 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Does Multi-Epoch Training Help?
May 13, 2021Stochastic gradient descent (SGD) has become the most attractive optimization method in training large-scale deep neural networks due to its simplicity, low computational cost in each updating step, and good performance. Standard excess risk bounds show that SGD only needs to take one pass over the training data and more passes could not help to improve the performance. Empirically, it has been observed that SGD taking more than one pass over the training data (multi-pass SGD) has much better excess risk bound performance than the SGD only taking one pass over the training data (one-pass SGD). However, it is not very clear that how to explain this phenomenon in theory. In this paper, we provide some theoretical evidences for explaining why multiple passes over the training data can help improve performance under certain circumstance. Specifically, we consider smooth risk minimization problems whose objective function is non-convex least squared loss. Under Polyak-Lojasiewicz (PL) condition, we establish faster convergence rate of excess risk bound for multi-pass SGD than that for one-pass SGD.
On Stochastic Moving-Average Estimators for Non-Convex Optimization
Apr 30, 2021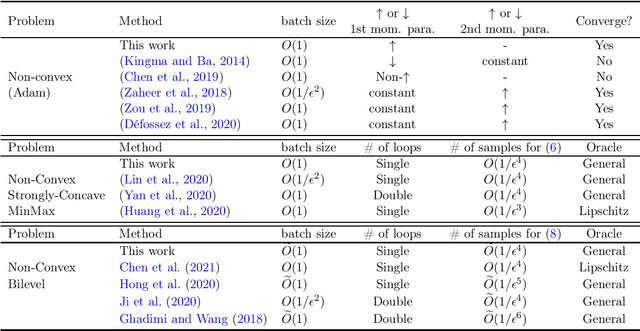
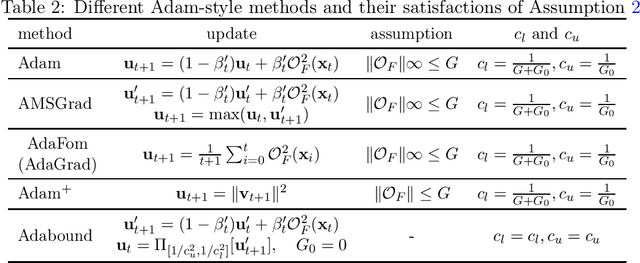
In this paper, we demonstrate the power of a widely used stochastic estimator based on moving average (SEMA) on a range of stochastic non-convex optimization problems, which only requires {\bf a general unbiased stochastic oracle}. We analyze various stochastic methods (existing or newly proposed) based on the {\bf variance recursion property} of SEMA for three families of non-convex optimization, namely standard stochastic non-convex minimization, stochastic non-convex strongly-concave min-max optimization, and stochastic bilevel optimization. Our contributions include: (i) for standard stochastic non-convex minimization, we present a simple and intuitive proof of convergence for a family Adam-style methods (including Adam) with an increasing or large "momentum" parameter for the first-order moment, which gives an alternative yet more natural way to guarantee Adam converge; (ii) for stochastic non-convex strongly-concave min-max optimization, we present a single-loop stochastic gradient descent ascent method based on the moving average estimators and establish its oracle complexity of $O(1/\epsilon^4)$ without using a large mini-batch size, addressing a gap in the literature; (iii) for stochastic bilevel optimization, we present a single-loop stochastic method based on the moving average estimators and establish its oracle complexity of $\widetilde O(1/\epsilon^4)$ without computing the inverse or SVD of the Hessian matrix, improving state-of-the-art results. For all these problems, we also establish a variance diminishing result for the used stochastic gradient estimators.
Learning Position and Target Consistency for Memory-based Video Object Segmentation
Apr 09, 2021
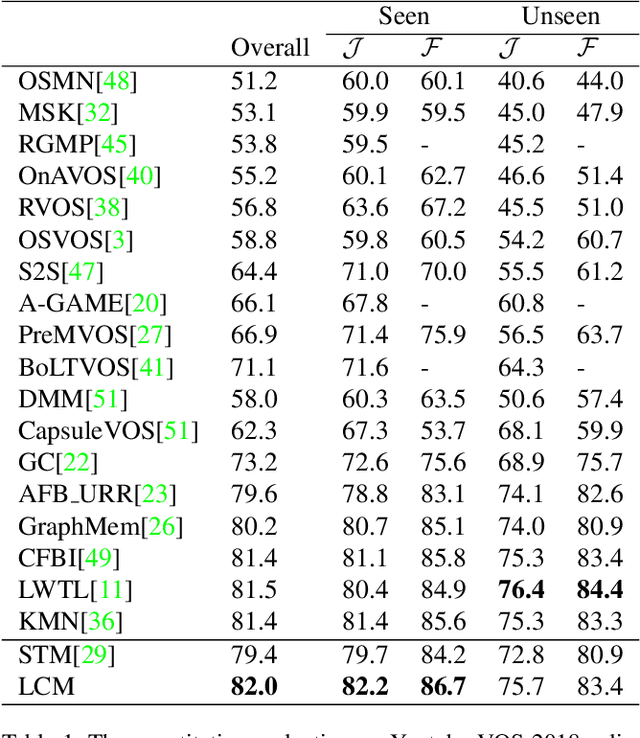
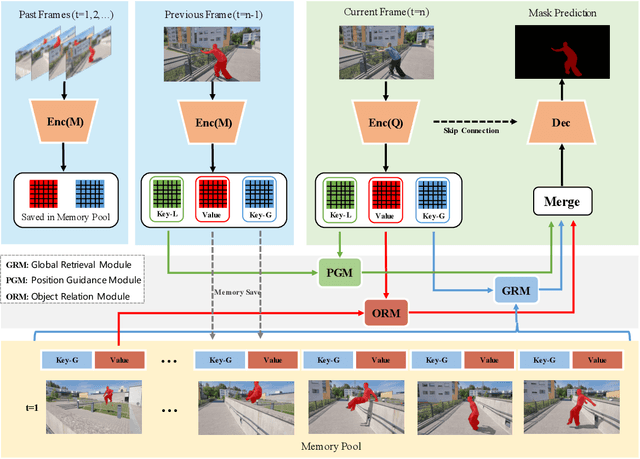
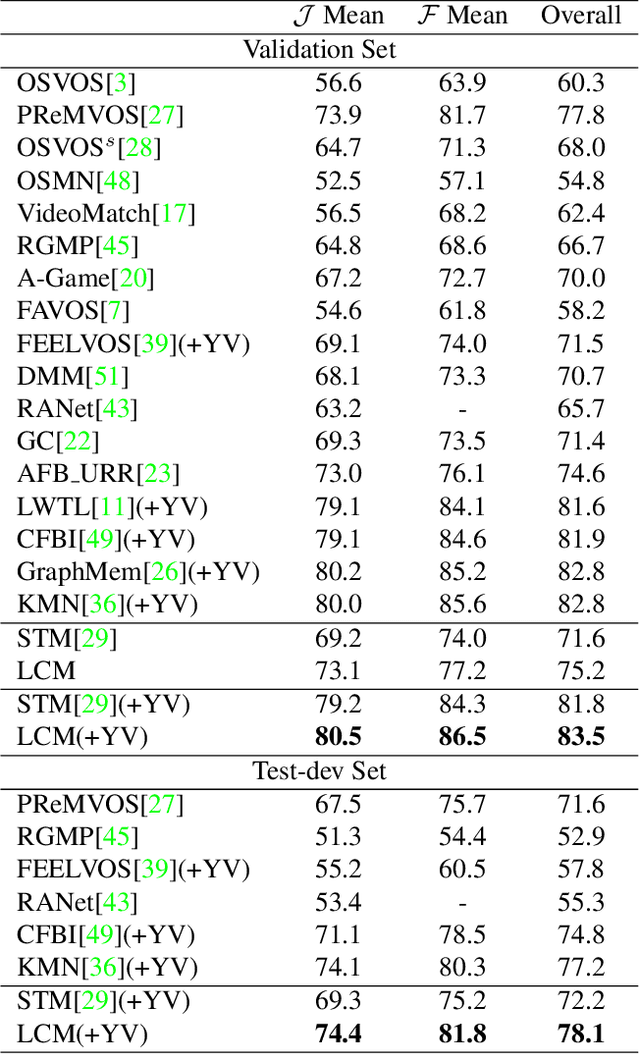
This paper studies the problem of semi-supervised video object segmentation(VOS). Multiple works have shown that memory-based approaches can be effective for video object segmentation. They are mostly based on pixel-level matching, both spatially and temporally. The main shortcoming of memory-based approaches is that they do not take into account the sequential order among frames and do not exploit object-level knowledge from the target. To address this limitation, we propose to Learn position and target Consistency framework for Memory-based video object segmentation, termed as LCM. It applies the memory mechanism to retrieve pixels globally, and meanwhile learns position consistency for more reliable segmentation. The learned location response promotes a better discrimination between target and distractors. Besides, LCM introduces an object-level relationship from the target to maintain target consistency, making LCM more robust to error drifting. Experiments show that our LCM achieves state-of-the-art performance on both DAVIS and Youtube-VOS benchmark. And we rank the 1st in the DAVIS 2020 challenge semi-supervised VOS task.
A Theoretical Analysis of Learning with Noisily Labeled Data
Apr 08, 2021Noisy labels are very common in deep supervised learning. Although many studies tend to improve the robustness of deep training for noisy labels, rare works focus on theoretically explaining the training behaviors of learning with noisily labeled data, which is a fundamental principle in understanding its generalization. In this draft, we study its two phenomena, clean data first and phase transition, by explaining them from a theoretical viewpoint. Specifically, we first show that in the first epoch training, the examples with clean labels will be learned first. We then show that after the learning from clean data stage, continuously training model can achieve further improvement in testing error when the rate of corrupted class labels is smaller than a certain threshold; otherwise, extensively training could lead to an increasing testing error.
Self-supervised Video Representation Learning by Context and Motion Decoupling
Apr 02, 2021
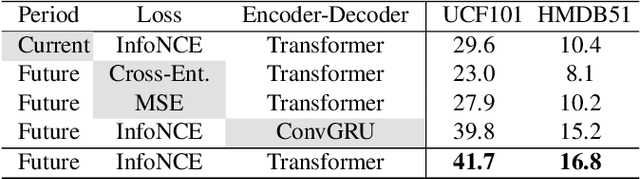
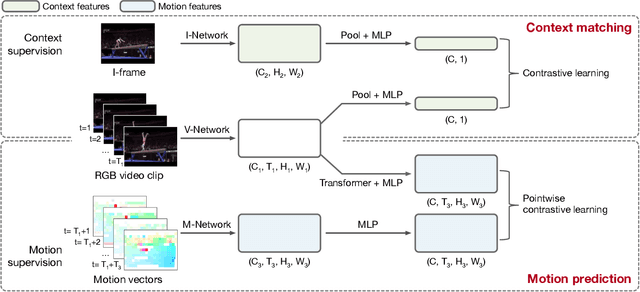
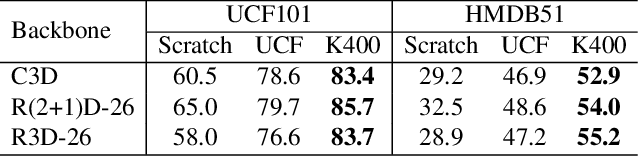
A key challenge in self-supervised video representation learning is how to effectively capture motion information besides context bias. While most existing works implicitly achieve this with video-specific pretext tasks (e.g., predicting clip orders, time arrows, and paces), we develop a method that explicitly decouples motion supervision from context bias through a carefully designed pretext task. Specifically, we take the keyframes and motion vectors in compressed videos (e.g., in H.264 format) as the supervision sources for context and motion, respectively, which can be efficiently extracted at over 500 fps on the CPU. Then we design two pretext tasks that are jointly optimized: a context matching task where a pairwise contrastive loss is cast between video clip and keyframe features; and a motion prediction task where clip features, passed through an encoder-decoder network, are used to estimate motion features in a near future. These two tasks use a shared video backbone and separate MLP heads. Experiments show that our approach improves the quality of the learned video representation over previous works, where we obtain absolute gains of 16.0% and 11.1% in video retrieval recall on UCF101 and HMDB51, respectively. Moreover, we find the motion prediction to be a strong regularization for video networks, where using it as an auxiliary task improves the accuracy of action recognition with a margin of 7.4%~13.8%.
Self-supervised Motion Learning from Static Images
Apr 01, 2021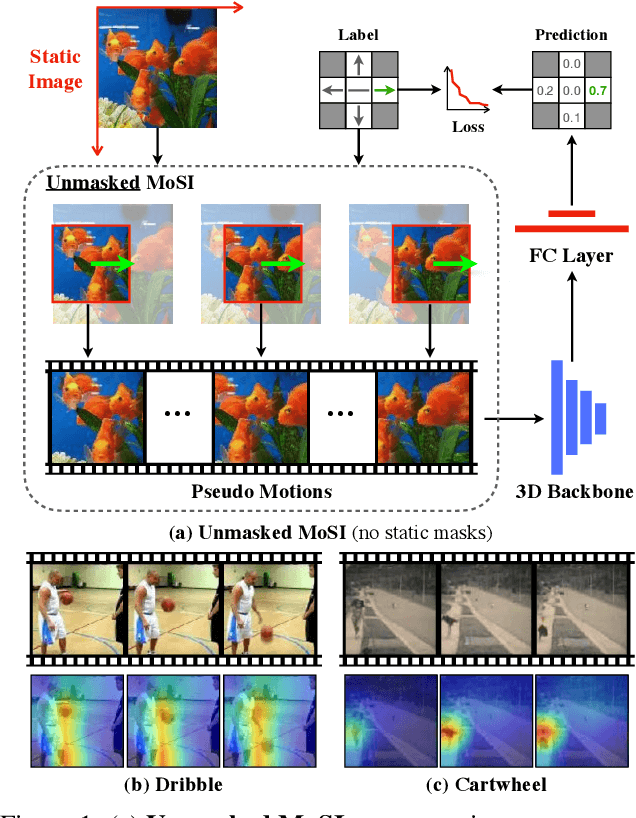
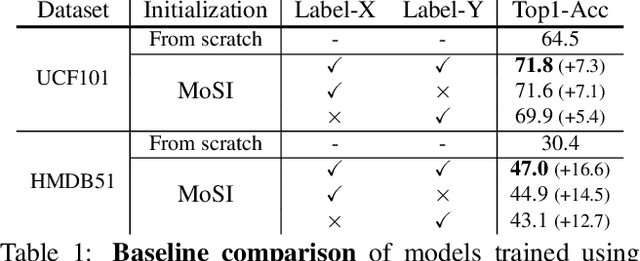
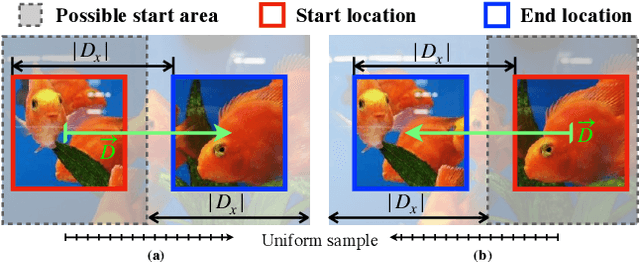
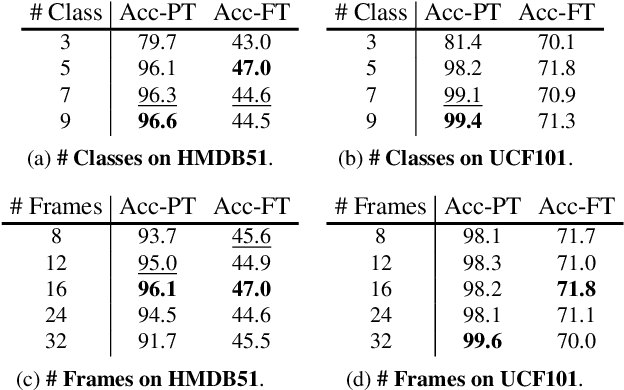
Motions are reflected in videos as the movement of pixels, and actions are essentially patterns of inconsistent motions between the foreground and the background. To well distinguish the actions, especially those with complicated spatio-temporal interactions, correctly locating the prominent motion areas is of crucial importance. However, most motion information in existing videos are difficult to label and training a model with good motion representations with supervision will thus require a large amount of human labour for annotation. In this paper, we address this problem by self-supervised learning. Specifically, we propose to learn Motion from Static Images (MoSI). The model learns to encode motion information by classifying pseudo motions generated by MoSI. We furthermore introduce a static mask in pseudo motions to create local motion patterns, which forces the model to additionally locate notable motion areas for the correct classification.We demonstrate that MoSI can discover regions with large motion even without fine-tuning on the downstream datasets. As a result, the learned motion representations boost the performance of tasks requiring understanding of complex scenes and motions, i.e., action recognition. Extensive experiments show the consistent and transferable improvements achieved by MoSI. Codes will be soon released.
CobBO: Coordinate Backoff Bayesian Optimization
Feb 16, 2021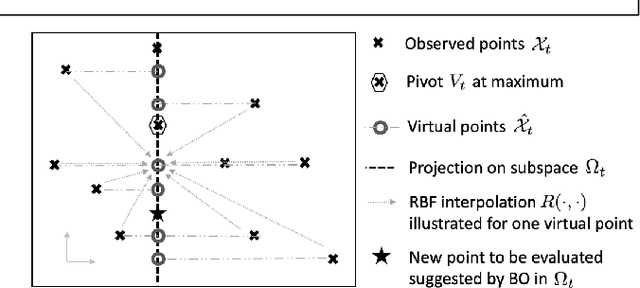

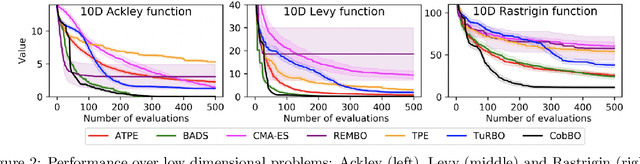

Bayesian optimization is a popular method for optimizing expensive black-box functions. The objective functions of hard real world problems are oftentimes characterized by a fluctuated landscape of many local optima. Bayesian optimization risks in over-exploiting such traps, remaining with insufficient query budget for exploring the global landscape. We introduce Coordinate Backoff Bayesian Optimization (CobBO) to alleviate those challenges. CobBO captures a smooth approximation of the global landscape by interpolating the values of queried points projected to randomly selected promising subspaces. Thus also a smaller query budget is required for the Gaussian process regressions applied over the lower dimensional subspaces. This approach can be viewed as a variant of coordinate ascent, tailored for Bayesian optimization, using a stopping rule for backing off from a certain subspace and switching to another coordinate subset. Extensive evaluations show that CobBO finds solutions comparable to or better than other state-of-the-art methods for dimensions ranging from tens to hundreds, while reducing the trial complexity.
Train a One-Million-Way Instance Classifier for Unsupervised Visual Representation Learning
Feb 09, 2021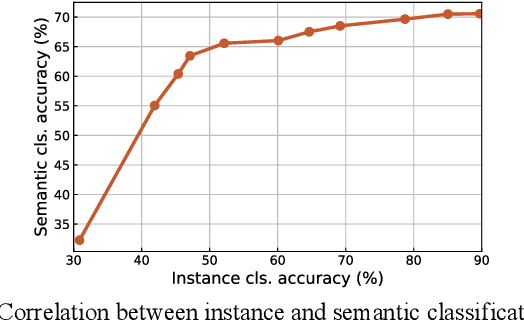
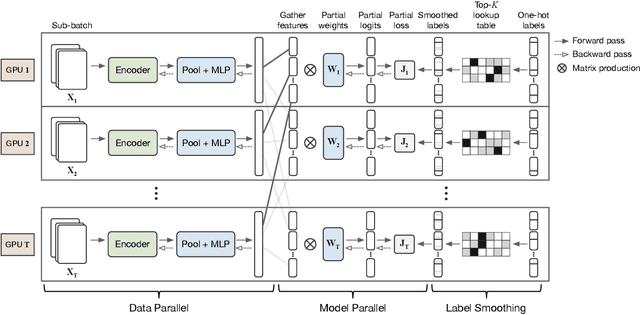
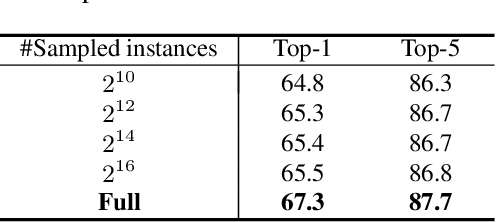

This paper presents a simple unsupervised visual representation learning method with a pretext task of discriminating all images in a dataset using a parametric, instance-level classifier. The overall framework is a replica of a supervised classification model, where semantic classes (e.g., dog, bird, and ship) are replaced by instance IDs. However, scaling up the classification task from thousands of semantic labels to millions of instance labels brings specific challenges including 1) the large-scale softmax computation; 2) the slow convergence due to the infrequent visiting of instance samples; and 3) the massive number of negative classes that can be noisy. This work presents several novel techniques to handle these difficulties. First, we introduce a hybrid parallel training framework to make large-scale training feasible. Second, we present a raw-feature initialization mechanism for classification weights, which we assume offers a contrastive prior for instance discrimination and can clearly speed up converge in our experiments. Finally, we propose to smooth the labels of a few hardest classes to avoid optimizing over very similar negative pairs. While being conceptually simple, our framework achieves competitive or superior performance compared to state-of-the-art unsupervised approaches, i.e., SimCLR, MoCoV2, and PIC under ImageNet linear evaluation protocol and on several downstream visual tasks, verifying that full instance classification is a strong pretraining technique for many semantic visual tasks.
Large-Scale Training System for 100-Million Classification at Alibaba
Feb 09, 2021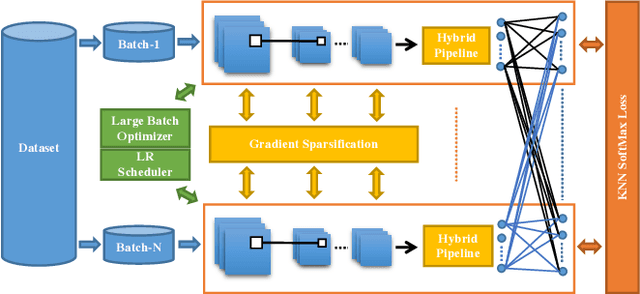
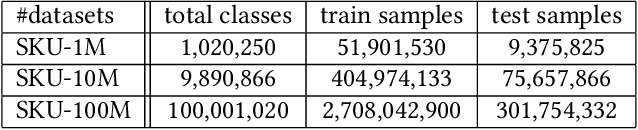
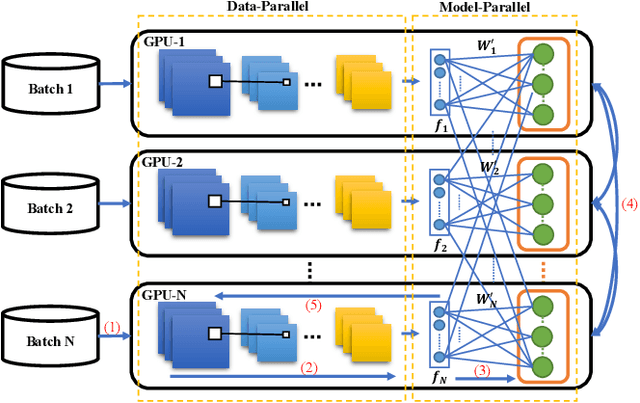
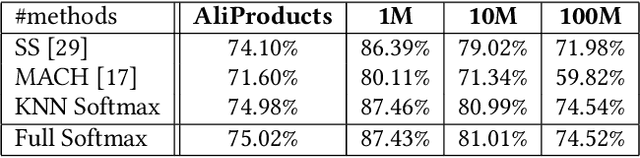
In the last decades, extreme classification has become an essential topic for deep learning. It has achieved great success in many areas, especially in computer vision and natural language processing (NLP). However, it is very challenging to train a deep model with millions of classes due to the memory and computation explosion in the last output layer. In this paper, we propose a large-scale training system to address these challenges. First, we build a hybrid parallel training framework to make the training process feasible. Second, we propose a novel softmax variation named KNN softmax, which reduces both the GPU memory consumption and computation costs and improves the throughput of training. Then, to eliminate the communication overhead, we propose a new overlapping pipeline and a gradient sparsification method. Furthermore, we design a fast continuous convergence strategy to reduce total training iterations by adaptively adjusting learning rate and updating model parameters. With the help of all the proposed methods, we gain 3.9$\times$ throughput of our training system and reduce almost 60\% of training iterations. The experimental results show that using an in-house 256 GPUs cluster, we could train a classifier of 100 million classes on Alibaba Retail Product Dataset in about five days while achieving a comparable accuracy with the naive softmax training process.
Visual Search at Alibaba
Feb 09, 2021

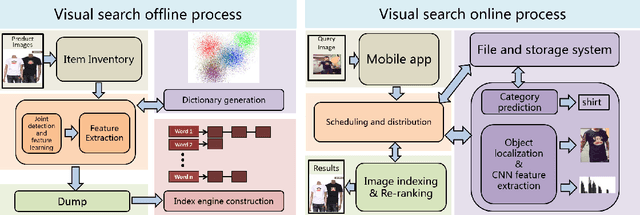
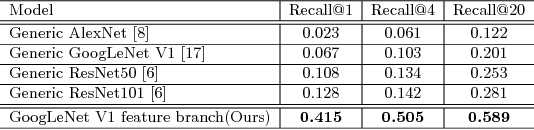
This paper introduces the large scale visual search algorithm and system infrastructure at Alibaba. The following challenges are discussed under the E-commercial circumstance at Alibaba (a) how to handle heterogeneous image data and bridge the gap between real-shot images from user query and the online images. (b) how to deal with large scale indexing for massive updating data. (c) how to train deep models for effective feature representation without huge human annotations. (d) how to improve the user engagement by considering the quality of the content. We take advantage of large image collection of Alibaba and state-of-the-art deep learning techniques to perform visual search at scale. We present solutions and implementation details to overcome those problems and also share our learnings from building such a large scale commercial visual search engine. Specifically, model and search-based fusion approach is introduced to effectively predict categories. Also, we propose a deep CNN model for joint detection and feature learning by mining user click behavior. The binary index engine is designed to scale up indexing without compromising recall and precision. Finally, we apply all the stages into an end-to-end system architecture, which can simultaneously achieve highly efficient and scalable performance adapting to real-shot images. Extensive experiments demonstrate the advancement of each module in our system. We hope visual search at Alibaba becomes more widely incorporated into today's commercial applications.
* accepted by KDD 2018