 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming the "Impracticality" of RAG: Proposing a Real-World Benchmark and Multi-Dimensional Diagnostic Framework
Apr 03, 2026Performance evaluation of Retrieval-Augmented Generation (RAG) systems within enterprise environments is governed by multi-dimensional and composite factors extending far beyond simple final accuracy checks. These factors include reasoning complexity, retrieval difficulty, the diverse structure of documents, and stringent requirements for operational explainability. Existing academic benchmarks fail to systematically diagnose these interlocking challenges, resulting in a critical gap where models achieving high performance scores fail to meet the expected reliability in practical deployment. To bridge this discrepancy, this research proposes a multi-dimensional diagnostic framework by defining a four-axis difficulty taxonomy and integrating it into an enterprise RAG benchmark to diagnose potential system weaknesses.
Scalpel: Fine-Grained Alignment of Attention Activation Manifolds via Mixture Gaussian Bridges to Mitigate Multimodal Hallucination
Feb 10, 2026Rapid progress in large vision-language models (LVLMs) has achieved unprecedented performance in vision-language tasks. However, due to the strong prior of large language models (LLMs) and misaligned attention across modalities, LVLMs often generate outputs inconsistent with visual content - termed hallucination. To address this, we propose \textbf{Scalpel}, a method that reduces hallucination by refining attention activation distributions toward more credible regions. Scalpel predicts trusted attention directions for each head in Transformer layers during inference and adjusts activations accordingly. It employs a Gaussian mixture model to capture multi-peak distributions of attention in trust and hallucination manifolds, and uses entropic optimal transport (equivalent to Schrödinger bridge problem) to map Gaussian components precisely. During mitigation, Scalpel dynamically adjusts intervention strength and direction based on component membership and mapping relationships between hallucination and trust activations. Extensive experiments across multiple datasets and benchmarks demonstrate that Scalpel effectively mitigates hallucinations, outperforming previous methods and achieving state-of-the-art performance. Moreover, Scalpel is model- and data-agnostic, requiring no additional computation, only a single decoding step.
SchröMind: Mitigating Hallucinations in Multimodal Large Language Models via Solving the Schrödinger Bridge Problem
Feb 10, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have achieved significant success across various domains. However, their use in high-stakes fields like healthcare remains limited due to persistent hallucinations, where generated text contradicts or ignores visual input. We contend that MLLMs can comprehend images but struggle to produce accurate token sequences. Minor perturbations can shift attention from truthful to untruthful states, and the autoregressive nature of text generation often prevents error correction. To address this, we propose SchröMind-a novel framework reducing hallucinations via solving the Schrödinger bridge problem. It establishes a token-level mapping between hallucinatory and truthful activations with minimal transport cost through lightweight training, while preserving the model's original capabilities. Extensive experiments on the POPE and MME benchmarks demonstrate the superiority of Schrödinger, which achieves state-of-the-art performance while introducing only minimal computational overhead.
Verifying Attention Robustness of Deep Neural Networks against Semantic Perturbations
Jul 13, 2022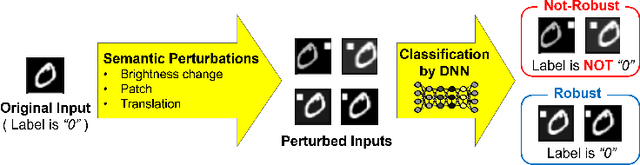
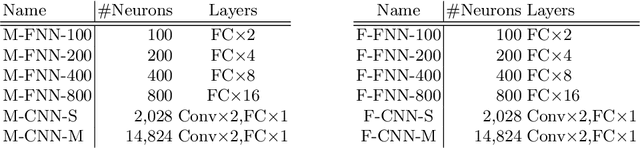
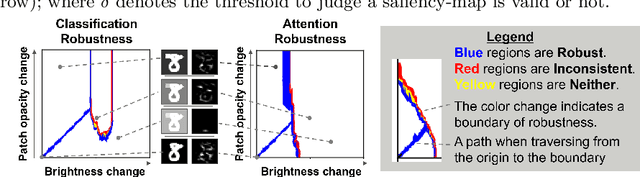

It is known that deep neural networks (DNNs) classify an input image by paying particular attention to certain specific pixels; a graphical representation of the magnitude of attention to each pixel is called a saliency-map. Saliency-maps are used to check the validity of the classification decision basis, e.g., it is not a valid basis for classification if a DNN pays more attention to the background rather than the subject of an image. Semantic perturbations can significantly change the saliency-map. In this work, we propose the first verification method for attention robustness, i.e., the local robustness of the changes in the saliency-map against combinations of semantic perturbations. Specifically, our method determines the range of the perturbation parameters (e.g., the brightness change) that maintains the difference between the actual saliency-map change and the expected saliency-map change below a given threshold value. Our method is based on activation region traversals, focusing on the outermost robust boundary for scalability on larger DNNs. Experimental results demonstrate that our method can show the extent to which DNNs can classify with the same basis regardless of semantic perturbations and report on performance and performance factors of activation region traversals.