 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Optimal Early Stopping: Over-informative versus Under-informative Parametrization
Feb 23, 2022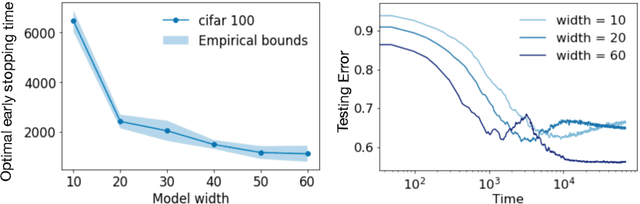
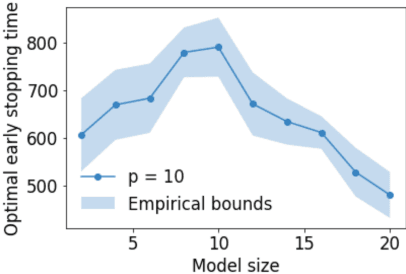
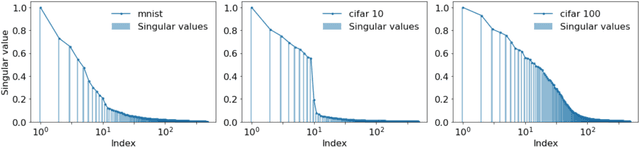
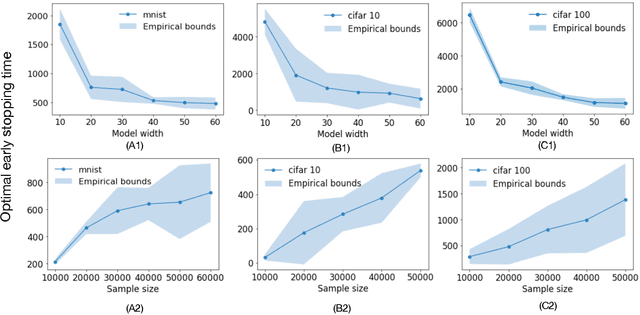
Early stopping is a simple and widely used method to prevent over-training neural networks. We develop theoretical results to reveal the relationship between the optimal early stopping time and model dimension as well as sample size of the dataset for certain linear models. Our results demonstrate two very different behaviors when the model dimension exceeds the number of features versus the opposite scenario. While most previous works on linear models focus on the latter setting, we observe that the dimension of the model often exceeds the number of features arising from data in common deep learning tasks and propose a model to study this setting. We demonstrate experimentally that our theoretical results on optimal early stopping time corresponds to the training process of deep neural networks.
Deformation Robust Roto-Scale-Translation Equivariant CNNs
Nov 22, 2021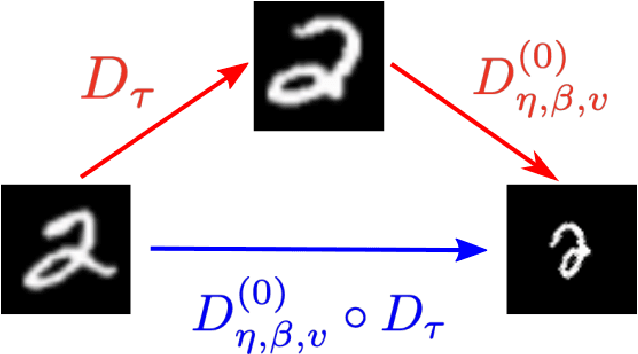
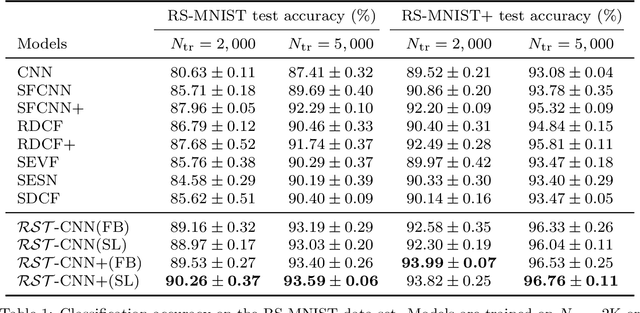
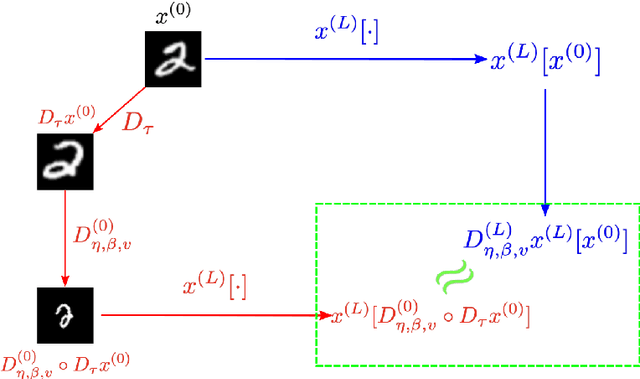

Incorporating group symmetry directly into the learning process has proved to be an effective guideline for model design. By producing features that are guaranteed to transform covariantly to the group actions on the inputs, group-equivariant convolutional neural networks (G-CNNs) achieve significantly improved generalization performance in learning tasks with intrinsic symmetry. General theory and practical implementation of G-CNNs have been studied for planar images under either rotation or scaling transformation, but only individually. We present, in this paper, a roto-scale-translation equivariant CNN (RST-CNN), that is guaranteed to achieve equivariance jointly over these three groups via coupled group convolutions. Moreover, as symmetry transformations in reality are rarely perfect and typically subject to input deformation, we provide a stability analysis of the equivariance of representation to input distortion, which motivates the truncated expansion of the convolutional filters under (pre-fixed) low-frequency spatial modes. The resulting model provably achieves deformation-robust RST equivariance, i.e., the RST symmetry is still "approximately" preserved when the transformation is "contaminated" by a nuisance data deformation, a property that is especially important for out-of-distribution generalization. Numerical experiments on MNIST, Fashion-MNIST, and STL-10 demonstrate that the proposed model yields remarkable gains over prior arts, especially in the small data regime where both rotation and scaling variations are present within the data.
Quantifying Uncertainty in Deep Spatiotemporal Forecasting
May 25, 2021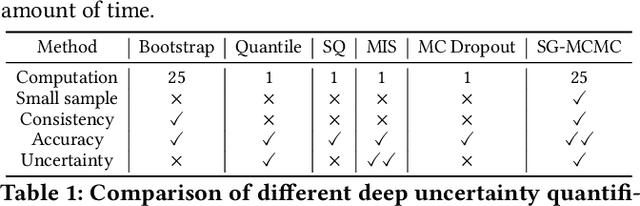
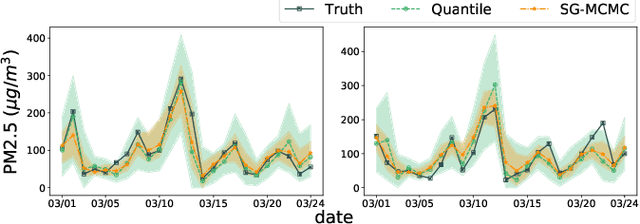
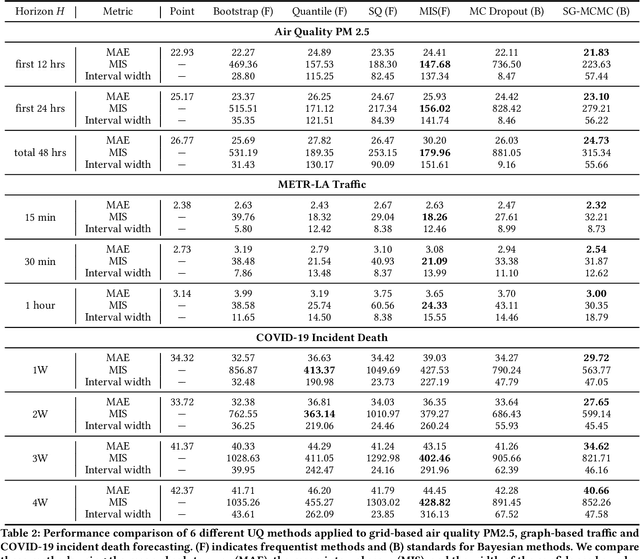
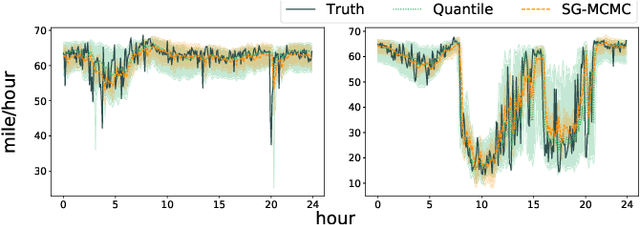
Deep learning is gaining increasing popularity for spatiotemporal forecasting. However, prior works have mostly focused on point estimates without quantifying the uncertainty of the predictions. In high stakes domains, being able to generate probabilistic forecasts with confidence intervals is critical to risk assessment and decision making. Hence, a systematic study of uncertainty quantification (UQ) methods for spatiotemporal forecasting is missing in the community. In this paper, we describe two types of spatiotemporal forecasting problems: regular grid-based and graph-based. Then we analyze UQ methods from both the Bayesian and the frequentist point of view, casting in a unified framework via statistical decision theory. Through extensive experiments on real-world road network traffic, epidemics, and air quality forecasting tasks, we reveal the statistical and computational trade-offs for different UQ methods: Bayesian methods are typically more robust in mean prediction, while confidence levels obtained from frequentist methods provide more extensive coverage over data variations. Computationally, quantile regression type methods are cheaper for a single confidence interval but require re-training for different intervals. Sampling based methods generate samples that can form multiple confidence intervals, albeit at a higher computational cost.
DeepGLEAM: a hybrid mechanistic and deep learning model for COVID-19 forecasting
Feb 15, 2021
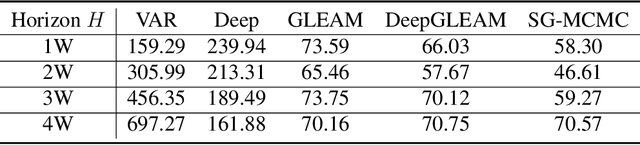
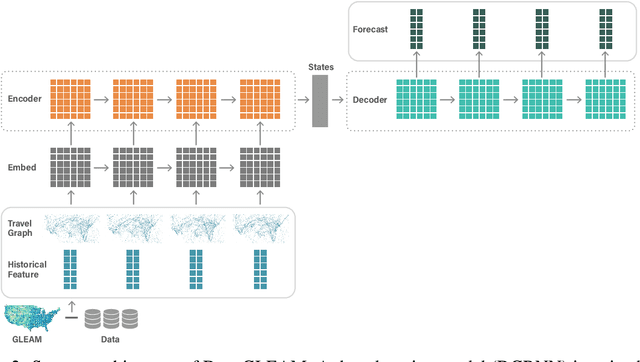

We introduce DeepGLEAM, a hybrid model for COVID-19 forecasting. DeepGLEAM combines a mechanistic stochastic simulation model GLEAM with deep learning. It uses deep learning to learn the correction terms from GLEAM, which leads to improved performance. We further integrate various uncertainty quantification methods to generate confidence intervals. We demonstrate DeepGLEAM on real-world COVID-19 mortality forecasting tasks.
Non-convex Learning via Replica Exchange Stochastic Gradient MCMC
Sep 10, 2020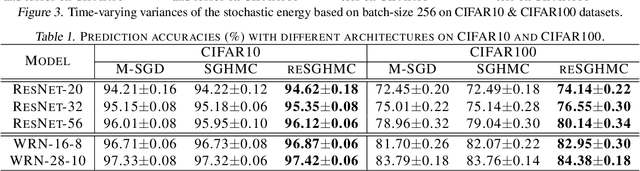
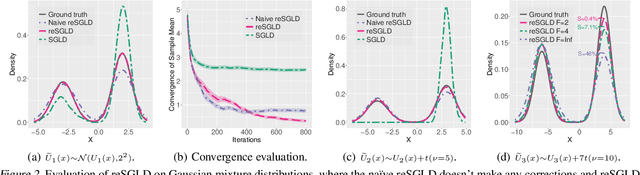
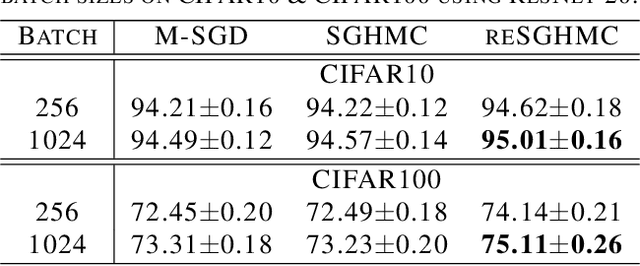
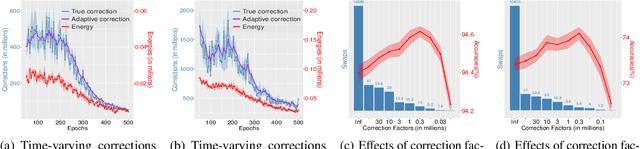
Replica exchange Monte Carlo (reMC), also known as parallel tempering, is an important technique for accelerating the convergence of the conventional Markov Chain Monte Carlo (MCMC) algorithms. However, such a method requires the evaluation of the energy function based on the full dataset and is not scalable to big data. The na\"ive implementation of reMC in mini-batch settings introduces large biases, which cannot be directly extended to the stochastic gradient MCMC (SGMCMC), the standard sampling method for simulating from deep neural networks (DNNs). In this paper, we propose an adaptive replica exchange SGMCMC (reSGMCMC) to automatically correct the bias and study the corresponding properties. The analysis implies an acceleration-accuracy trade-off in the numerical discretization of a Markov jump process in a stochastic environment. Empirically, we test the algorithm through extensive experiments on various setups and obtain the state-of-the-art results on CIFAR10, CIFAR100, and SVHN in both supervised learning and semi-supervised learning tasks.
RotEqNet: Rotation-Equivariant Network for Fluid Systems with Symmetric High-Order Tensors
Apr 28, 2020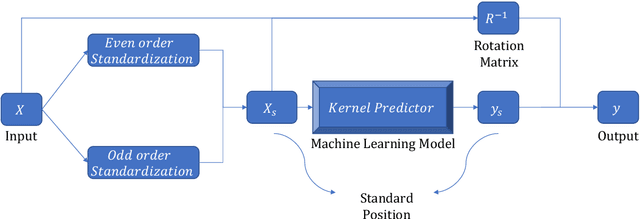

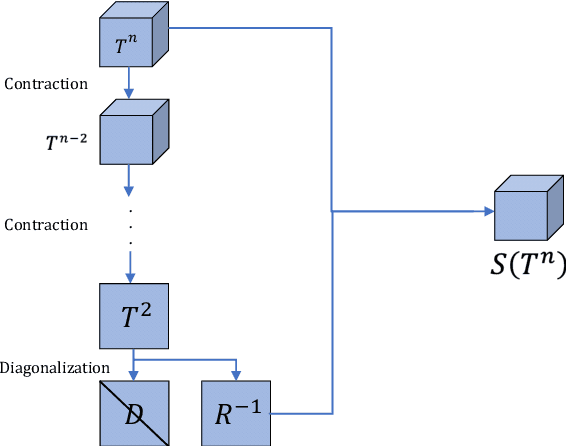

In the recent application of scientific modeling, machine learning models are largely applied to facilitate computational simulations of fluid systems. Rotation symmetry is a general property for most symmetric fluid systems. However, in general, current machine learning methods have no theoretical way to guarantee rotational symmetry. By observing an important property of contraction and rotation operation on high-order symmetric tensors, we prove that the rotation operation is preserved via tensor contraction. Based on this theoretical justification, in this paper, we introduce Rotation-Equivariant Network (RotEqNet) to guarantee the property of rotation-equivariance for high-order tensors in fluid systems. We implement RotEqNet and evaluate our claims through four case studies on various fluid systems. The property of error reduction and rotation-equivariance is verified in these case studies. Results from the comparative study show that our method outperforms conventional methods, which rely on data augmentation.
Learning with Collaborative Neural Network Group by Reflection
Jan 20, 2019For the present engineering of neural systems, the preparing of extensive scale learning undertakings generally not just requires a huge neural system with a mind boggling preparing process yet additionally troublesome discover a clarification for genuine applications. In this paper, we might want to present the Collaborative Neural Network Group (CNNG). CNNG is a progression of neural systems that work cooperatively to deal with various errands independently in a similar learning framework. It is advanced from a solitary neural system by reflection. Along these lines, in light of various circumstances removed by the calculation, the CNNG can perform diverse techniques when handling the information. The examples of chose methodology can be seen by human to make profound adapting more reasonable. In our execution, the CNNG is joined by a few moderately little neural systems. We give a progression of examinations to assess the execution of CNNG contrasted with other learning strategies. The CNNG is able to get a higher accuracy with a much lower training cost. We can reduce the error rate by 74.5% and reached the accuracy of 99.45% in MNIST with three feedforward networks (4 layers) in one training epoch.
Cortex Neural Network: learning with Neural Network groups
Apr 10, 2018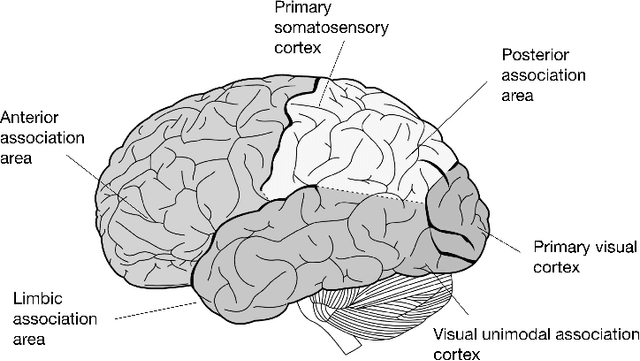
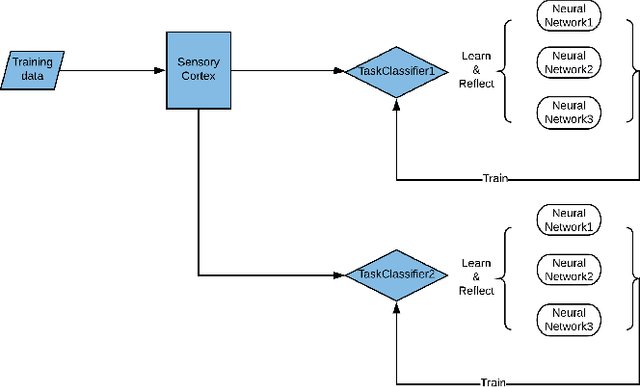
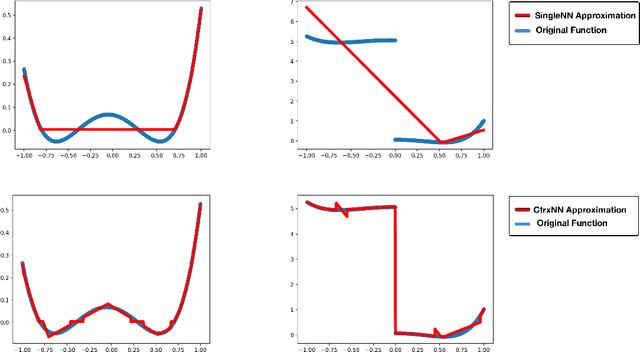
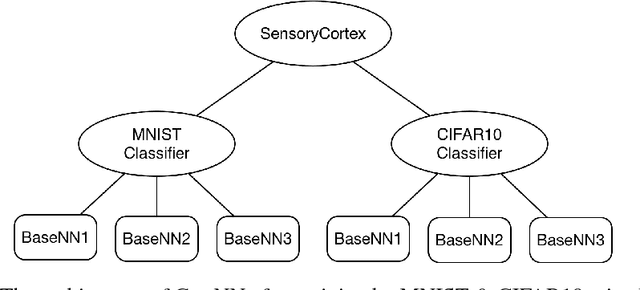
Neural Network has been successfully applied to many real-world problems, such as image recognition and machine translation. However, for the current architecture of neural networks, it is hard to perform complex cognitive tasks, for example, to process the image and audio inputs together. Cortex, as an important architecture in the brain, is important for animals to perform the complex cognitive task. We view the architecture of Cortex in the brain as a missing part in the design of the current artificial neural network. In this paper, we purpose Cortex Neural Network (CrtxNN). The Cortex Neural Network is an upper architecture of neural networks which motivated from cerebral cortex in the brain to handle different tasks in the same learning system. It is able to identify different tasks and solve them with different methods. In our implementation, the Cortex Neural Network is able to process different cognitive tasks and perform reflection to get a higher accuracy. We provide a series of experiments to examine the capability of the cortex architecture on traditional neural networks. Our experiments proved its ability on the Cortex Neural Network can reach accuracy by 98.32% on MNIST and 62% on CIFAR10 at the same time, which can promisingly reduce the loss by 40%.