 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Graph Neural Networks for Keyphrase Generation
Sep 10, 2021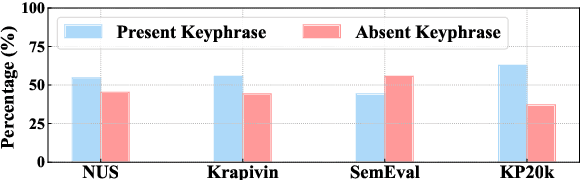

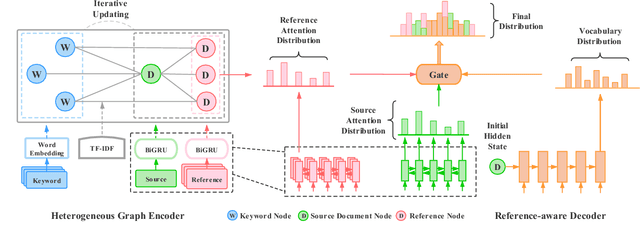

The encoder-decoder framework achieves state-of-the-art results in keyphrase generation (KG) tasks by predicting both present keyphrases that appear in the source document and absent keyphrases that do not. However, relying solely on the source document can result in generating uncontrollable and inaccurate absent keyphrases. To address these problems, we propose a novel graph-based method that can capture explicit knowledge from related references. Our model first retrieves some document-keyphrases pairs similar to the source document from a pre-defined index as references. Then a heterogeneous graph is constructed to capture relationships of different granularities between the source document and its references. To guide the decoding process, a hierarchical attention and copy mechanism is introduced, which directly copies appropriate words from both the source document and its references based on their relevance and significance. The experimental results on multiple KG benchmarks show that the proposed model achieves significant improvements against other baseline models, especially with regard to the absent keyphrase prediction.
TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing
Apr 06, 2021



Various robustness evaluation methodologies from different perspectives have been proposed for different natural language processing (NLP) tasks. These methods have often focused on either universal or task-specific generalization capabilities. In this work, we propose a multilingual robustness evaluation platform for NLP tasks (TextFlint) that incorporates universal text transformation, task-specific transformation, adversarial attack, subpopulation, and their combinations to provide comprehensive robustness analysis. TextFlint enables practitioners to automatically evaluate their models from all aspects or to customize their evaluations as desired with just a few lines of code. To guarantee user acceptability, all the text transformations are linguistically based, and we provide a human evaluation for each one. TextFlint generates complete analytical reports as well as targeted augmented data to address the shortcomings of the model's robustness. To validate TextFlint's utility, we performed large-scale empirical evaluations (over 67,000 evaluations) on state-of-the-art deep learning models, classic supervised methods, and real-world systems. Almost all models showed significant performance degradation, including a decline of more than 50% of BERT's prediction accuracy on tasks such as aspect-level sentiment classification, named entity recognition, and natural language inference. Therefore, we call for the robustness to be included in the model evaluation, so as to promote the healthy development of NLP technology.