 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models for Time Series Applications: A Survey
May 01, 2023
Diffusion models, a family of generative models based on deep learning, have become increasingly prominent in cutting-edge machine learning research. With a distinguished performance in generating samples that resemble the observed data, diffusion models are widely used in image, video, and text synthesis nowadays. In recent years, the concept of diffusion has been extended to time series applications, and many powerful models have been developed. Considering the deficiency of a methodical summary and discourse on these models, we provide this survey as an elementary resource for new researchers in this area and also an inspiration to motivate future research. For better understanding, we include an introduction about the basics of diffusion models. Except for this, we primarily focus on diffusion-based methods for time series forecasting, imputation, and generation, and present them respectively in three individual sections. We also compare different methods for the same application and highlight their connections if applicable. Lastly, we conclude the common limitation of diffusion-based methods and highlight potential future research directions.
DSRRTracker: Dynamic Search Region Refinement for Attention-based Siamese Multi-Object Tracking
Mar 21, 2022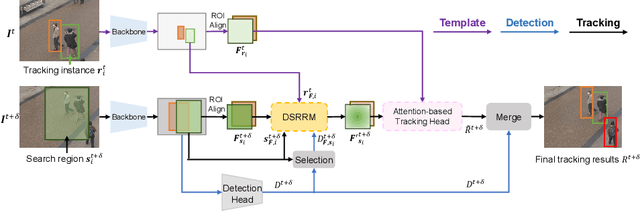
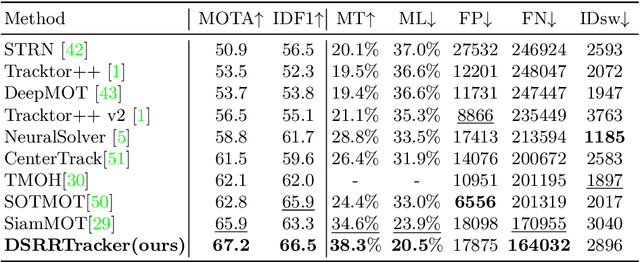
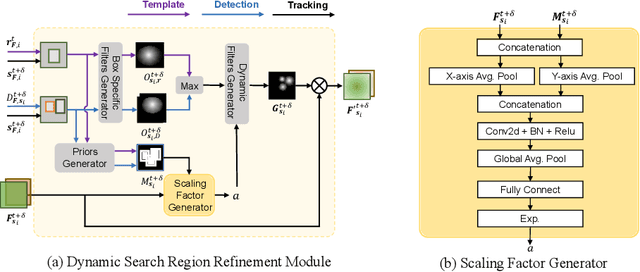
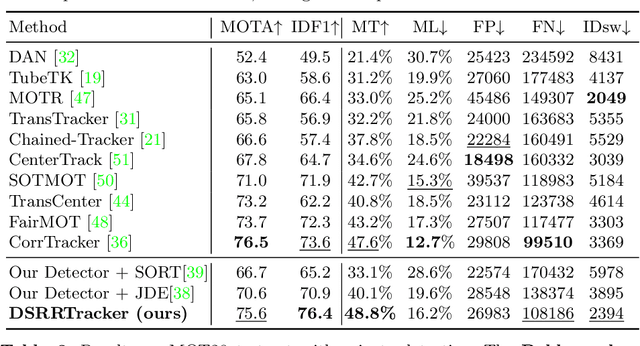
Many multi-object tracking (MOT) methods follow the framework of "tracking by detection", which associates the target objects-of-interest based on the detection results. However, due to the separate models for detection and association, the tracking results are not optimal.Moreover, the speed is limited by some cumbersome association methods to achieve high tracking performance. In this work, we propose an end-to-end MOT method, with a Gaussian filter-inspired dynamic search region refinement module to dynamically filter and refine the search region by considering both the template information from the past frames and the detection results from the current frame with little computational burden, and a lightweight attention-based tracking head to achieve the effective fine-grained instance association. Extensive experiments and ablation study on MOT17 and MOT20 datasets demonstrate that our method can achieve the state-of-the-art performance with reasonable speed.
MM-FSOD: Meta and metric integrated few-shot object detection
Dec 30, 2020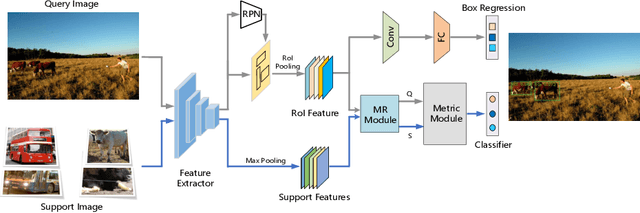

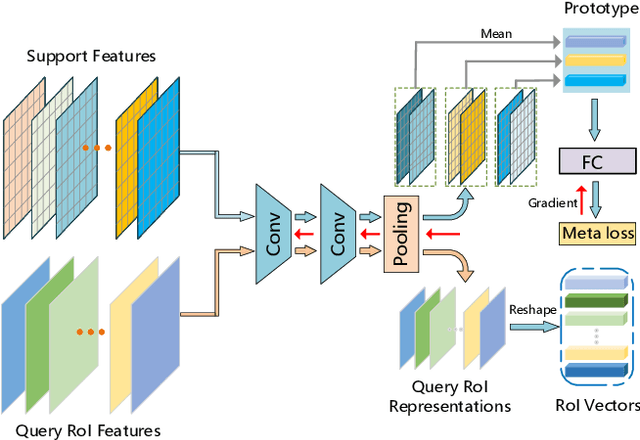
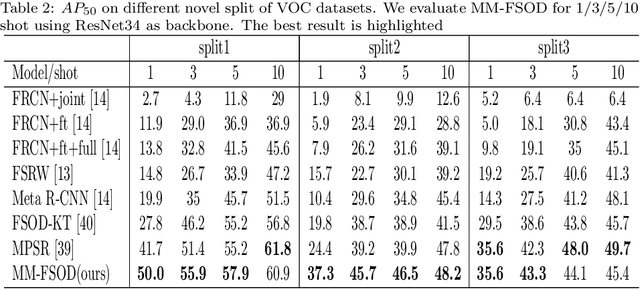
In the object detection task, CNN (Convolutional neural networks) models always need a large amount of annotated examples in the training process. To reduce the dependency of expensive annotations, few-shot object detection has become an increasing research focus. In this paper, we present an effective object detection framework (MM-FSOD) that integrates metric learning and meta-learning to tackle the few-shot object detection task. Our model is a class-agnostic detection model that can accurately recognize new categories, which are not appearing in training samples. Specifically, to fast learn the features of new categories without a fine-tuning process, we propose a meta-representation module (MR module) to learn intra-class mean prototypes. MR module is trained with a meta-learning method to obtain the ability to reconstruct high-level features. To further conduct similarity of features between support prototype with query RoIs features, we propose a Pearson metric module (PR module) which serves as a classifier. Compared to the previous commonly used metric method, cosine distance metric. PR module enables the model to align features into discriminative embedding space. We conduct extensive experiments on benchmark datasets FSOD, MS COCO, and PASCAL VOC to demonstrate the feasibility and efficiency of our model. Comparing with the previous method, MM-FSOD achieves state-of-the-art (SOTA) results.