 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models
Apr 22, 2025



We introduce PHYBench, a novel, high-quality benchmark designed for evaluating reasoning capabilities of large language models (LLMs) in physical contexts. PHYBench consists of 500 meticulously curated physics problems based on real-world physical scenarios, designed to assess the ability of models to understand and reason about realistic physical processes. Covering mechanics, electromagnetism, thermodynamics, optics, modern physics, and advanced physics, the benchmark spans difficulty levels from high school exercises to undergraduate problems and Physics Olympiad challenges. Additionally, we propose the Expression Edit Distance (EED) Score, a novel evaluation metric based on the edit distance between mathematical expressions, which effectively captures differences in model reasoning processes and results beyond traditional binary scoring methods. We evaluate various LLMs on PHYBench and compare their performance with human experts. Our results reveal that even state-of-the-art reasoning models significantly lag behind human experts, highlighting their limitations and the need for improvement in complex physical reasoning scenarios. Our benchmark results and dataset are publicly available at https://phybench-official.github.io/phybench-demo/.
Exposing Query Identification for Search Transparency
Oct 14, 2021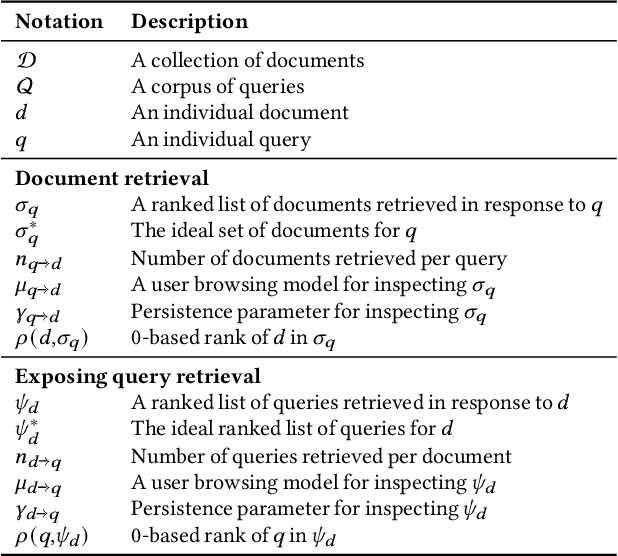

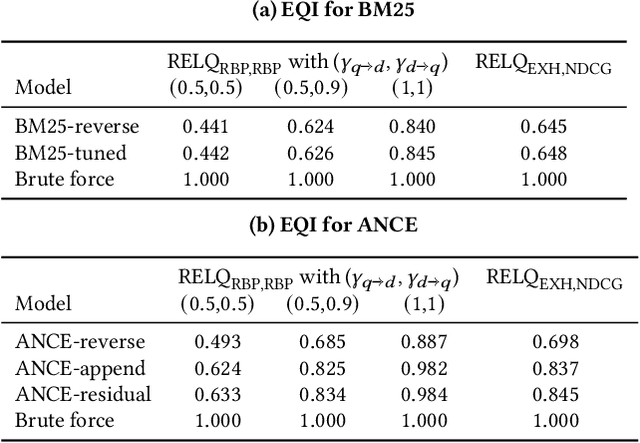
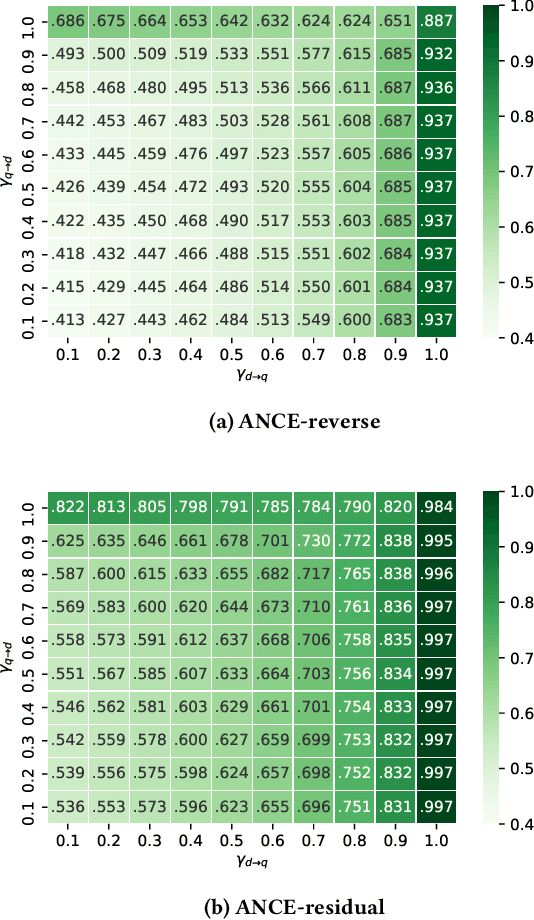
Search systems control the exposure of ranked content to searchers. In many cases, creators value not only the exposure of their content but, moreover, an understanding of the specific searches where the content is surfaced. The problem of identifying which queries expose a given piece of content in the ranking results is an important and relatively under-explored search transparency challenge. Exposing queries are useful for quantifying various issues of search bias, privacy, data protection, security, and search engine optimization. Exact identification of exposing queries in a given system is computationally expensive, especially in dynamic contexts such as web search. In quest of a more lightweight solution, we explore the feasibility of approximate exposing query identification (EQI) as a retrieval task by reversing the role of queries and documents in two classes of search systems: dense dual-encoder models and traditional BM25 models. We then propose how this approach can be improved through metric learning over the retrieval embedding space. We further derive an evaluation metric to measure the quality of a ranking of exposing queries, as well as conducting an empirical analysis focusing on various practical aspects of approximate EQI.