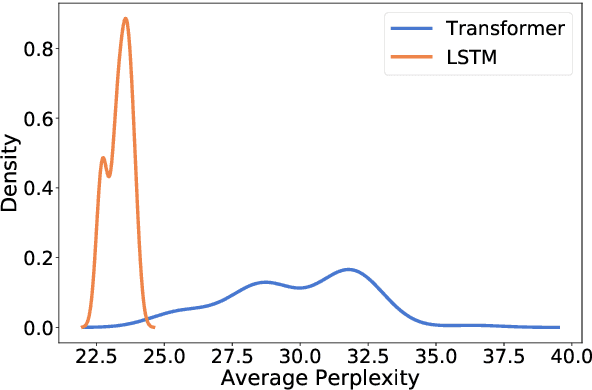

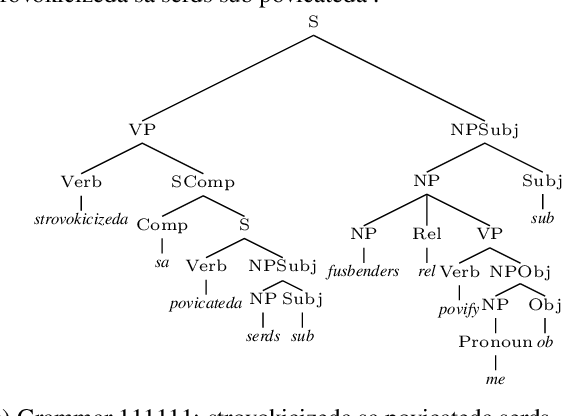

Since language models are used to model a wide variety of languages, it is natural to ask whether the neural architectures used for the task have inductive biases towards modeling particular types of languages. Investigation of these biases has proved complicated due to the many variables that appear in the experimental setup. Languages vary in many typological dimensions, and it is difficult to single out one or two to investigate without the others acting as confounders. We propose a novel method for investigating the inductive biases of language models using artificial languages. These languages are constructed to allow us to create parallel corpora across languages that differ only in the typological feature being investigated, such as word order. We then use them to train and test language models. This constitutes a fully controlled causal framework, and demonstrates how grammar engineering can serve as a useful tool for analyzing neural models. Using this method, we find that commonly used neural architectures exhibit different inductive biases: LSTMs display little preference with respect to word ordering, while transformers display a clear preference for some orderings over others. Further, we find that neither the inductive bias of the LSTM nor that of the transformer appears to reflect any tendencies that we see in attested natural languages.
Language Model Evaluation Beyond Perplexity
Jun 02, 2021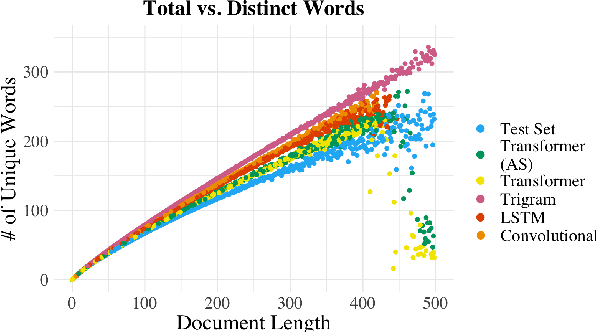
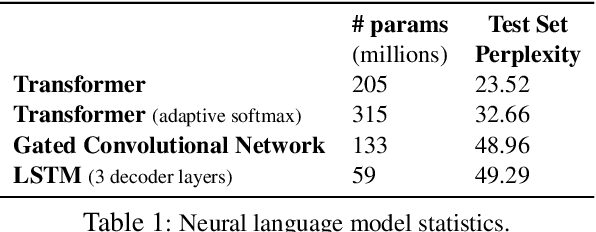
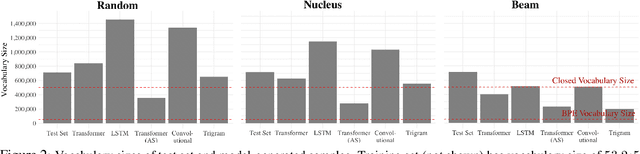
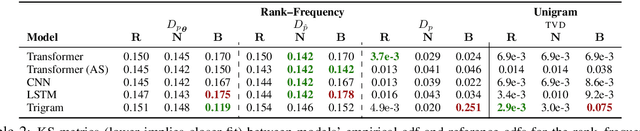
We propose an alternate approach to quantifying how well language models learn natural language: we ask how well they match the statistical tendencies of natural language. To answer this question, we analyze whether text generated from language models exhibits the statistical tendencies present in the human-generated text on which they were trained. We provide a framework--paired with significance tests--for evaluating the fit of language models to these trends. We find that neural language models appear to learn only a subset of the tendencies considered, but align much more closely with empirical trends than proposed theoretical distributions (when present). Further, the fit to different distributions is highly-dependent on both model architecture and generation strategy. As concrete examples, text generated under the nucleus sampling scheme adheres more closely to the type--token relationship of natural language than text produced using standard ancestral sampling; text from LSTMs reflects the natural language distributions over length, stopwords, and symbols surprisingly well.
On Finding the $K$-best Non-projective Dependency Trees
Jun 01, 2021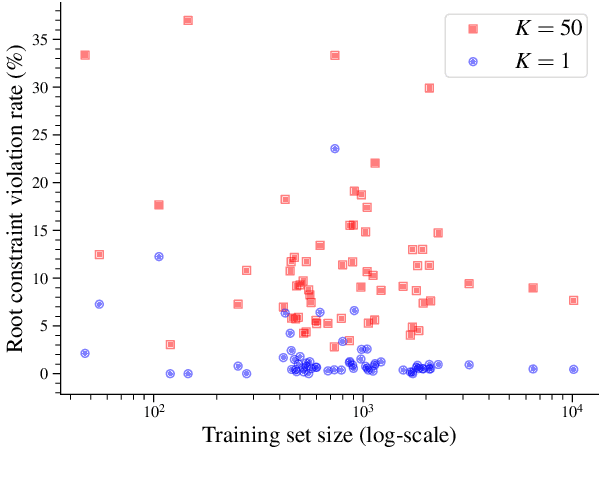
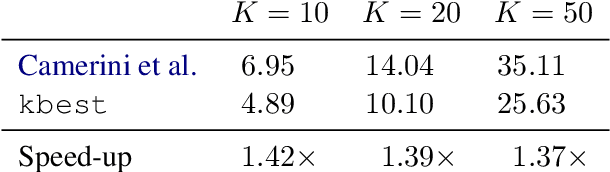
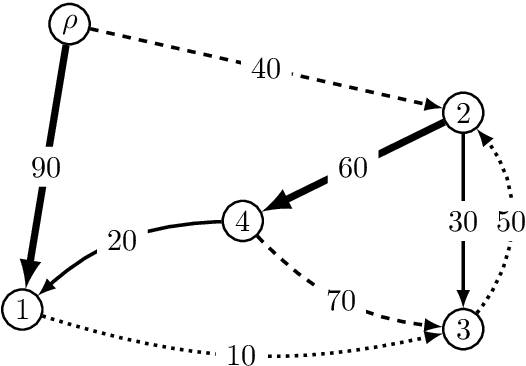

The connection between the maximum spanning tree in a directed graph and the best dependency tree of a sentence has been exploited by the NLP community. However, for many dependency parsing schemes, an important detail of this approach is that the spanning tree must have exactly one edge emanating from the root. While work has been done to efficiently solve this problem for finding the one-best dependency tree, no research has attempted to extend this solution to finding the $K$-best dependency trees. This is arguably a more important extension as a larger proportion of decoded trees will not be subject to the root constraint of dependency trees. Indeed, we show that the rate of root constraint violations increases by an average of $13$ times when decoding with $K\!=\!50$ as opposed to $K\!=\!1$. In this paper, we provide a simplification of the $K$-best spanning tree algorithm of Camerini et al. (1980). Our simplification allows us to obtain a constant time speed-up over the original algorithm. Furthermore, we present a novel extension of the algorithm for decoding the $K$-best dependency trees of a graph which are subject to a root constraint.
Higher-order Derivatives of Weighted Finite-state Machines
Jun 01, 2021
Weighted finite-state machines are a fundamental building block of NLP systems. They have withstood the test of time -- from their early use in noisy channel models in the 1990s up to modern-day neurally parameterized conditional random fields. This work examines the computation of higher-order derivatives with respect to the normalization constant for weighted finite-state machines. We provide a general algorithm for evaluating derivatives of all orders, which has not been previously described in the literature. In the case of second-order derivatives, our scheme runs in the optimal $\mathcal{O}(A^2 N^4)$ time where $A$ is the alphabet size and $N$ is the number of states. Our algorithm is significantly faster than prior algorithms. Additionally, our approach leads to a significantly faster algorithm for computing second-order expectations, such as covariance matrices and gradients of first-order expectations.
A Non-Linear Structural Probe
May 21, 2021
Probes are models devised to investigate the encoding of knowledge -- e.g. syntactic structure -- in contextual representations. Probes are often designed for simplicity, which has led to restrictions on probe design that may not allow for the full exploitation of the structure of encoded information; one such restriction is linearity. We examine the case of a structural probe (Hewitt and Manning, 2019), which aims to investigate the encoding of syntactic structure in contextual representations through learning only linear transformations. By observing that the structural probe learns a metric, we are able to kernelize it and develop a novel non-linear variant with an identical number of parameters. We test on 6 languages and find that the radial-basis function (RBF) kernel, in conjunction with regularization, achieves a statistically significant improvement over the baseline in all languages -- implying that at least part of the syntactic knowledge is encoded non-linearly. We conclude by discussing how the RBF kernel resembles BERT's self-attention layers and speculate that this resemblance leads to the RBF-based probe's stronger performance.
How (Non-)Optimal is the Lexicon?
Apr 30, 2021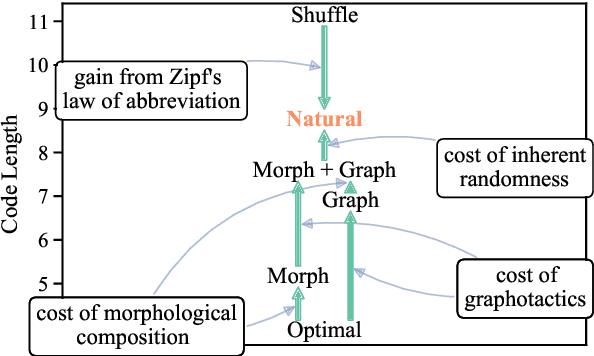
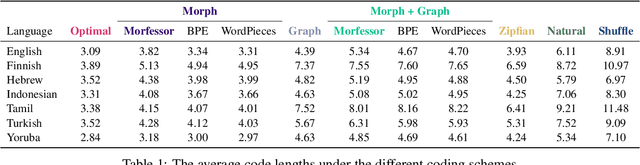
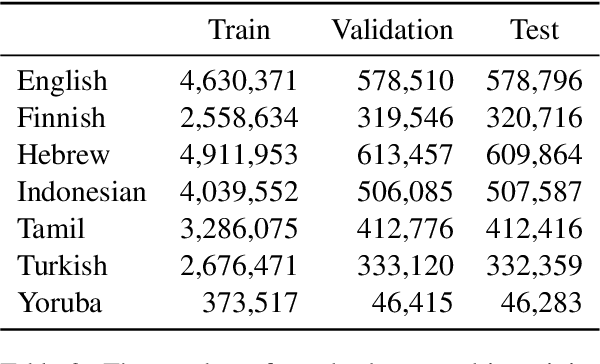
The mapping of lexical meanings to wordforms is a major feature of natural languages. While usage pressures might assign short words to frequent meanings (Zipf's law of abbreviation), the need for a productive and open-ended vocabulary, local constraints on sequences of symbols, and various other factors all shape the lexicons of the world's languages. Despite their importance in shaping lexical structure, the relative contributions of these factors have not been fully quantified. Taking a coding-theoretic view of the lexicon and making use of a novel generative statistical model, we define upper bounds for the compressibility of the lexicon under various constraints. Examining corpora from 7 typologically diverse languages, we use those upper bounds to quantify the lexicon's optimality and to explore the relative costs of major constraints on natural codes. We find that (compositional) morphology and graphotactics can sufficiently account for most of the complexity of natural codes -- as measured by code length.
Finding Concept-specific Biases in Form--Meaning Associations
Apr 29, 2021
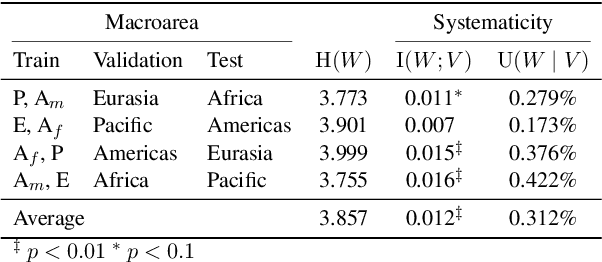
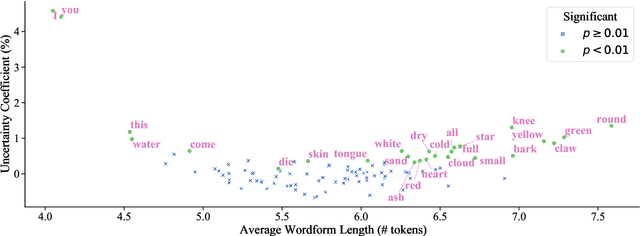
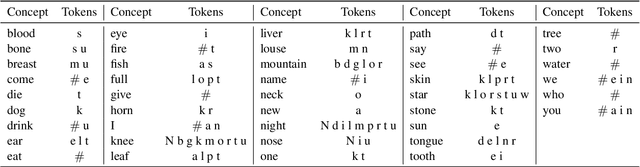
This work presents an information-theoretic operationalisation of cross-linguistic non-arbitrariness. It is not a new idea that there are small, cross-linguistic associations between the forms and meanings of words. For instance, it has been claimed (Blasi et al., 2016) that the word for "tongue" is more likely than chance to contain the phone [l]. By controlling for the influence of language family and geographic proximity within a very large concept-aligned, cross-lingual lexicon, we extend methods previously used to detect within language non-arbitrariness (Pimentel et al., 2019) to measure cross-linguistic associations. We find that there is a significant effect of non-arbitrariness, but it is unsurprisingly small (less than 0.5% on average according to our information-theoretic estimate). We also provide a concept-level analysis which shows that a quarter of the concepts considered in our work exhibit a significant level of cross-linguistic non-arbitrariness. In sum, the paper provides new methods to detect cross-linguistic associations at scale, and confirms their effects are minor.
Quantifying Gender Bias Towards Politicians in Cross-Lingual Language Models
Apr 15, 2021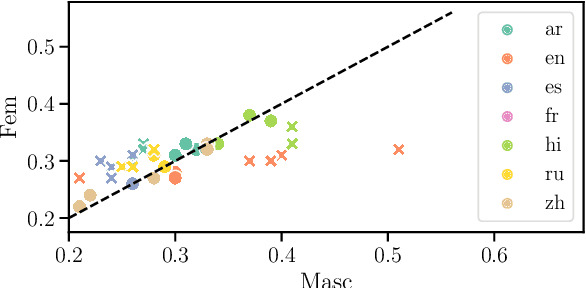
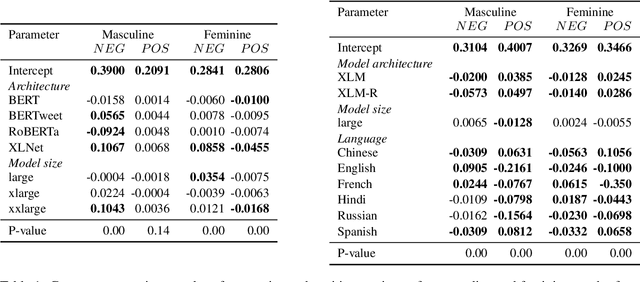
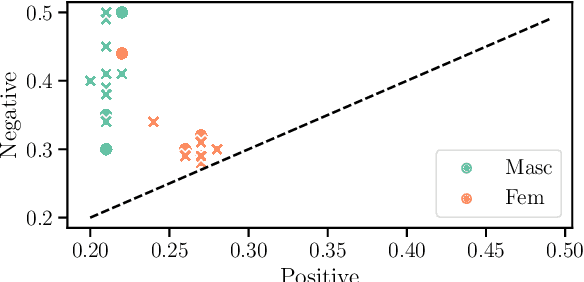

While the prevalence of large pre-trained language models has led to significant improvements in the performance of NLP systems, recent research has demonstrated that these models inherit societal biases extant in natural language. In this paper, we explore a simple method to probe pre-trained language models for gender bias, which we use to effect a multi-lingual study of gender bias towards politicians. We construct a dataset of 250k politicians from most countries in the world and quantify adjective and verb usage around those politicians' names as a function of their gender. We conduct our study in 7 languages across 6 different language modeling architectures. Our results demonstrate that stance towards politicians in pre-trained language models is highly dependent on the language used. Finally, contrary to previous findings, our study suggests that larger language models do not tend to be significantly more gender-biased than smaller ones.
Searching for Search Errors in Neural Morphological Inflection
Feb 16, 2021
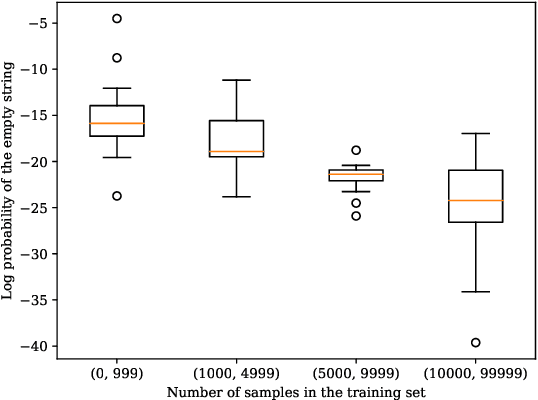

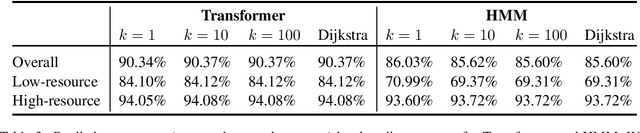
Neural sequence-to-sequence models are currently the predominant choice for language generation tasks. Yet, on word-level tasks, exact inference of these models reveals the empty string is often the global optimum. Prior works have speculated this phenomenon is a result of the inadequacy of neural models for language generation. However, in the case of morphological inflection, we find that the empty string is almost never the most probable solution under the model. Further, greedy search often finds the global optimum. These observations suggest that the poor calibration of many neural models may stem from characteristics of a specific subset of tasks rather than general ill-suitedness of such models for language generation.
Differentiable Generative Phonology
Feb 12, 2021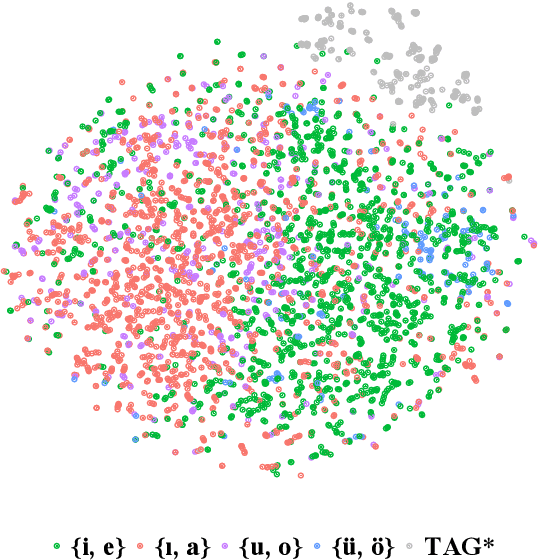
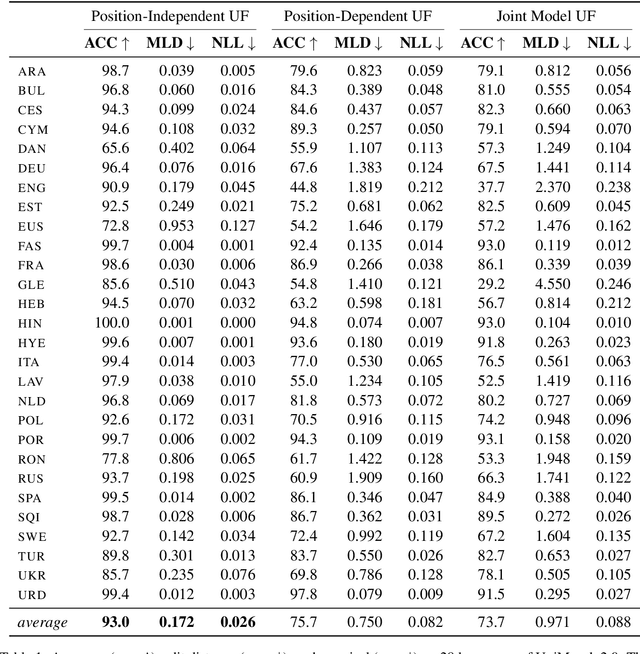
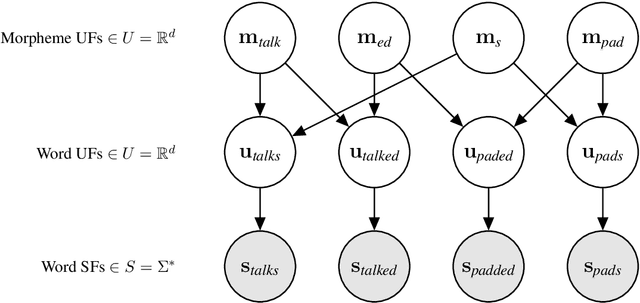
The goal of generative phonology, as formulated by Chomsky and Halle (1968), is to specify a formal system that explains the set of attested phonological strings in a language. Traditionally, a collection of rules (or constraints, in the case of optimality theory) and underlying forms (UF) are posited to work in tandem to generate phonological strings. However, the degree of abstraction of UFs with respect to their concrete realizations is contentious. As the main contribution of our work, we implement the phonological generative system as a neural model differentiable end-to-end, rather than as a set of rules or constraints. Contrary to traditional phonology, in our model, UFs are continuous vectors in $\mathbb{R}^d$, rather than discrete strings. As a consequence, UFs are discovered automatically rather than posited by linguists, and the model can scale to the size of a realistic vocabulary. Moreover, we compare several modes of the generative process, contemplating: i) the presence or absence of an underlying representation in between morphemes and surface forms (SFs); and ii) the conditional dependence or independence of UFs with respect to SFs. We evaluate the ability of each mode to predict attested phonological strings on 2 datasets covering 5 and 28 languages, respectively. The results corroborate two tenets of generative phonology, viz. the necessity for UFs and their independence from SFs. In general, our neural model of generative phonology learns both UFs and SFs automatically and on a large-scale.