 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Graph Embedding with Adversarial Training Methods
Jan 04, 2019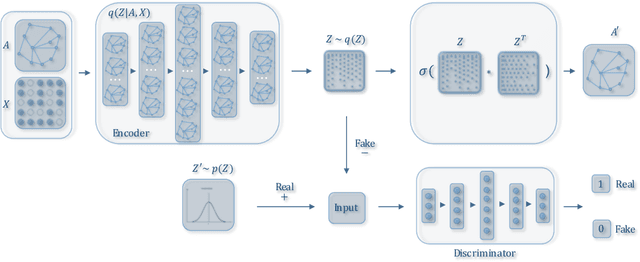
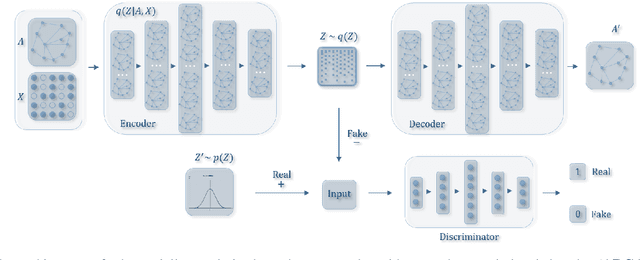
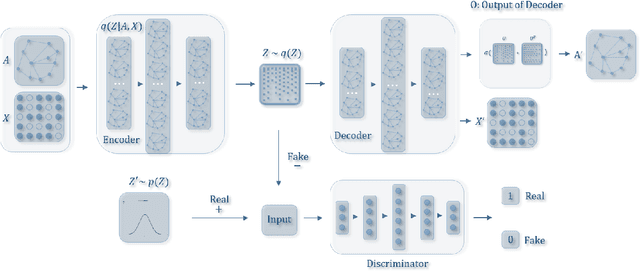
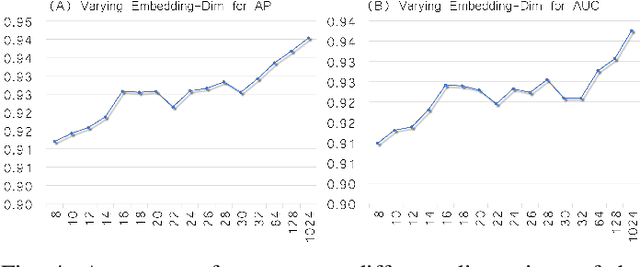
Graph embedding aims to transfer a graph into vectors to facilitate subsequent graph analytics tasks like link prediction and graph clustering. Most approaches on graph embedding focus on preserving the graph structure or minimizing the reconstruction errors for graph data. They have mostly overlooked the embedding distribution of the latent codes, which unfortunately may lead to inferior representation in many cases. In this paper, we present a novel adversarially regularized framework for graph embedding. By employing the graph convolutional network as an encoder, our framework embeds the topological information and node content into a vector representation, from which a graph decoder is further built to reconstruct the input graph. The adversarial training principle is applied to enforce our latent codes to match a prior Gaussian or Uniform distribution. Based on this framework, we derive two variants of adversarial models, the adversarially regularized graph autoencoder (ARGA) and its variational version, adversarially regularized variational graph autoencoder (ARVGA), to learn the graph embedding effectively. We also exploit other potential variations of ARGA and ARVGA to get a deeper understanding on our designs. Experimental results compared among twelve algorithms for link prediction and twenty algorithms for graph clustering validate our solutions.
Privacy-preserving Stochastic Gradual Learning
Sep 30, 2018
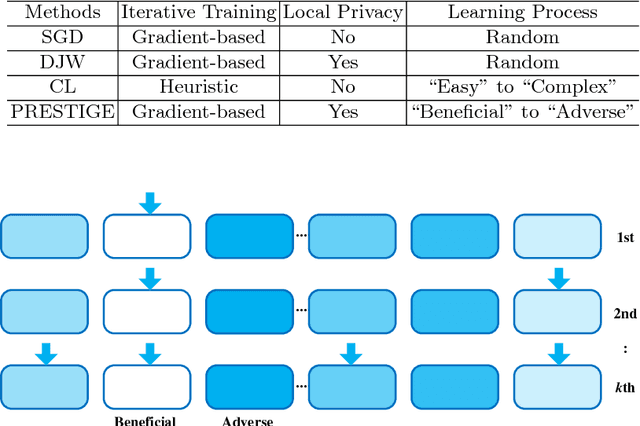
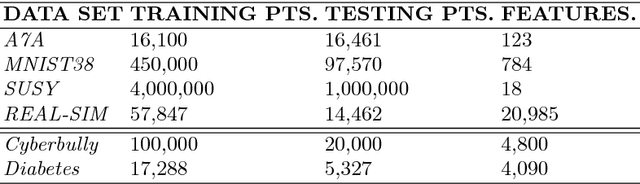
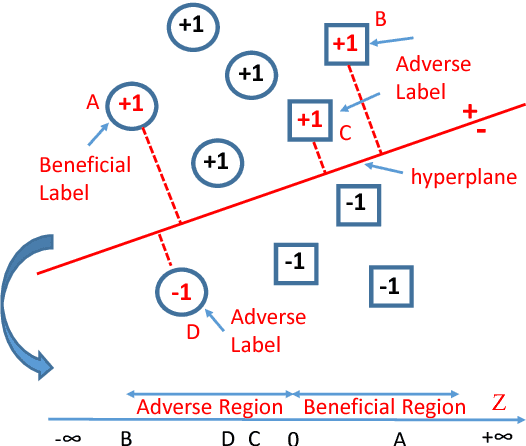
It is challenging for stochastic optimizations to handle large-scale sensitive data safely. Recently, Duchi et al. proposed private sampling strategy to solve privacy leakage in stochastic optimizations. However, this strategy leads to robustness degeneration, since this strategy is equal to the noise injection on each gradient, which adversely affects updates of the primal variable. To address this challenge, we introduce a robust stochastic optimization under the framework of local privacy, which is called Privacy-pREserving StochasTIc Gradual lEarning (PRESTIGE). PRESTIGE bridges private updates of the primal variable (by private sampling) with the gradual curriculum learning (CL). Specifically, the noise injection leads to the issue of label noise, but the robust learning process of CL can combat with label noise. Thus, PRESTIGE yields "private but robust" updates of the primal variable on the private curriculum, namely an reordered label sequence provided by CL. In theory, we reveal the convergence rate and maximum complexity of PRESTIGE. Empirical results on six datasets show that, PRESTIGE achieves a good tradeoff between privacy preservation and robustness over baselines.