 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetry Teleportation for Accelerated Optimization
May 21, 2022
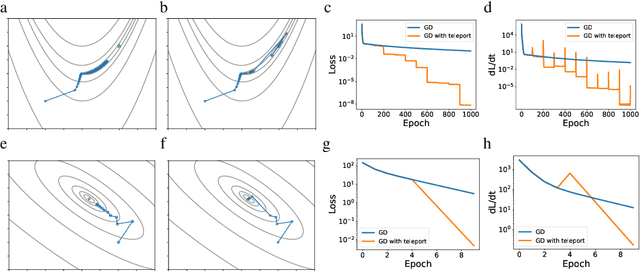
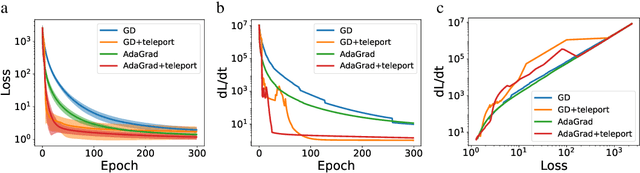
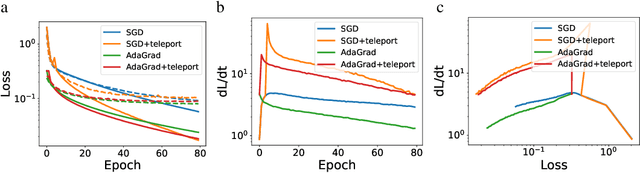
Existing gradient-based optimization methods update the parameters locally, in a direction that minimizes the loss function. We study a different approach, symmetry teleportation, that allows the parameters to travel a large distance on the loss level set, in order to improve the convergence speed in subsequent steps. Teleportation exploits parameter space symmetries of the optimization problem and transforms parameters while keeping the loss invariant. We derive the loss-invariant group actions for test functions and multi-layer neural networks, and prove a necessary condition of when teleportation improves convergence rate. We also show that our algorithm is closely related to second order methods. Experimentally, we show that teleportation improves the convergence speed of gradient descent and AdaGrad for several optimization problems including test functions, multi-layer regressions, and MNIST classification.
Probabilistic Symmetry for Improved Trajectory Forecasting
May 04, 2022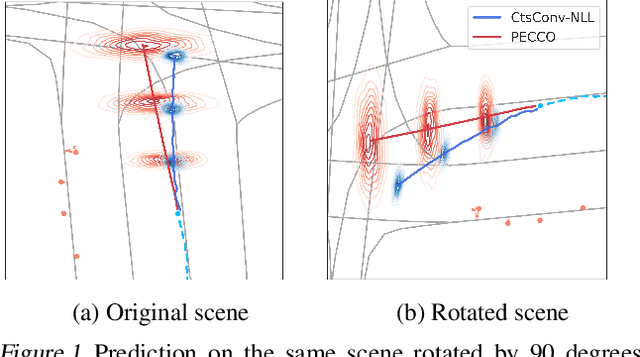
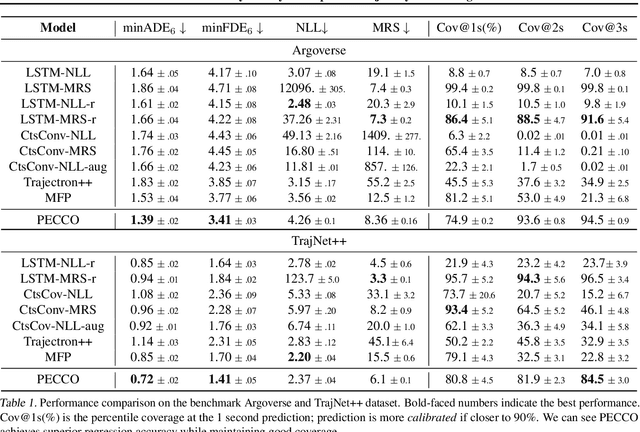
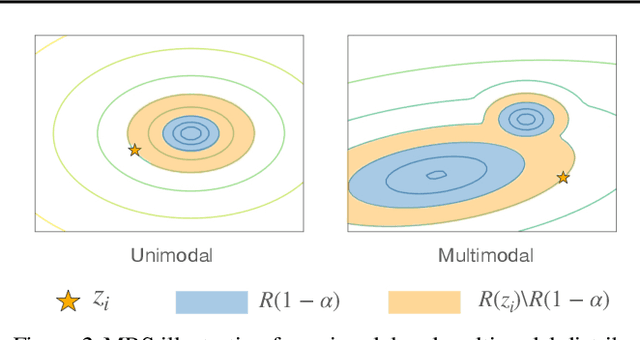

Trajectory prediction is a core AI problem with broad applications in robotics and autonomous driving. While most existing works focus on deterministic prediction, producing probabilistic forecasts to quantify prediction uncertainty is critical for downstream decision-making tasks such as risk assessment, motion planning, and safety guarantees. We introduce a new metric, mean regional score (MRS), to evaluate the quality of probabilistic trajectory forecasts. We propose a novel probabilistic trajectory prediction model, Probabilistic Equivariant Continuous COnvolution (PECCO) and show that leveraging symmetry, specifically rotation equivariance, can improve the predictions' accuracy as well as coverage. On both vehicle and pedestrian datasets, PECCO shows state-of-the-art prediction performance and improved calibration compared to baselines.
SELFIES and the future of molecular string representations
Mar 31, 2022
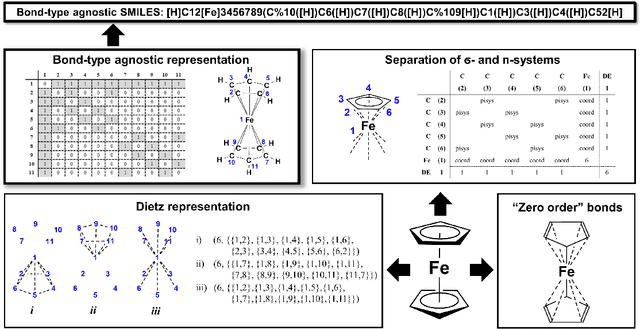

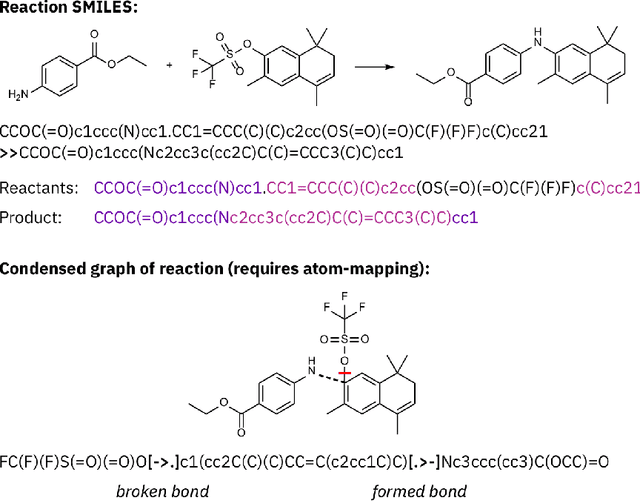
Artificial intelligence (AI) and machine learning (ML) are expanding in popularity for broad applications to challenging tasks in chemistry and materials science. Examples include the prediction of properties, the discovery of new reaction pathways, or the design of new molecules. The machine needs to read and write fluently in a chemical language for each of these tasks. Strings are a common tool to represent molecular graphs, and the most popular molecular string representation, SMILES, has powered cheminformatics since the late 1980s. However, in the context of AI and ML in chemistry, SMILES has several shortcomings -- most pertinently, most combinations of symbols lead to invalid results with no valid chemical interpretation. To overcome this issue, a new language for molecules was introduced in 2020 that guarantees 100\% robustness: SELFIES (SELF-referencIng Embedded Strings). SELFIES has since simplified and enabled numerous new applications in chemistry. In this manuscript, we look to the future and discuss molecular string representations, along with their respective opportunities and challenges. We propose 16 concrete Future Projects for robust molecular representations. These involve the extension toward new chemical domains, exciting questions at the interface of AI and robust languages and interpretability for both humans and machines. We hope that these proposals will inspire several follow-up works exploiting the full potential of molecular string representations for the future of AI in chemistry and materials science.
Taming the Long Tail of Deep Probabilistic Forecasting
Mar 02, 2022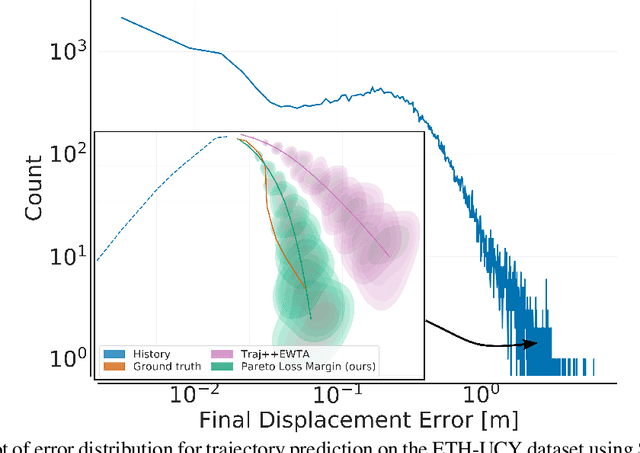
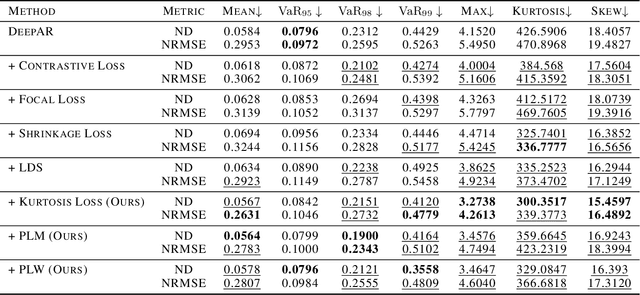
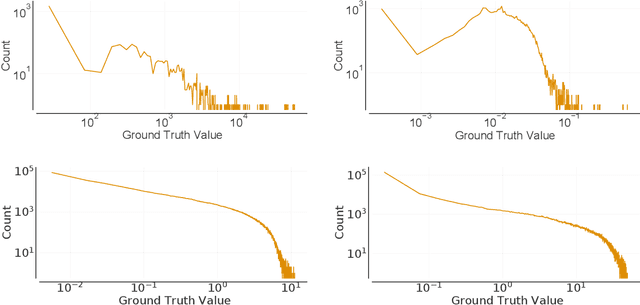
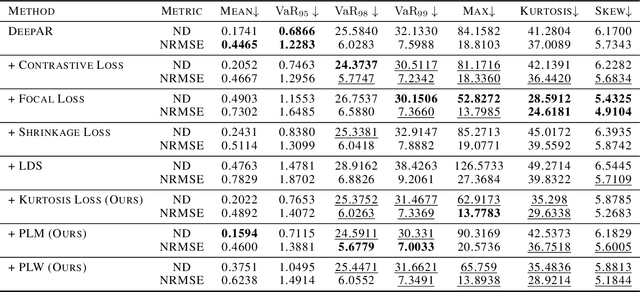
Deep probabilistic forecasting is gaining attention in numerous applications ranging from weather prognosis, through electricity consumption estimation, to autonomous vehicle trajectory prediction. However, existing approaches focus on improvements on the most common scenarios without addressing the performance on rare and difficult cases. In this work, we identify a long tail behavior in the performance of state-of-the-art deep learning methods on probabilistic forecasting. We present two moment-based tailedness measurement concepts to improve performance on the difficult tail examples: Pareto Loss and Kurtosis Loss. Kurtosis loss is a symmetric measurement as the fourth moment about the mean of the loss distribution. Pareto loss is asymmetric measuring right tailedness, modeling the loss using a generalized Pareto distribution (GPD). We demonstrate the performance of our approach on several real-world datasets including time series and spatiotemporal trajectories, achieving significant improvements on the tail examples.
Approximately Equivariant Networks for Imperfectly Symmetric Dynamics
Feb 16, 2022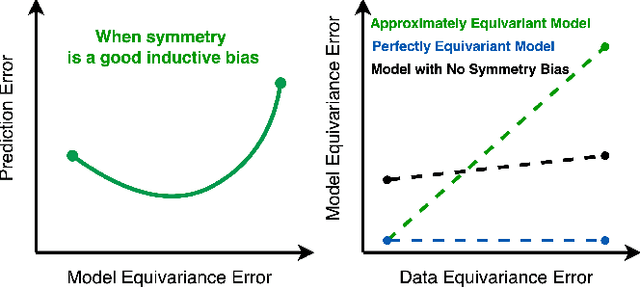

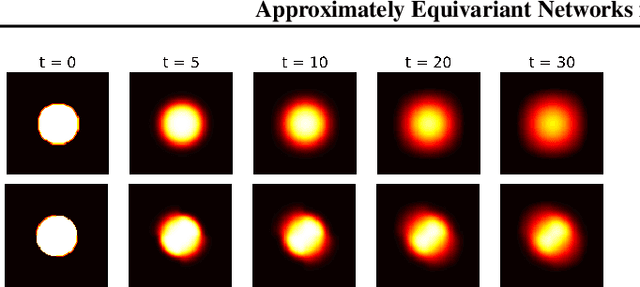

Incorporating symmetry as an inductive bias into neural network architecture has led to improvements in generalization, data efficiency, and physical consistency in dynamics modeling. Methods such as CNN or equivariant neural networks use weight tying to enforce symmetries such as shift invariance or rotational equivariance. However, despite the fact that physical laws obey many symmetries, real-world dynamical data rarely conforms to strict mathematical symmetry either due to noisy or incomplete data or to symmetry breaking features in the underlying dynamical system. We explore approximately equivariant networks which are biased towards preserving symmetry but are not strictly constrained to do so. By relaxing equivariance constraints, we find that our models can outperform both baselines with no symmetry bias and baselines with overly strict symmetry in both simulated turbulence domains and real-world multi-stream jet flow.
AI-Bind: Improving Binding Predictions for Novel Protein Targets and Ligands
Dec 28, 2021
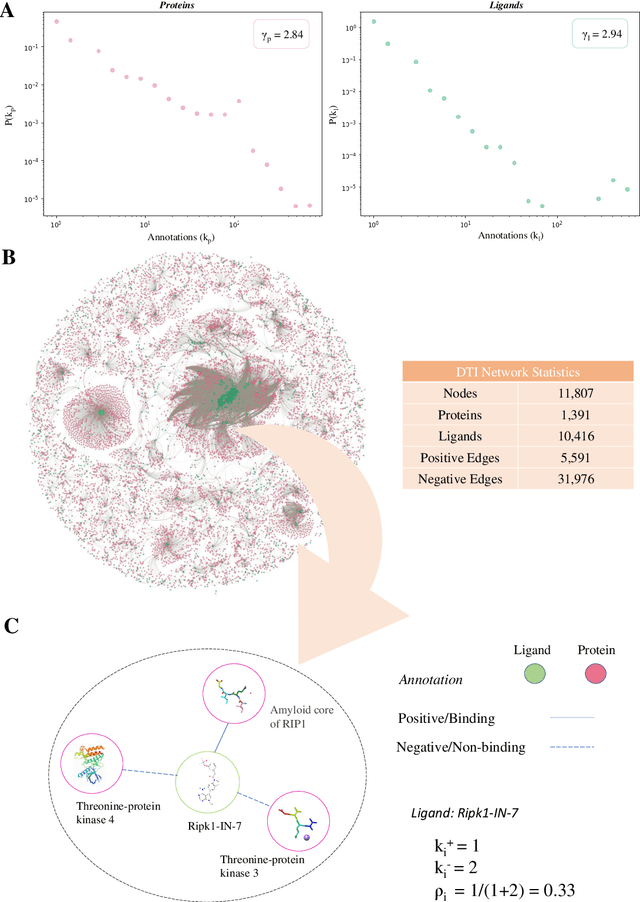

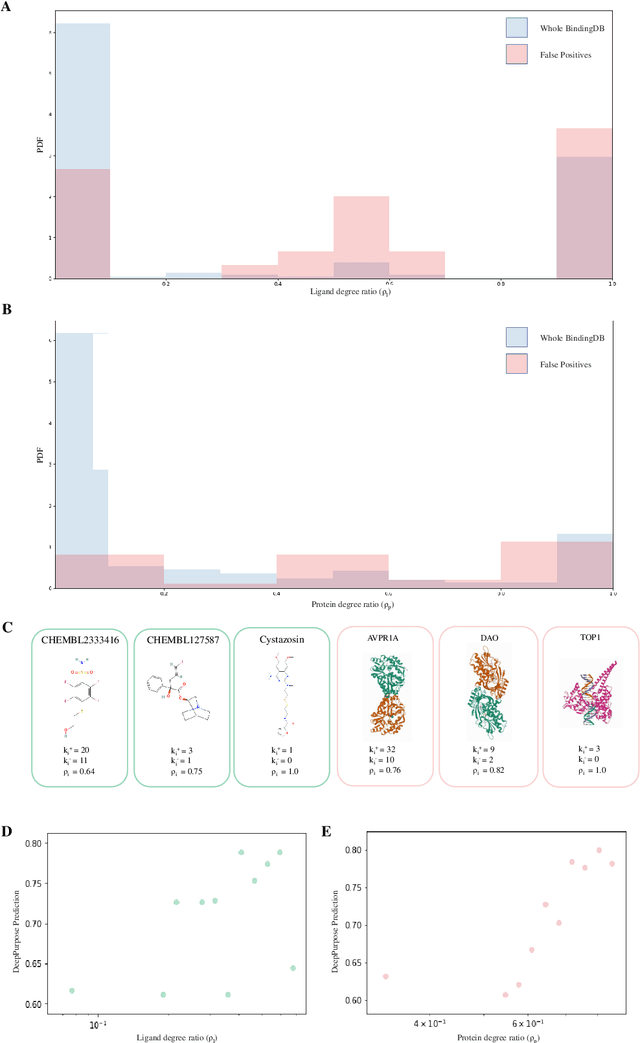
Identifying novel drug-target interactions (DTI) is a critical and rate limiting step in drug discovery. While deep learning models have been proposed to accelerate the identification process, we show that state-of-the-art models fail to generalize to novel (i.e., never-before-seen) structures. We first unveil the mechanisms responsible for this shortcoming, demonstrating how models rely on shortcuts that leverage the topology of the protein-ligand bipartite network, rather than learning the node features. Then, we introduce AI-Bind, a pipeline that combines network-based sampling strategies with unsupervised pre-training, allowing us to limit the annotation imbalance and improve binding predictions for novel proteins and ligands. We illustrate the value of AI-Bind by predicting drugs and natural compounds with binding affinity to SARS-CoV-2 viral proteins and the associated human proteins. We also validate these predictions via auto-docking simulations and comparison with recent experimental evidence. Overall, AI-Bind offers a powerful high-throughput approach to identify drug-target combinations, with the potential of becoming a powerful tool in drug discovery.
Neural Point Process for Learning Spatiotemporal Event Dynamics
Dec 12, 2021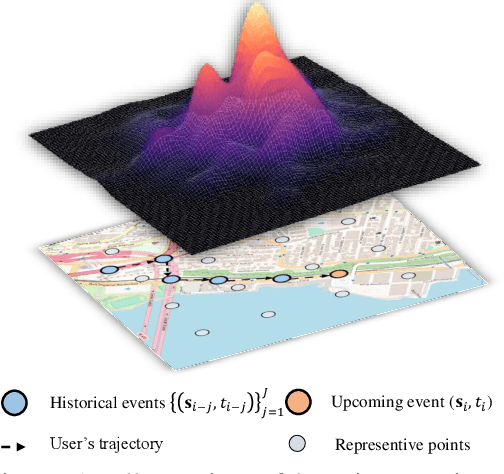

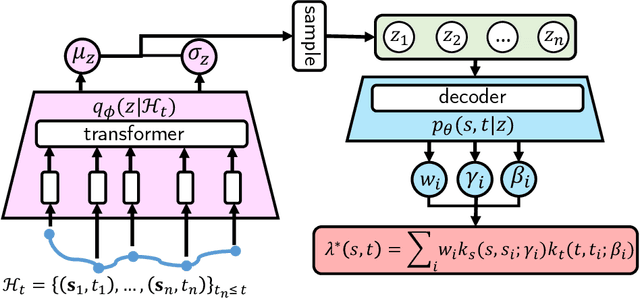
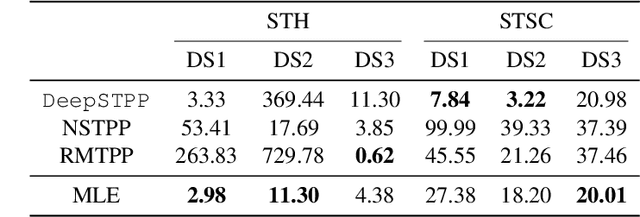
Learning the dynamics of spatiotemporal events is a fundamental problem. Neural point processes enhance the expressivity of point process models with deep neural networks. However, most existing methods only consider temporal dynamics without spatial modeling. We propose Deep Spatiotemporal Point Process (DeepSTPP), a deep dynamics model that integrates spatiotemporal point processes. Our method is flexible, efficient, and can accurately forecast irregularly sampled events over space and time. The key construction of our approach is the nonparametric space-time intensity function, governed by a latent process. The intensity function enjoys closed-form integration for the density. The latent process captures the uncertainty of the event sequence. We use amortized variational inference to infer the latent process with deep networks. Using synthetic datasets, we validate our model can accurately learn the true intensity function. On real-world benchmark datasets, our model demonstrates superior performance over state-of-the-art baselines.
Automatic Symmetry Discovery with Lie Algebra Convolutional Network
Sep 15, 2021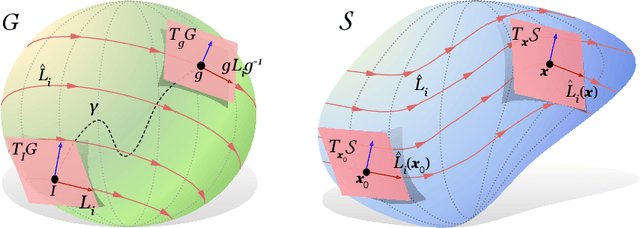
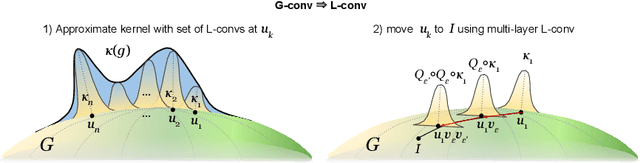
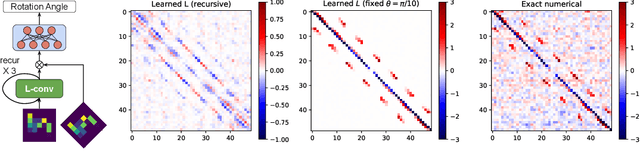
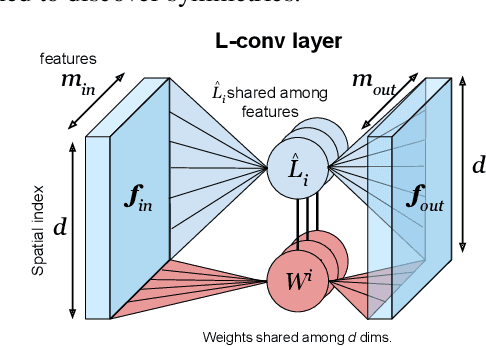
Existing equivariant neural networks for continuous groups require discretization or group representations. All these approaches require detailed knowledge of the group parametrization and cannot learn entirely new symmetries. We propose to work with the Lie algebra (infinitesimal generators) instead of the Lie group.Our model, the Lie algebra convolutional network (L-conv) can learn potential symmetries and does not require discretization of the group. We show that L-conv can serve as a building block to construct any group equivariant architecture. We discuss how CNNs and Graph Convolutional Networks are related to and can be expressed as L-conv with appropriate groups. We also derive the MSE loss for a single L-conv layer and find a deep relation with Lagrangians used in physics, with some of the physics aiding in defining generalization and symmetries in the loss landscape. Conversely, L-conv could be used to propose more general equivariant ans\"atze for scientific machine learning.
Accelerating Stochastic Simulation with Interactive Neural Processes
Jun 11, 2021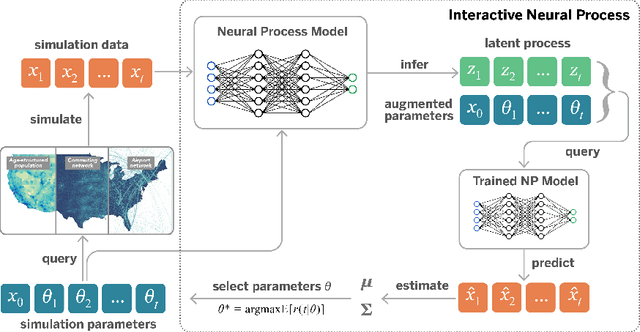

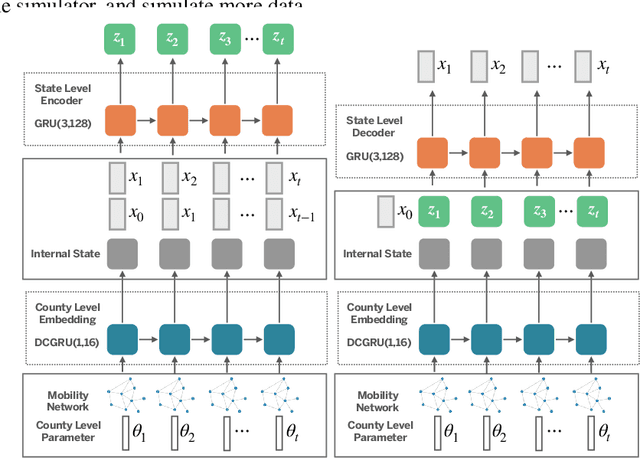
Stochastic simulations such as large-scale, spatiotemporal, age-structured epidemic models are computationally expensive at fine-grained resolution. We propose Interactive Neural Process (INP), an interactive framework to continuously learn a deep learning surrogate model and accelerate simulation. Our framework is based on the novel integration of Bayesian active learning, stochastic simulation and deep sequence modeling. In particular, we develop a novel spatiotemporal neural process model to mimic the underlying process dynamics. Our model automatically infers the latent process which describes the intrinsic uncertainty of the simulator. This also gives rise to a new acquisition function that can quantify the uncertainty of deep learning predictions. We design Bayesian active learning algorithms to iteratively query the simulator, gather more data, and continuously improve the model. We perform theoretical analysis and demonstrate that our approach reduces sample complexity compared with random sampling in high dimension. Empirically, we demonstrate our framework can faithfully imitate the behavior of a complex infectious disease simulator with a small number of examples, enabling rapid simulation and scenario exploration.
Quantifying Uncertainty in Deep Spatiotemporal Forecasting
May 25, 2021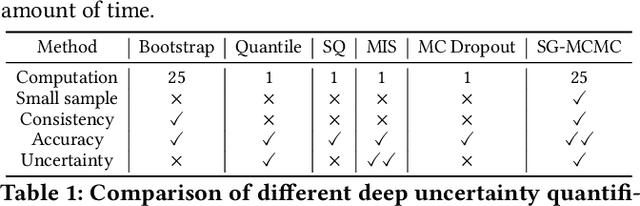
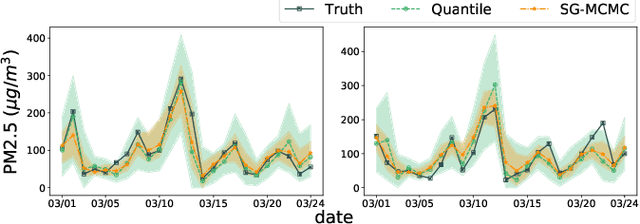
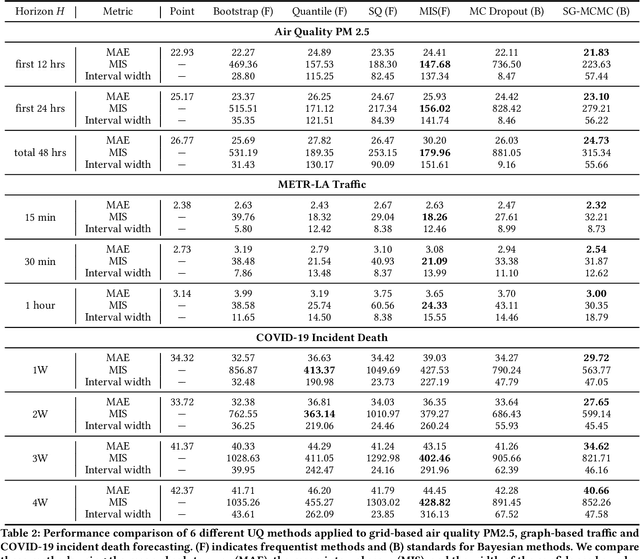
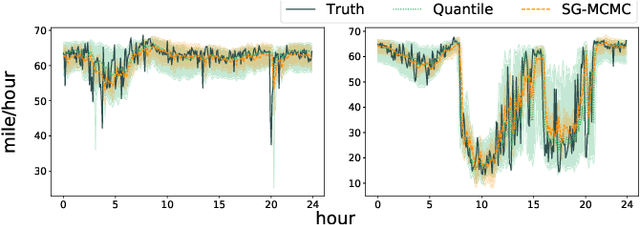
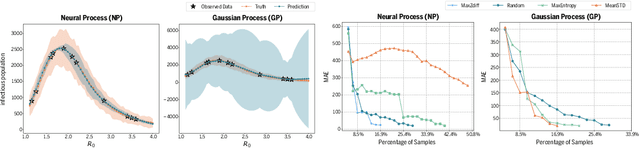
Deep learning is gaining increasing popularity for spatiotemporal forecasting. However, prior works have mostly focused on point estimates without quantifying the uncertainty of the predictions. In high stakes domains, being able to generate probabilistic forecasts with confidence intervals is critical to risk assessment and decision making. Hence, a systematic study of uncertainty quantification (UQ) methods for spatiotemporal forecasting is missing in the community. In this paper, we describe two types of spatiotemporal forecasting problems: regular grid-based and graph-based. Then we analyze UQ methods from both the Bayesian and the frequentist point of view, casting in a unified framework via statistical decision theory. Through extensive experiments on real-world road network traffic, epidemics, and air quality forecasting tasks, we reveal the statistical and computational trade-offs for different UQ methods: Bayesian methods are typically more robust in mean prediction, while confidence levels obtained from frequentist methods provide more extensive coverage over data variations. Computationally, quantile regression type methods are cheaper for a single confidence interval but require re-training for different intervals. Sampling based methods generate samples that can form multiple confidence intervals, albeit at a higher computational cost.