 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI2D2: Inductive Knowledge Distillation with NeuroLogic and Self-Imitation
Dec 19, 2022


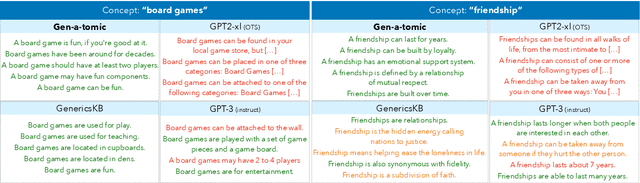
Pre-trained language models, despite their rapid advancements powered by scale, still fall short of robust commonsense capabilities. And yet, scale appears to be the winning recipe; after all, the largest models seem to have acquired the largest amount of commonsense capabilities. Or is it? In this paper, we investigate the possibility of a seemingly impossible match: can smaller language models with dismal commonsense capabilities (i.e., GPT-2), ever win over models that are orders of magnitude larger and better (i.e., GPT-3), if the smaller models are powered with novel commonsense distillation algorithms? The key intellectual question we ask here is whether it is possible, if at all, to design a learning algorithm that does not benefit from scale, yet leads to a competitive level of commonsense acquisition. In this work, we study the generative models of commonsense knowledge, focusing on the task of generating generics, statements of commonsense facts about everyday concepts, e.g., birds can fly. We introduce a novel commonsense distillation framework, I2D2, that loosely follows the Symbolic Knowledge Distillation of West et al. but breaks the dependence on the extreme-scale models as the teacher model by two innovations: (1) the novel adaptation of NeuroLogic Decoding to enhance the generation quality of the weak, off-the-shelf language models, and (2) self-imitation learning to iteratively learn from the model's own enhanced commonsense acquisition capabilities. Empirical results suggest that scale is not the only way, as novel algorithms can be a promising alternative. Moreover, our study leads to a new corpus of generics, Gen-A-Tomic, that is of the largest and highest quality available to date.
RealTime QA: What's the Answer Right Now?
Jul 27, 2022
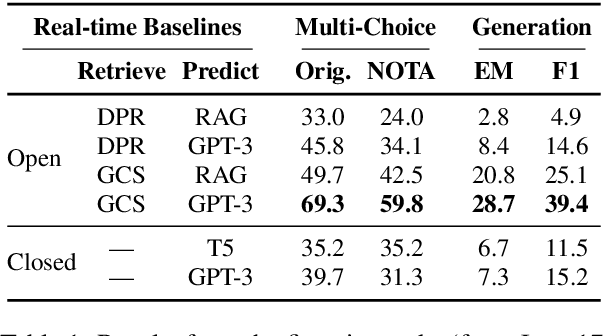
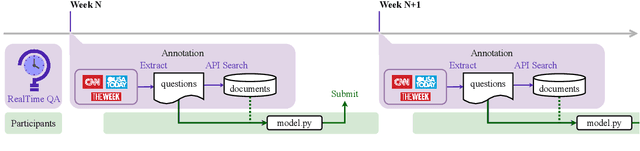
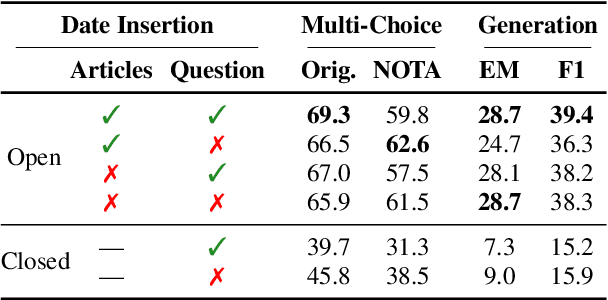
We introduce RealTime QA, a dynamic question answering (QA) platform that announces questions and evaluates systems on a regular basis (weekly in this version). RealTime QA inquires about the current world, and QA systems need to answer questions about novel events or information. It therefore challenges static, conventional assumptions in open domain QA datasets and pursues, instantaneous applications. We build strong baseline models upon large pretrained language models, including GPT-3 and T5. Our benchmark is an ongoing effort, and this preliminary report presents real-time evaluation results over the past month. Our experimental results show that GPT-3 can often properly update its generation results, based on newly-retrieved documents, highlighting the importance of up-to-date information retrieval. Nonetheless, we find that GPT-3 tends to return outdated answers when retrieved documents do not provide sufficient information to find an answer. This suggests an important avenue for future research: can an open domain QA system identify such unanswerable cases and communicate with the user or even the retrieval module to modify the retrieval results? We hope that RealTime QA will spur progress in instantaneous applications of question answering and beyond.
Multimodal Knowledge Alignment with Reinforcement Learning
May 25, 2022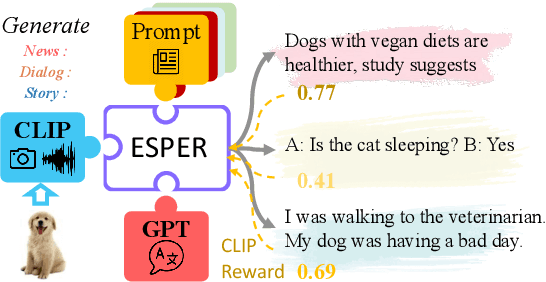
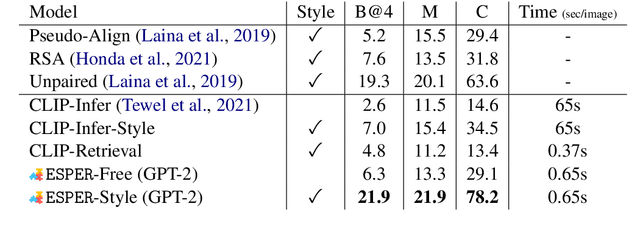
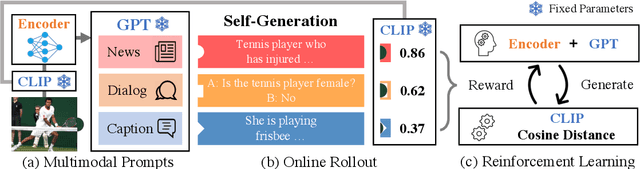
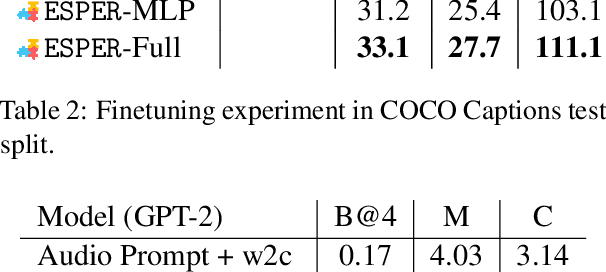
Large language models readily adapt to novel settings, even without task-specific training data. Can their zero-shot capacity be extended to multimodal inputs? In this work, we propose ESPER which extends language-only zero-shot models to unseen multimodal tasks, like image and audio captioning. Our key novelty is to use reinforcement learning to align multimodal inputs to language model generations without direct supervision: for example, in the image case our reward optimization relies only on cosine similarity derived from CLIP, and thus requires no additional explicitly paired (image, caption) data. Because the parameters of the language model are left unchanged, the model maintains its capacity for zero-shot generalization. Experiments demonstrate that ESPER outperforms baselines and prior work on a variety of zero-shot tasks; these include a new benchmark we collect+release, ESP dataset, which tasks models with generating several diversely-styled captions for each image.
Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations
May 24, 2022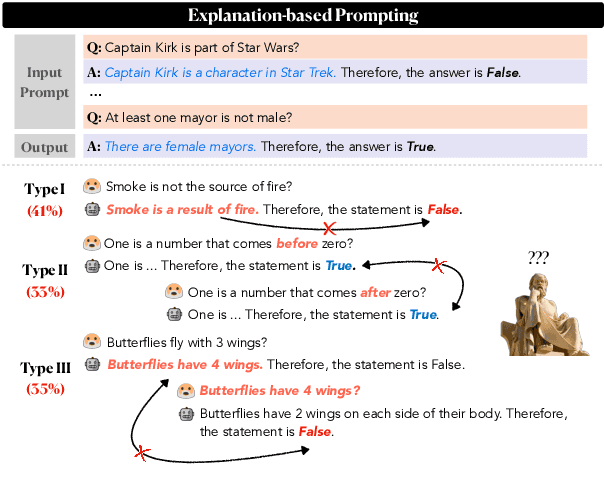
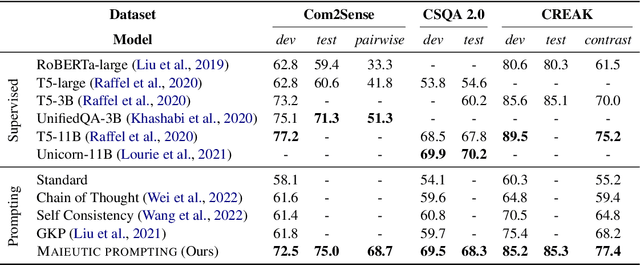
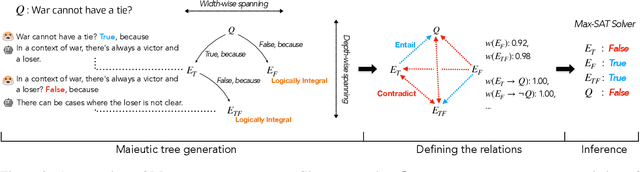

Despite their impressive capabilities, large pre-trained language models (LMs) struggle with consistent reasoning; recently, prompting LMs to generate explanations that self-guide the inference has emerged as a promising direction to amend this. However, these approaches are fundamentally bounded by the correctness of explanations, which themselves are often noisy and inconsistent. In this work, we develop Maieutic Prompting, which infers a correct answer to a question even from the noisy and inconsistent generations of LM. Maieutic Prompting induces a tree of explanations abductively (e.g. X is true, because ...) and recursively, then frames the inference as a satisfiability problem over these explanations and their logical relations. We test Maieutic Prompting for true/false QA on three challenging benchmarks that require complex commonsense reasoning. Maieutic Prompting achieves up to 20% better accuracy than state-of-the-art prompting methods, and as a fully unsupervised approach, performs competitively with supervised models. We also show that Maieutic Prompting improves robustness in inference while providing interpretable rationales.
Twist Decoding: Diverse Generators Guide Each Other
May 19, 2022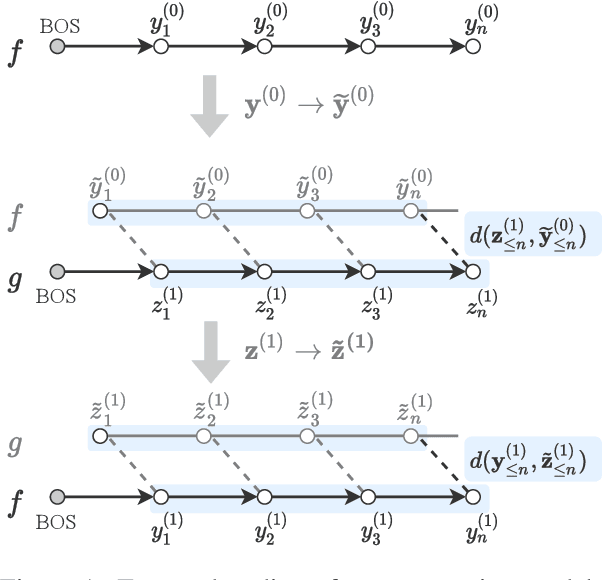
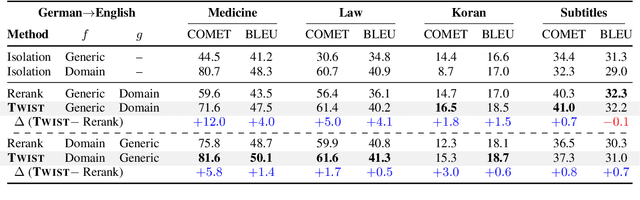

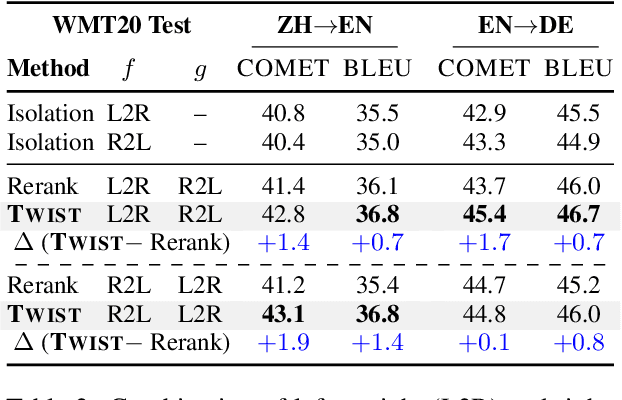
Natural language generation technology has recently seen remarkable progress with large-scale training, and many natural language applications are now built upon a wide range of generation models. Combining diverse models may lead to further progress, but conventional ensembling (e.g., shallow fusion) requires that they share vocabulary/tokenization schemes. We introduce Twist decoding, a simple and general inference algorithm that generates text while benefiting from diverse models. Our method does not assume the vocabulary, tokenization or even generation order is shared. Our extensive evaluations on machine translation and scientific paper summarization demonstrate that Twist decoding substantially outperforms each model decoded in isolation over various scenarios, including cases where domain-specific and general-purpose models are both available. Twist decoding also consistently outperforms the popular reranking heuristic where output candidates from one model is rescored by another. We hope that our work will encourage researchers and practitioners to examine generation models collectively, not just independently, and to seek out models with complementary strengths to the currently available models.
Beam Decoding with Controlled Patience
Apr 29, 2022
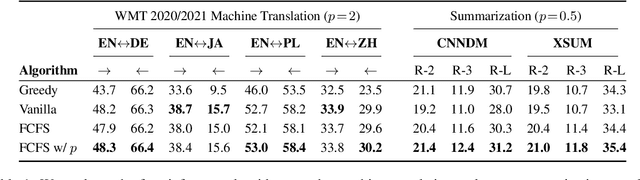


Text generation with beam search has proven successful in a wide range of applications. The commonly-used implementation of beam decoding follows a first come, first served heuristic: it keeps a set of already completed sequences over time steps and stops when the size of this set reaches the beam size. We introduce a patience factor, a simple modification to this decoding algorithm, that generalizes the stopping criterion and provides flexibility to the depth of search. Extensive empirical results demonstrate that the patience factor improves decoding performance of strong pretrained models on news text summarization and machine translation over diverse language pairs, with a negligible inference slowdown. Our approach only modifies one line of code and can be thus readily incorporated in any implementation.
CommonsenseQA 2.0: Exposing the Limits of AI through Gamification
Jan 14, 2022


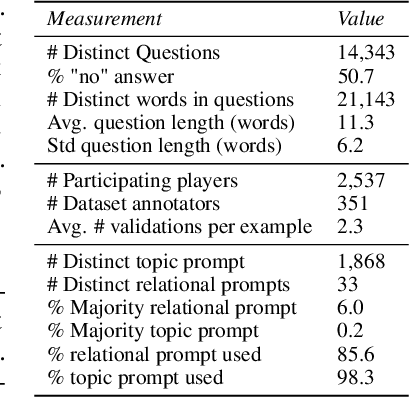
Constructing benchmarks that test the abilities of modern natural language understanding models is difficult - pre-trained language models exploit artifacts in benchmarks to achieve human parity, but still fail on adversarial examples and make errors that demonstrate a lack of common sense. In this work, we propose gamification as a framework for data construction. The goal of players in the game is to compose questions that mislead a rival AI while using specific phrases for extra points. The game environment leads to enhanced user engagement and simultaneously gives the game designer control over the collected data, allowing us to collect high-quality data at scale. Using our method we create CommonsenseQA 2.0, which includes 14,343 yes/no questions, and demonstrate its difficulty for models that are orders-of-magnitude larger than the AI used in the game itself. Our best baseline, the T5-based Unicorn with 11B parameters achieves an accuracy of 70.2%, substantially higher than GPT-3 (52.9%) in a few-shot inference setup. Both score well below human performance which is at 94.1%.
NeuroLogic A*esque Decoding: Constrained Text Generation with Lookahead Heuristics
Dec 16, 2021

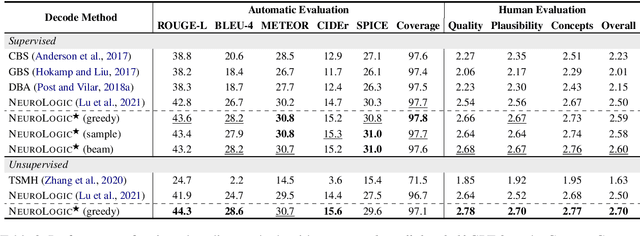
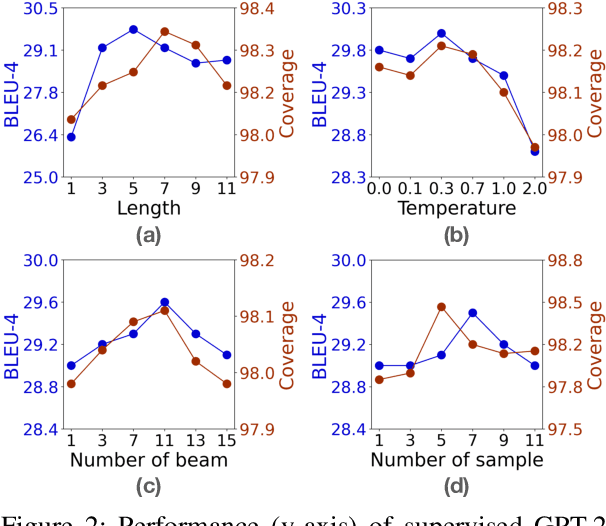
The dominant paradigm for neural text generation is left-to-right decoding from autoregressive language models. Constrained or controllable generation under complex lexical constraints, however, requires foresight to plan ahead feasible future paths. Drawing inspiration from the A* search algorithm, we propose NeuroLogic A*esque, a decoding algorithm that incorporates heuristic estimates of future cost. We develop efficient lookahead heuristics that are efficient for large-scale language models, making our method a drop-in replacement for common techniques such as beam search and top-k sampling. To enable constrained generation, we build on NeuroLogic decoding (Lu et al., 2021), combining its flexibility in incorporating logical constraints with A*esque estimates of future constraint satisfaction. Our approach outperforms competitive baselines on five generation tasks, and achieves new state-of-the-art performance on table-to-text generation, constrained machine translation, and keyword-constrained generation. The improvements are particularly notable on tasks that require complex constraint satisfaction or in few-shot or zero-shot settings. NeuroLogic A*esque illustrates the power of decoding for improving and enabling new capabilities of large-scale language models.
Bidimensional Leaderboards: Generate and Evaluate Language Hand in Hand
Dec 08, 2021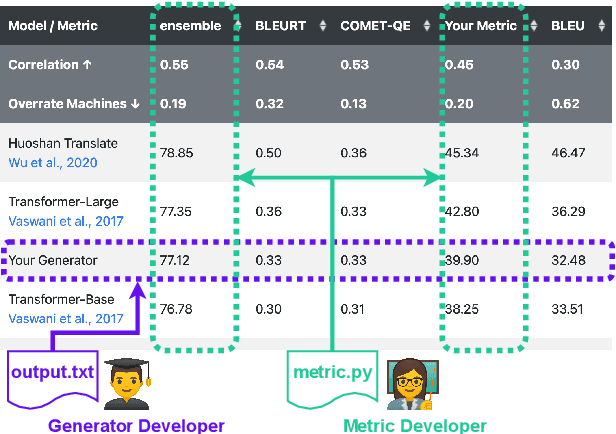
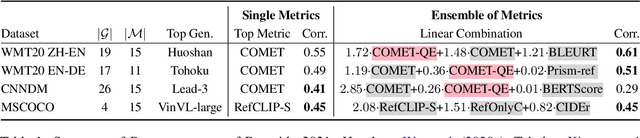
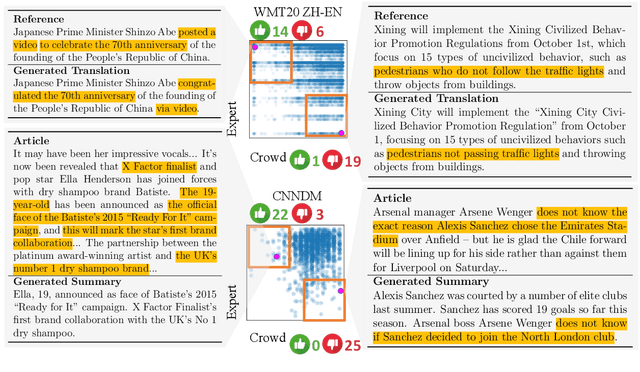

Natural language processing researchers have identified limitations of evaluation methodology for generation tasks, with new questions raised about the validity of automatic metrics and of crowdworker judgments. Meanwhile, efforts to improve generation models tend to focus on simple n-gram overlap metrics (e.g., BLEU, ROUGE). We argue that new advances on models and metrics should each more directly benefit and inform the other. We therefore propose a generalization of leaderboards, bidimensional leaderboards (Billboards), that simultaneously tracks progress in language generation tasks and metrics for their evaluation. Unlike conventional unidimensional leaderboards that sort submitted systems by predetermined metrics, a Billboard accepts both generators and evaluation metrics as competing entries. A Billboard automatically creates an ensemble metric that selects and linearly combines a few metrics based on a global analysis across generators. Further, metrics are ranked based on their correlations with human judgments. We release four Billboards for machine translation, summarization, and image captioning. We demonstrate that a linear ensemble of a few diverse metrics sometimes substantially outperforms existing metrics in isolation. Our mixed-effects model analysis shows that most automatic metrics, especially the reference-based ones, overrate machine over human generation, demonstrating the importance of updating metrics as generation models become stronger (and perhaps more similar to humans) in the future.
Transparent Human Evaluation for Image Captioning
Nov 17, 2021

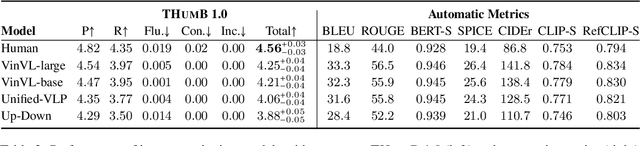
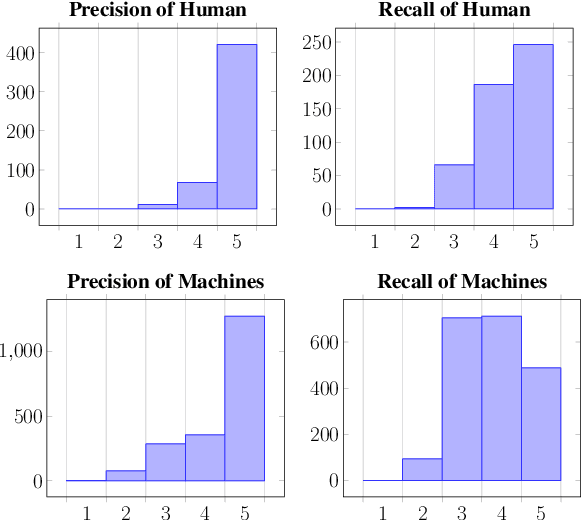
We establish a rubric-based human evaluation protocol for image captioning models. Our scoring rubrics and their definitions are carefully developed based on machine- and human-generated captions on the MSCOCO dataset. Each caption is evaluated along two main dimensions in a tradeoff (precision and recall) as well as other aspects that measure the text quality (fluency, conciseness, and inclusive language). Our evaluations demonstrate several critical problems of the current evaluation practice. Human-generated captions show substantially higher quality than machine-generated ones, especially in coverage of salient information (i.e., recall), while all automatic metrics say the opposite. Our rubric-based results reveal that CLIPScore, a recent metric that uses image features, better correlates with human judgments than conventional text-only metrics because it is more sensitive to recall. We hope that this work will promote a more transparent evaluation protocol for image captioning and its automatic metrics.