 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Model Understanding with Path-Sufficient Explanations
Sep 13, 2021

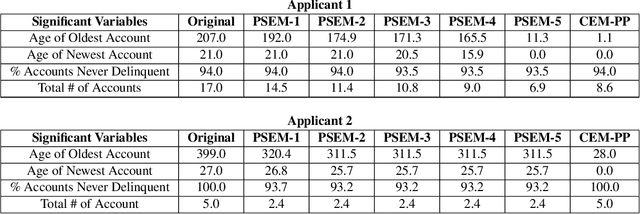

Feature based local attribution methods are amongst the most prevalent in explainable artificial intelligence (XAI) literature. Going beyond standard correlation, recently, methods have been proposed that highlight what should be minimally sufficient to justify the classification of an input (viz. pertinent positives). While minimal sufficiency is an attractive property, the resulting explanations are often too sparse for a human to understand and evaluate the local behavior of the model, thus making it difficult to judge its overall quality. To overcome these limitations, we propose a novel method called Path-Sufficient Explanations Method (PSEM) that outputs a sequence of sufficient explanations for a given input of strictly decreasing size (or value) -- from original input to a minimally sufficient explanation -- which can be thought to trace the local boundary of the model in a smooth manner, thus providing better intuition about the local model behavior for the specific input. We validate these claims, both qualitatively and quantitatively, with experiments that show the benefit of PSEM across all three modalities (image, tabular and text). A user study depicts the strength of the method in communicating the local behavior, where (many) users are able to correctly determine the prediction made by a model.
One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques
Sep 14, 2019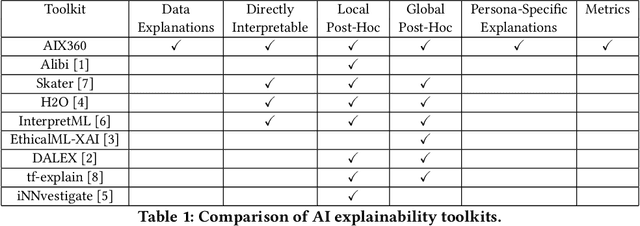
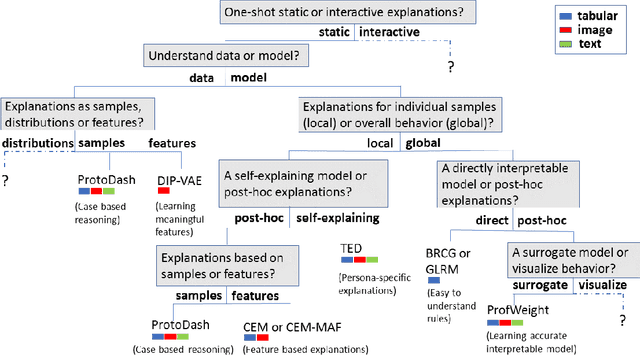
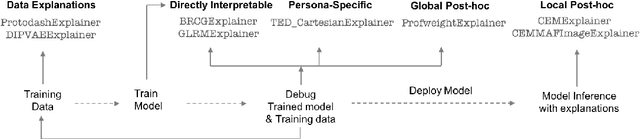
As artificial intelligence and machine learning algorithms make further inroads into society, calls are increasing from multiple stakeholders for these algorithms to explain their outputs. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, present different requirements for explanations. Toward addressing these needs, we introduce AI Explainability 360 (http://aix360.mybluemix.net/), an open-source software toolkit featuring eight diverse and state-of-the-art explainability methods and two evaluation metrics. Equally important, we provide a taxonomy to help entities requiring explanations to navigate the space of explanation methods, not only those in the toolkit but also in the broader literature on explainability. For data scientists and other users of the toolkit, we have implemented an extensible software architecture that organizes methods according to their place in the AI modeling pipeline. We also discuss enhancements to bring research innovations closer to consumers of explanations, ranging from simplified, more accessible versions of algorithms, to tutorials and an interactive web demo to introduce AI explainability to different audiences and application domains. Together, our toolkit and taxonomy can help identify gaps where more explainability methods are needed and provide a platform to incorporate them as they are developed.
Leveraging Simple Model Predictions for Enhancing its Performance
May 30, 2019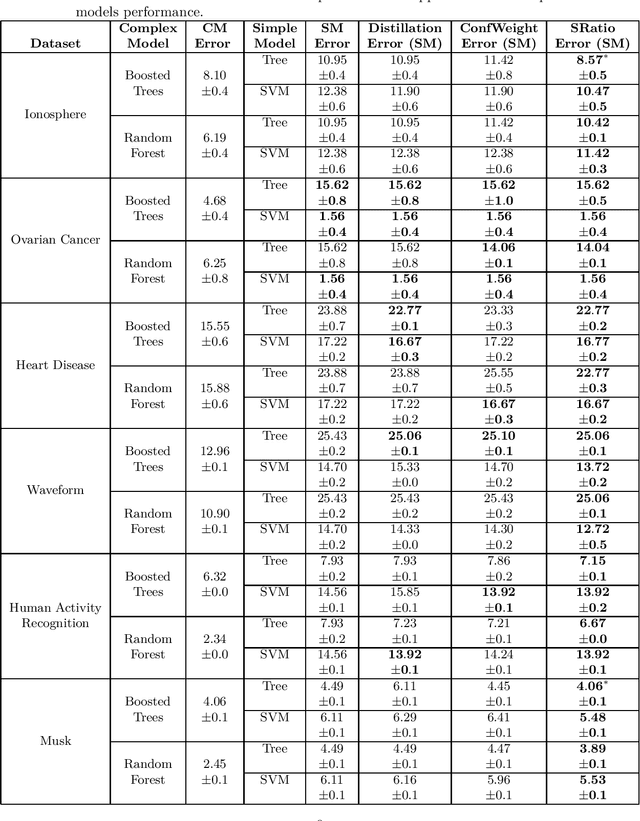
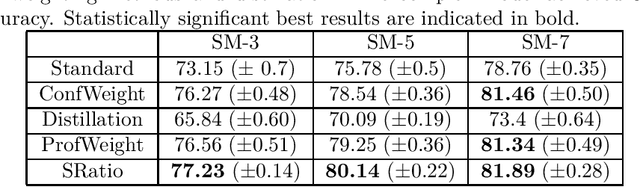
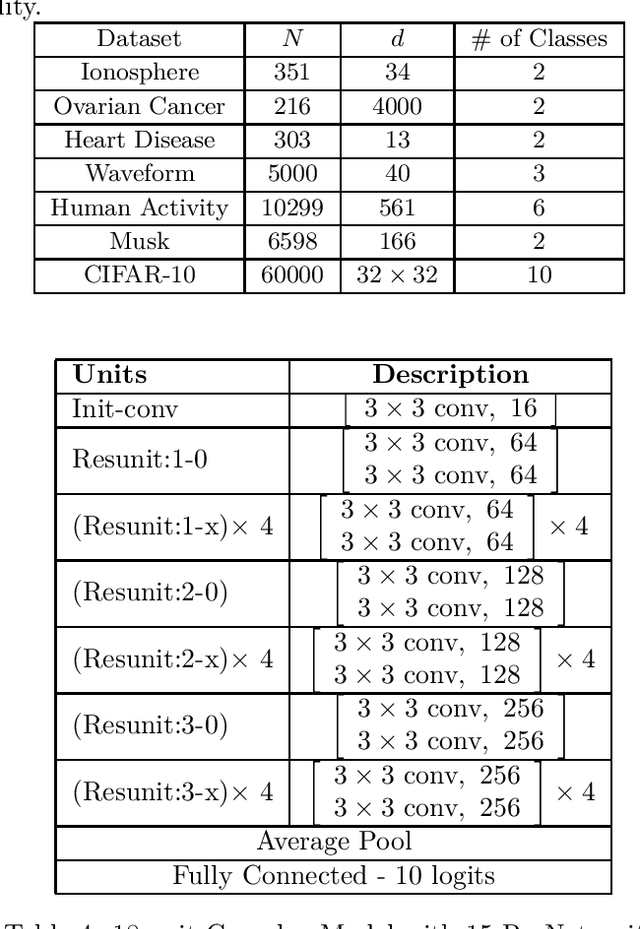
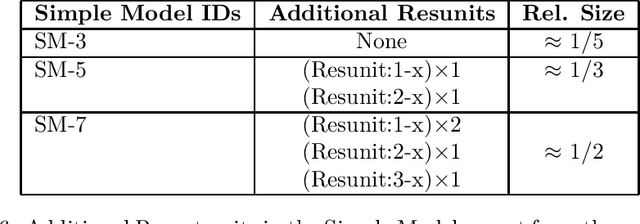
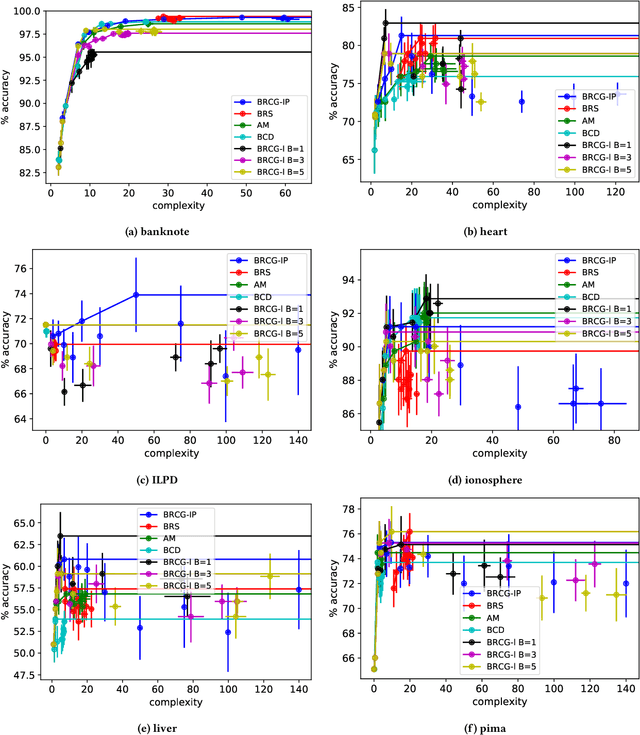
There has been recent interest in improving performance of simple models for multiple reasons such as interpretability, robust learning from small data, and deployment in memory constrained environments. In this paper, we propose a novel method SRatio that can utilize information from high performing complex models (viz. deep neural networks, boosted trees, random forests) to reweight a training dataset for a potentially low performing simple model such as a decision tree or a shallow network enhancing its performance. Our method also leverages the per sample hardness estimate of the simple model which is not the case with the prior works which primarily consider the complex model's confidences/predictions and is thus conceptually novel. Moreover, we generalize and formalize the concept of attaching probes to intermediate layers of a neural network, which was one of the main ideas in previous work, to other commonly used classifiers and incorporate this into our method. The benefit of these contributions is witnessed in the experiments where on 6 UCI datasets and CIFAR-10 we outperform competitors in a majority (16 out of 27) of the cases and tie for best performance in the remaining cases. In fact, in a couple of cases, we even approach the complex model's performance. We also show for popular loss functions such as cross-entropy loss, least squares loss, and hinge loss that the weighted loss minimized by simple models using our weighting is an upper bound on the loss of the complex model.
Generating Contrastive Explanations with Monotonic Attribute Functions
May 29, 2019
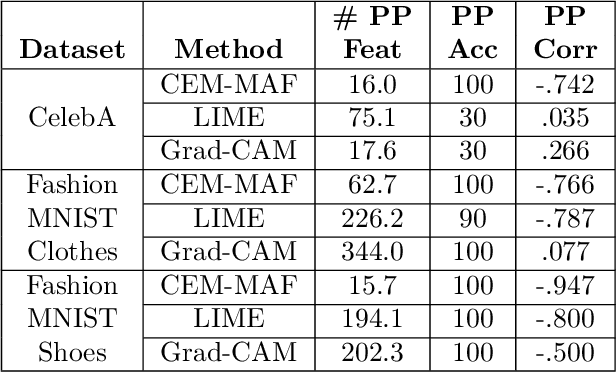
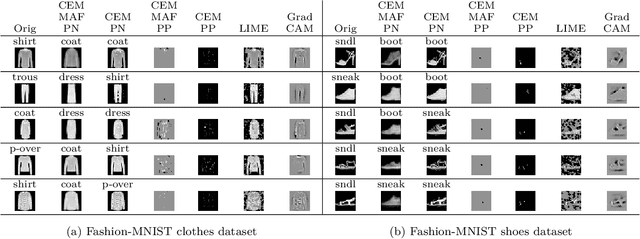
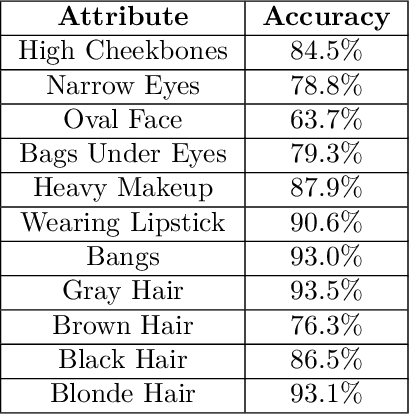
Explaining decisions of deep neural networks is a hot research topic with applications in medical imaging, video surveillance, and self driving cars. Many methods have been proposed in literature to explain these decisions by identifying relevance of different pixels. In this paper, we propose a method that can generate contrastive explanations for such data where we not only highlight aspects that are in themselves sufficient to justify the classification by the deep model, but also new aspects which if added will change the classification. One of our key contributions is how we define "addition" for such rich data in a formal yet humanly interpretable way that leads to meaningful results. This was one of the open questions laid out in Dhurandhar et.al. (2018) [5], which proposed a general framework for creating (local) contrastive explanations for deep models. We showcase the efficacy of our approach on CelebA and Fashion-MNIST in creating intuitive explanations that are also quantitatively superior compared with other state-of-the-art interpretability methods.
Explanations based on the Missing: Towards Contrastive Explanations with Pertinent Negatives
Oct 29, 2018
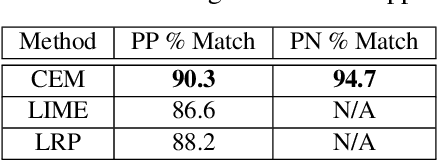

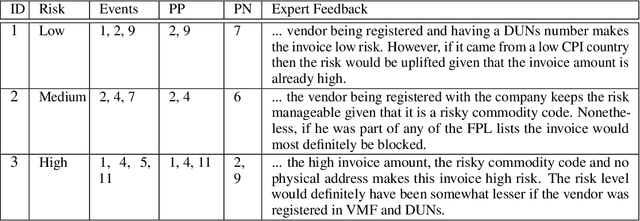
In this paper we propose a novel method that provides contrastive explanations justifying the classification of an input by a black box classifier such as a deep neural network. Given an input we find what should be %necessarily and minimally and sufficiently present (viz. important object pixels in an image) to justify its classification and analogously what should be minimally and necessarily \emph{absent} (viz. certain background pixels). We argue that such explanations are natural for humans and are used commonly in domains such as health care and criminology. What is minimally but critically \emph{absent} is an important part of an explanation, which to the best of our knowledge, has not been explicitly identified by current explanation methods that explain predictions of neural networks. We validate our approach on three real datasets obtained from diverse domains; namely, a handwritten digits dataset MNIST, a large procurement fraud dataset and a brain activity strength dataset. In all three cases, we witness the power of our approach in generating precise explanations that are also easy for human experts to understand and evaluate.
TIP: Typifying the Interpretability of Procedures
Oct 29, 2018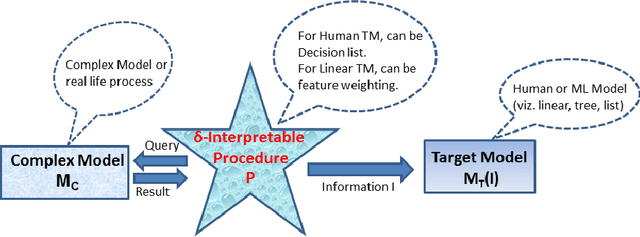
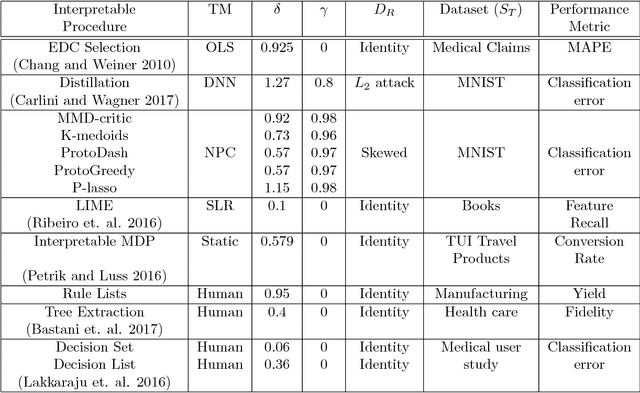
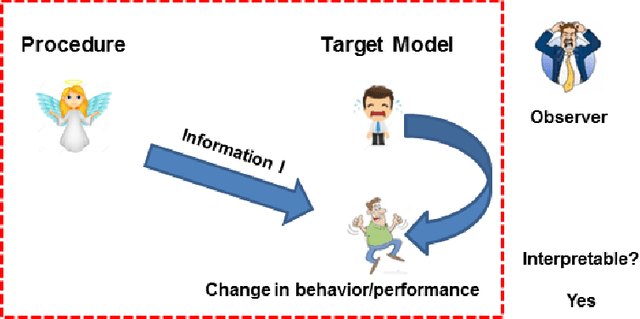

We provide a novel notion of what it means to be interpretable, looking past the usual association with human understanding. Our key insight is that interpretability is not an absolute concept and so we define it relative to a target model, which may or may not be a human. We define a framework that allows for comparing interpretable procedures by linking them to important practical aspects such as accuracy and robustness. We characterize many of the current state-of-the-art interpretable methods in our framework portraying its general applicability. Finally, principled interpretable strategies are proposed and empirically evaluated on synthetic data, as well as on the largest public olfaction dataset that was made recently available \cite{olfs}. We also experiment on MNIST with a simple target model and different oracle models of varying complexity. This leads to the insight that the improvement in the target model is not only a function of the oracle model's performance, but also its relative complexity with respect to the target model. Further experiments on CIFAR-10, a real manufacturing dataset and FICO dataset showcase the benefit of our methods over Knowledge Distillation when the target models are simple and the complex model is a neural network.
Beyond Backprop: Online Alternating Minimization with Auxiliary Variables
Oct 24, 2018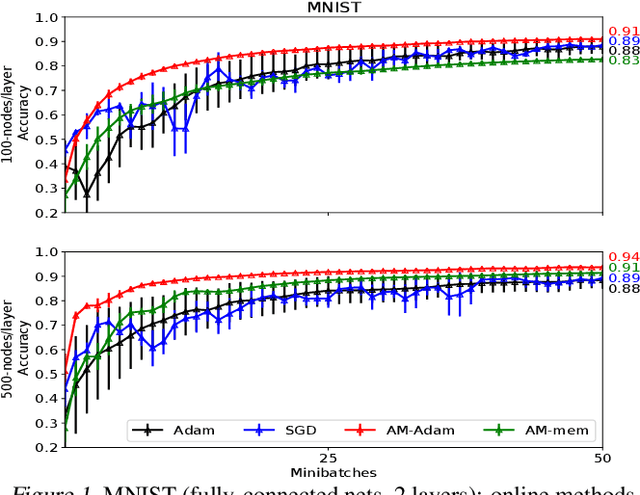
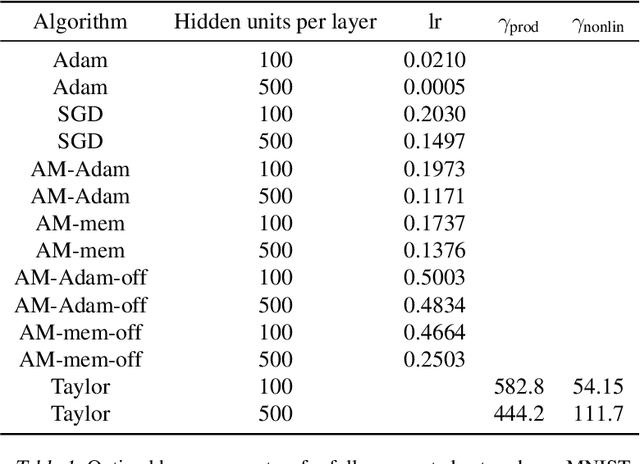
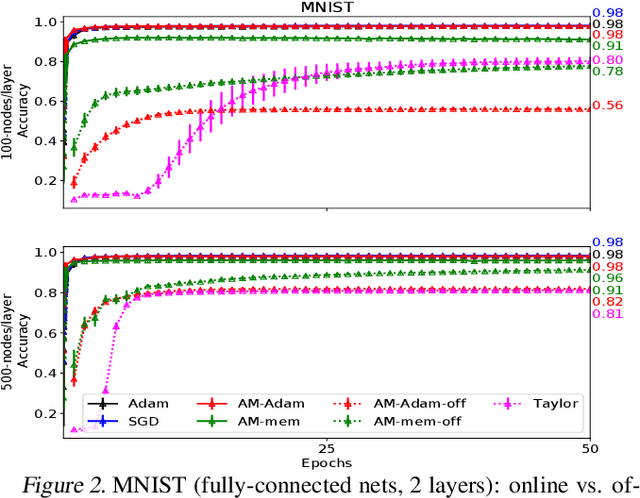
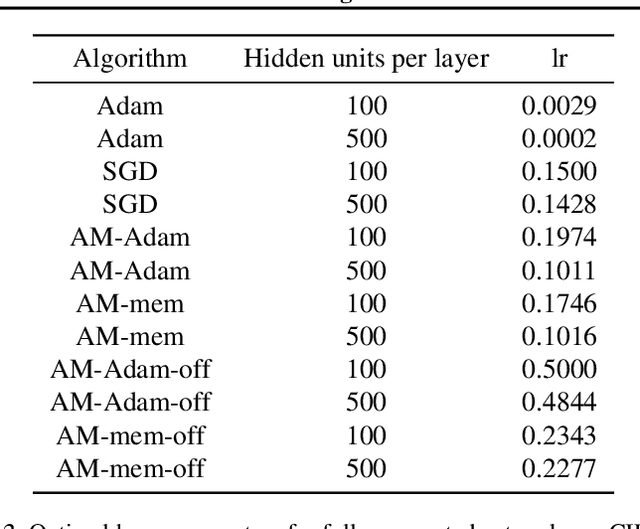
We propose a novel online alternating minimization (AltMin) algorithm for training deep neural networks, provide theoretical convergence guarantees and demonstrate its advantages on several classification tasks as compared both to standard backpropagation with stochastic gradient descent (backprop-SGD) and to offline alternating minimization. The key difference from backpropagation is an explicit optimization over hidden activations, which eliminates gradient chain computation in backprop, and breaks the weight training problem into independent, local optimization subproblems; this allows to avoid vanishing gradient issues, simplify handling non-differentiable nonlinearities, and perform parallel weight updates across the layers. Moreover, parallel local synaptic weight optimization with explicit activation propagation is a step closer to a more biologically plausible learning model than backpropagation, whose biological implausibility has been frequently criticized. Finally, the online nature of our approach allows to handle very large datasets, as well as continual, lifelong learning, which is our key contribution on top of recently proposed offline alternating minimization schemes (e.g., (Carreira-Perpinan andWang 2014), (Taylor et al. 2016)).
Stochastic Gradient Descent with Biased but Consistent Gradient Estimators
Jul 31, 2018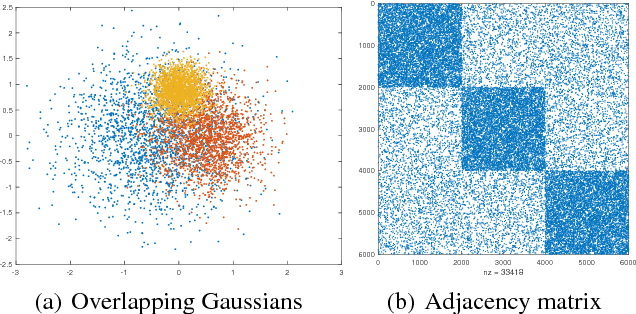
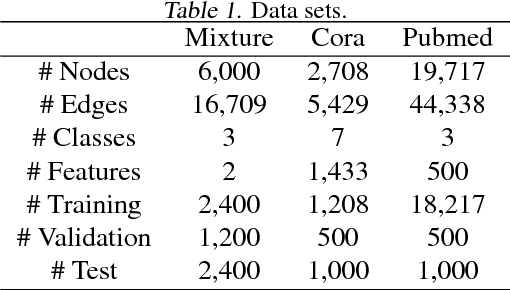
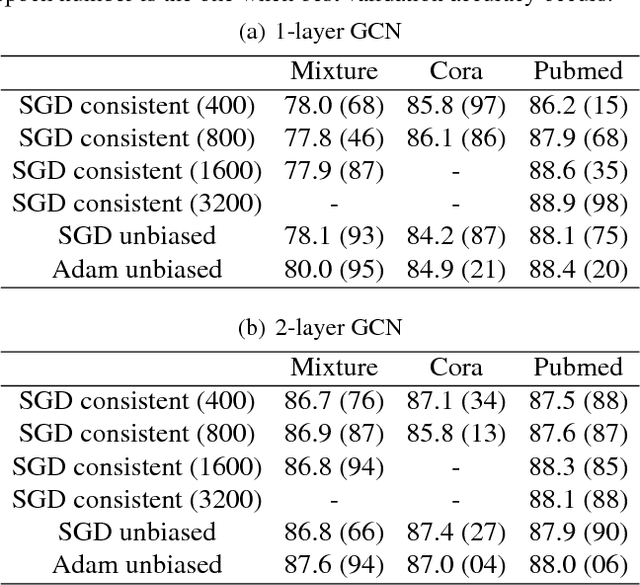
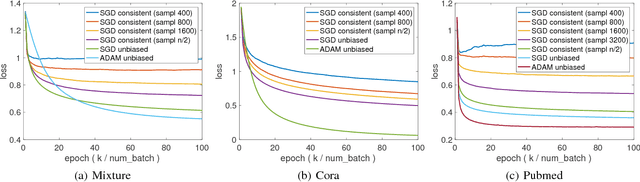
Stochastic gradient descent (SGD), which dates back to the 1950s, is one of the most popular and effective approaches for performing stochastic optimization. Research on SGD resurged recently in machine learning for optimizing convex loss functions as well as training nonconvex deep neural networks. The theory assumes that one can easily compute an unbiased gradient estimator, which is usually the case due to the sample average nature of empirical risk minimization. There exist, however, many scenarios (e.g., graph learning) where an unbiased estimator may be as expensive to compute as the full gradient, because training examples are interconnected. In a recent work, Chen et al. (2018) proposed using a consistent gradient estimator as an economic alternative. Encouraged by empirical success, we show, in a general setting, that consistent estimators result in the same convergence behavior as do unbiased ones. Our analysis covers strongly convex, convex, and nonconvex objectives. This work opens several new research directions, including the development of more efficient SGD updates with consistent estimators and the design of efficient training algorithms for large-scale graphs.
Improving Simple Models with Confidence Profiles
Jul 19, 2018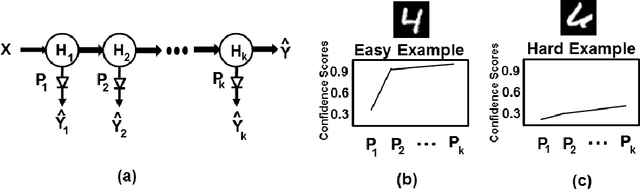
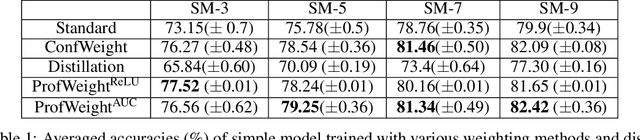
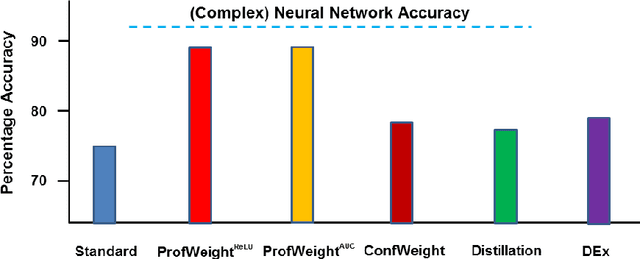
In this paper, we propose a new method called ProfWeight for transferring information from a pre-trained deep neural network that has a high test accuracy to a simpler interpretable model or a very shallow network of low complexity and a priori low test accuracy. We are motivated by applications in interpretability and model deployment in severely memory constrained environments (like sensors). Our method uses linear probes to generate confidence scores through flattened intermediate representations. Our transfer method involves a theoretically justified weighting of samples during the training of the simple model using confidence scores of these intermediate layers. The value of our method is first demonstrated on CIFAR-10, where our weighting method significantly improves (3-4%) networks with only a fraction of the number of Resnet blocks of a complex Resnet model. We further demonstrate operationally significant results on a real manufacturing problem, where we dramatically increase the test accuracy of a CART model (the domain standard) by roughly 13%.
A Formal Framework to Characterize Interpretability of Procedures
Jul 12, 2017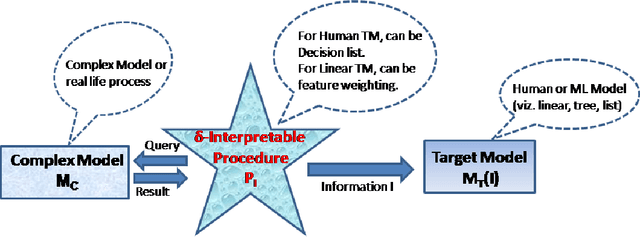
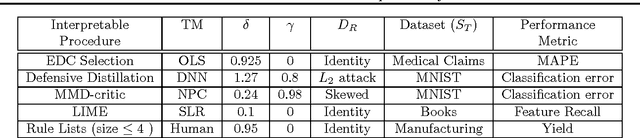
We provide a novel notion of what it means to be interpretable, looking past the usual association with human understanding. Our key insight is that interpretability is not an absolute concept and so we define it relative to a target model, which may or may not be a human. We define a framework that allows for comparing interpretable procedures by linking it to important practical aspects such as accuracy and robustness. We characterize many of the current state-of-the-art interpretable methods in our framework portraying its general applicability.