 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraTrace: Temporal Signature Land Use Mapping System
Feb 25, 2025



Understanding land use over time is critical to tracking events related to climate change, like deforestation. However, satellite-based remote sensing tools which are used for monitoring struggle to differentiate vegetation types in farms and orchards from forests. We observe that metrics such as the Normalized Difference Vegetation Index (NDVI), based on plant photosynthesis, have unique temporal signatures that reflect agricultural practices and seasonal cycles. We analyze yearly NDVI changes on 20 farms for 10 unique crops. Initial results show that NDVI curves are coherent with agricultural practices, are unique to each crop, consistent globally, and can differentiate farms from forests. We develop a novel longitudinal NDVI dataset for the state of California from 2020-2023 with 500~m resolution and over 70 million points. We use this to develop the TerraTrace platform, an end-to-end analytic tool that classifies land use using NDVI signatures and allows users to query the system through an LLM chatbot and graphical interface.
Enabling Adoption of Regenerative Agriculture through Soil Carbon Copilots
Nov 25, 2024



Mitigating climate change requires transforming agriculture to minimize environ mental impact and build climate resilience. Regenerative agricultural practices enhance soil organic carbon (SOC) levels, thus improving soil health and sequestering carbon. A challenge to increasing regenerative agriculture practices is cheaply measuring SOC over time and understanding how SOC is affected by regenerative agricultural practices and other environmental factors and farm management practices. To address this challenge, we introduce an AI-driven Soil Organic Carbon Copilot that automates the ingestion of complex multi-resolution, multi-modal data to provide large-scale insights into soil health and regenerative practices. Our data includes extreme weather event data (e.g., drought and wildfire incidents), farm management data (e.g., cropland information and tillage predictions), and SOC predictions. We find that integrating public data and specialized models enables large-scale, localized analysis for sustainable agriculture. In comparisons of agricultural practices across California counties, we find evidence that diverse agricultural activity may mitigate the negative effects of tillage; and that while extreme weather conditions heavily affect SOC, composting may mitigate SOC loss. Finally, implementing role-specific personas empowers agronomists, farm consultants, policymakers, and other stakeholders to implement evidence-based strategies that promote sustainable agriculture and build climate resilience.
Remote Sensing for Weed Detection and Control
Oct 29, 2024



Italian ryegrass is a grass weed commonly found in winter wheat fields that are competitive with winter wheat for moisture and nutrients. Ryegrass can cause substantial reductions in yield and grain quality if not properly controlled with the use of herbicides. To control the cost and environmental impact we detect weeds in drone and satellite imagery. Satellite imagery is too coarse to be used for precision spraying, but can aid in planning drone flights and treatments. Drone images on the other hand have sufficiently good resolution for precision spraying. However, ryegrass is hard to distinguish from the crop and annotation requires expert knowledge. We used the Python segmentation models library to test more than 600 different neural network architectures for weed segmentation in drone images and we map accuracy versus the cost of the model prediction for these. Our best system applies herbicides to over 99% of the weeds while only spraying an area 30% larger than the annotated weed area. These models yield large savings if the weed covers a small part of the field.
Counting and Segmenting Sorghum Heads
May 30, 2019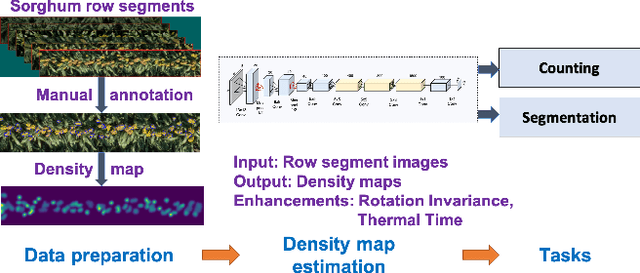
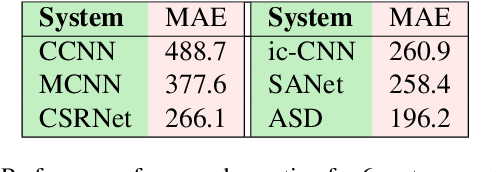
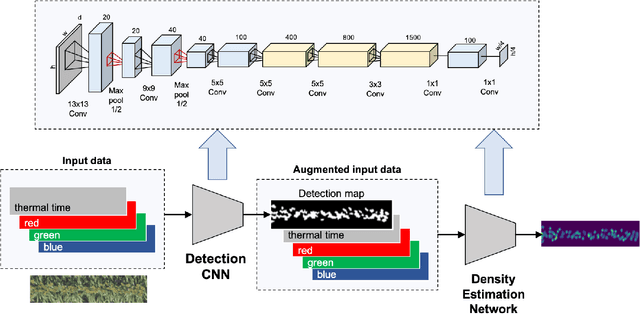

Phenotyping is the process of measuring an organism's observable traits. Manual phenotyping of crops is a labor-intensive, time-consuming, costly, and error prone process. Accurate, automated, high-throughput phenotyping can relieve a huge burden in the crop breeding pipeline. In this paper, we propose a scalable, high-throughput approach to automatically count and segment panicles (heads), a key phenotype, from aerial sorghum crop imagery. Our counting approach uses the image density map obtained from dot or region annotation as the target with a novel deep convolutional neural network architecture. We also propose a novel instance segmentation algorithm using the estimated density map, to identify the individual panicles in the presence of occlusion. With real Sorghum aerial images, we obtain a mean absolute error (MAE) of 1.06 for counting which is better than using well-known crowd counting approaches such as CCNN, MCNN and CSRNet models. The instance segmentation model also produces respectable results which will be ultimately useful in reducing the manual annotation workload for future data.
Improving Simple Models with Confidence Profiles
Jul 19, 2018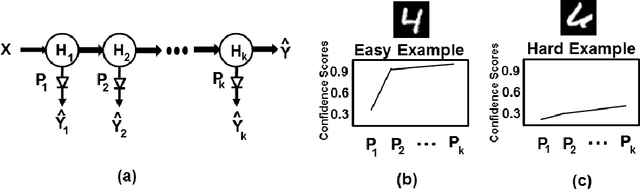
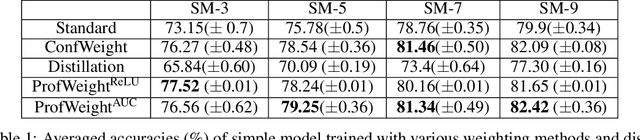
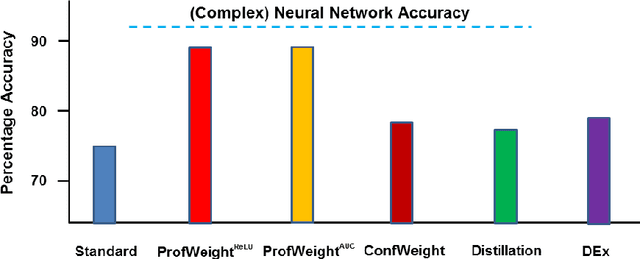
In this paper, we propose a new method called ProfWeight for transferring information from a pre-trained deep neural network that has a high test accuracy to a simpler interpretable model or a very shallow network of low complexity and a priori low test accuracy. We are motivated by applications in interpretability and model deployment in severely memory constrained environments (like sensors). Our method uses linear probes to generate confidence scores through flattened intermediate representations. Our transfer method involves a theoretically justified weighting of samples during the training of the simple model using confidence scores of these intermediate layers. The value of our method is first demonstrated on CIFAR-10, where our weighting method significantly improves (3-4%) networks with only a fraction of the number of Resnet blocks of a complex Resnet model. We further demonstrate operationally significant results on a real manufacturing problem, where we dramatically increase the test accuracy of a CART model (the domain standard) by roughly 13%.
A variational approach to stable principal component pursuit
Jun 04, 2014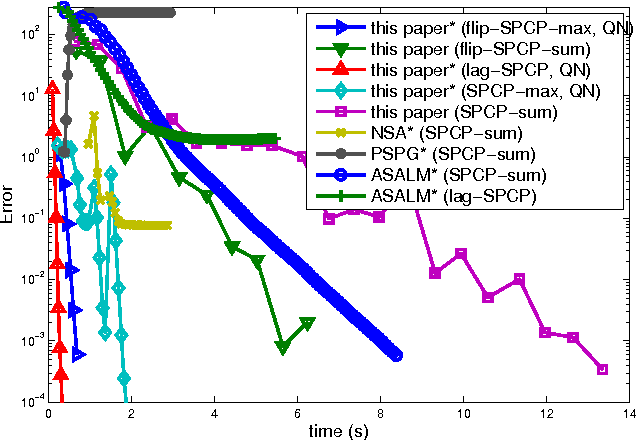
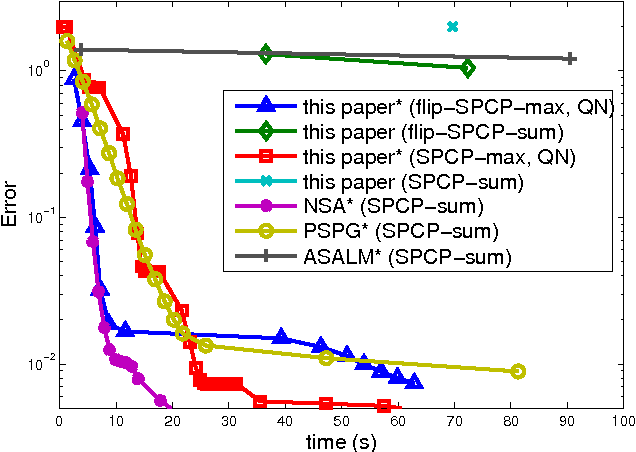
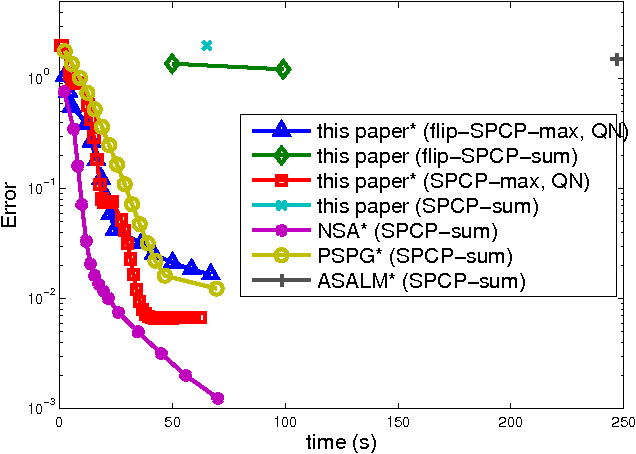

We introduce a new convex formulation for stable principal component pursuit (SPCP) to decompose noisy signals into low-rank and sparse representations. For numerical solutions of our SPCP formulation, we first develop a convex variational framework and then accelerate it with quasi-Newton methods. We show, via synthetic and real data experiments, that our approach offers advantages over the classical SPCP formulations in scalability and practical parameter selection.