 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Lossy Compression Rates of Deep Generative Models
Aug 15, 2020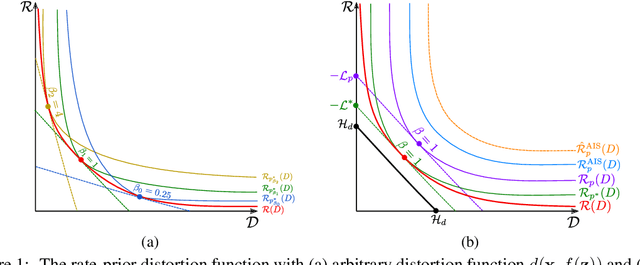
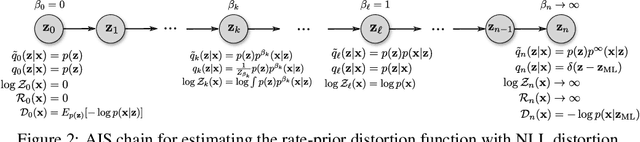
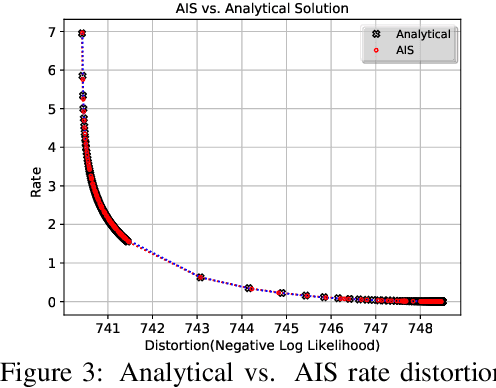
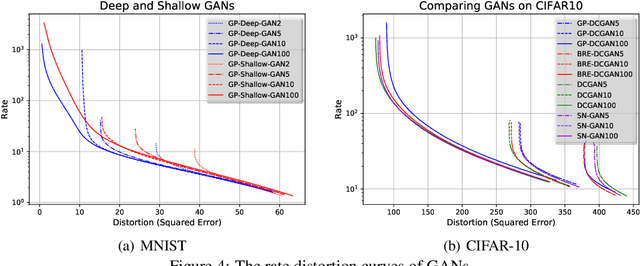
The field of deep generative modeling has succeeded in producing astonishingly realistic-seeming images and audio, but quantitative evaluation remains a challenge. Log-likelihood is an appealing metric due to its grounding in statistics and information theory, but it can be challenging to estimate for implicit generative models, and scalar-valued metrics give an incomplete picture of a model's quality. In this work, we propose to use rate distortion (RD) curves to evaluate and compare deep generative models. While estimating RD curves is seemingly even more computationally demanding than log-likelihood estimation, we show that we can approximate the entire RD curve using nearly the same computations as were previously used to achieve a single log-likelihood estimate. We evaluate lossy compression rates of VAEs, GANs, and adversarial autoencoders (AAEs) on the MNIST and CIFAR10 datasets. Measuring the entire RD curve gives a more complete picture than scalar-valued metrics, and we arrive at a number of insights not obtainable from log-likelihoods alone.
Regularized linear autoencoders recover the principal components, eventually
Jul 13, 2020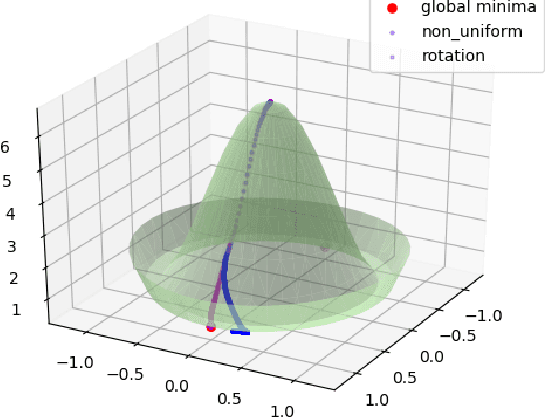

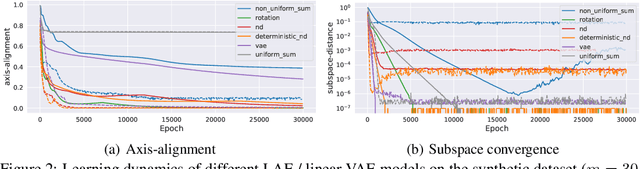

Our understanding of learning input-output relationships with neural nets has improved rapidly in recent years, but little is known about the convergence of the underlying representations, even in the simple case of linear autoencoders (LAEs). We show that when trained with proper regularization, LAEs can directly learn the optimal representation -- ordered, axis-aligned principal components. We analyze two such regularization schemes: non-uniform $\ell_2$ regularization and a deterministic variant of nested dropout [Rippel et al, ICML' 2014]. Though both regularization schemes converge to the optimal representation, we show that this convergence is slow due to ill-conditioning that worsens with increasing latent dimension. We show that the inefficiency of learning the optimal representation is not inevitable -- we present a simple modification to the gradient descent update that greatly speeds up convergence empirically.
The Scattering Compositional Learner: Discovering Objects, Attributes, Relationships in Analogical Reasoning
Jul 08, 2020
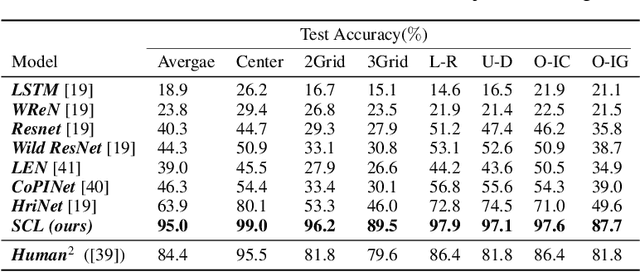
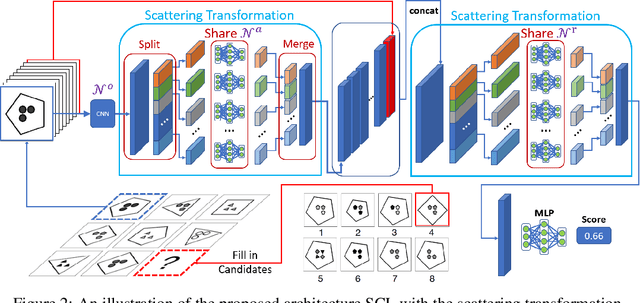
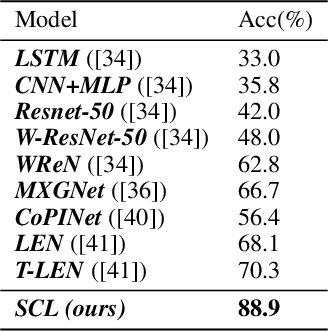
In this work, we focus on an analogical reasoning task that contains rich compositional structures, Raven's Progressive Matrices (RPM). To discover compositional structures of the data, we propose the Scattering Compositional Learner (SCL), an architecture that composes neural networks in a sequence. Our SCL achieves state-of-the-art performance on two RPM datasets, with a 48.7% relative improvement on Balanced-RAVEN and 26.4% on PGM over the previous state-of-the-art. We additionally show that our model discovers compositional representations of objects' attributes (e.g., shape color, size), and their relationships (e.g., progression, union). We also find that the compositional representation makes the SCL significantly more robust to test-time domain shifts and greatly improves zero-shot generalization to previously unseen analogies.
Learning Branching Heuristics for Propositional Model Counting
Jul 07, 2020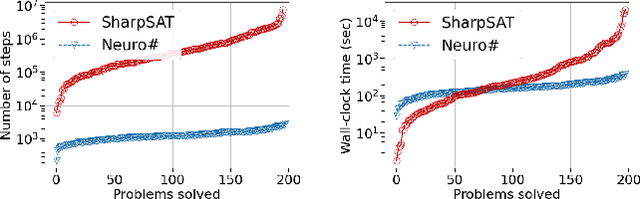
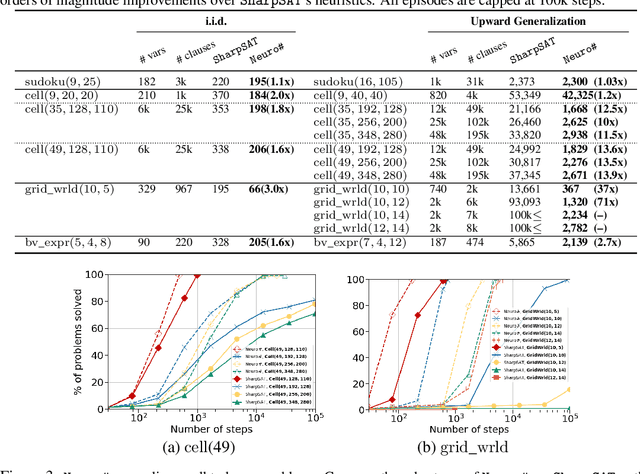
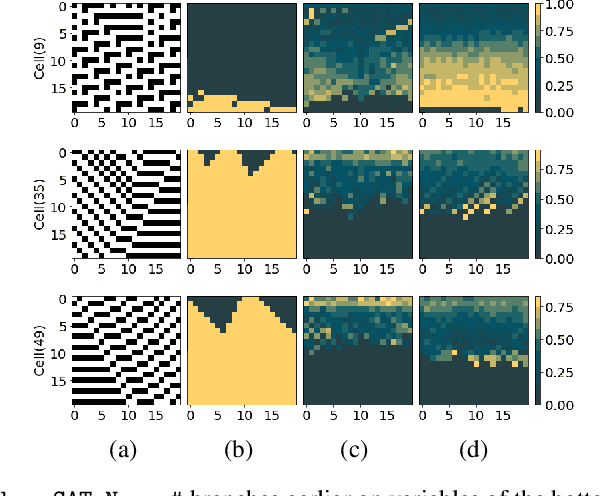
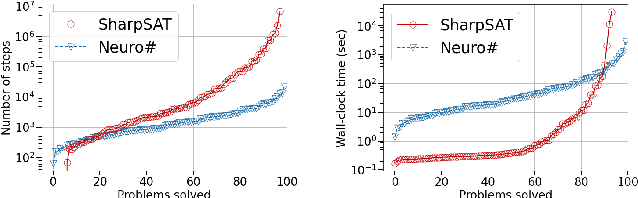
Propositional model counting or #SAT is the problem of computing the number of satisfying assignments of a Boolean formula and many discrete probabilistic inference problems can be translated into a model counting problem to be solved by #SAT solvers. Generic ``exact'' #SAT solvers, however, are often not scalable to industrial-level instances. In this paper, we present Neuro#, an approach for learning branching heuristics for exact #SAT solvers via evolution strategies (ES) to reduce the number of branching steps the solver takes to solve an instance. We experimentally show that our approach not only reduces the step count on similarly distributed held-out instances but it also generalizes to much larger instances from the same problem family. The gap between the learned and the vanilla solver on larger instances is sometimes so wide that the learned solver can even overcome the run time overhead of querying the model and beat the vanilla in wall-clock time by orders of magnitude.
INT: An Inequality Benchmark for Evaluating Generalization in Theorem Proving
Jul 06, 2020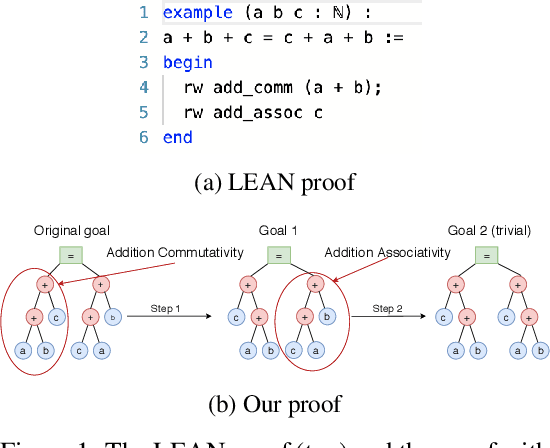
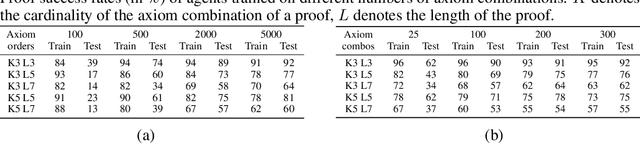
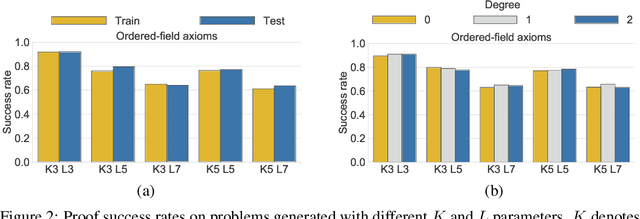
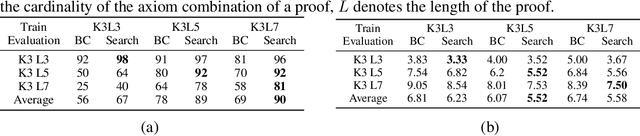
In learning-assisted theorem proving, one of the most critical challenges is to generalize to theorems unlike those seen at training time. In this paper, we introduce INT, an INequality Theorem proving benchmark, specifically designed to test agents' generalization ability. INT is based on a procedure for generating theorems and proofs; this procedure's knobs allow us to measure 6 different types of generalization, each reflecting a distinct challenge characteristic to automated theorem proving. In addition, unlike prior benchmarks for learning-assisted theorem proving, INT provides a lightweight and user-friendly theorem proving environment with fast simulations, conducive to performing learning-based and search-based research. We introduce learning-based baselines and evaluate them across 6 dimensions of generalization with the benchmark. We then evaluate the same agents augmented with Monte Carlo Tree Search (MCTS) at test time, and show that MCTS can help to prove new theorems.
When Does Preconditioning Help or Hurt Generalization?
Jul 02, 2020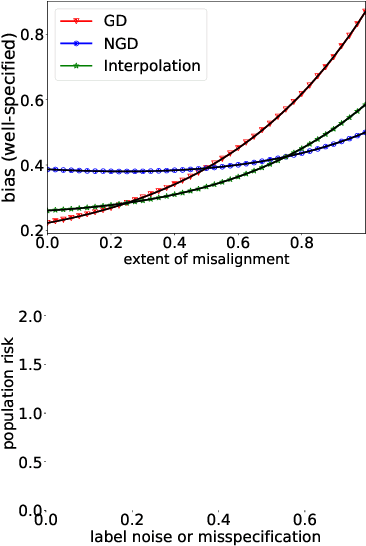
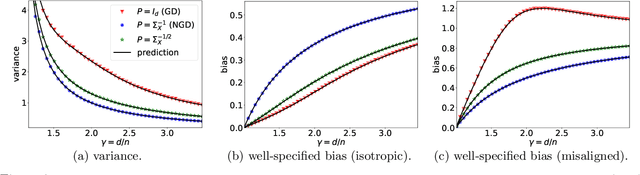
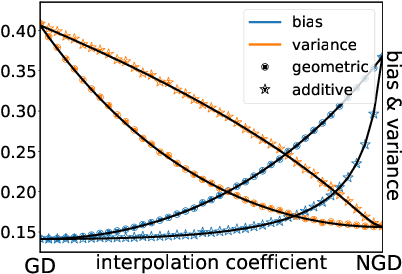
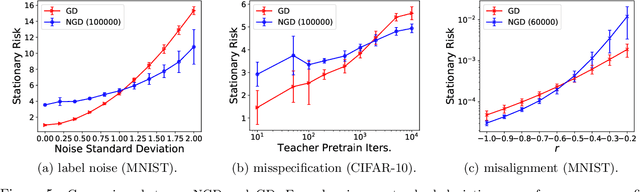
While second order optimizers such as natural gradient descent (NGD) often speed up optimization, their effect on generalization remains controversial. For instance, it has been pointed out that gradient descent (GD), in contrast to many preconditioned updates, converges to small Euclidean norm solutions in overparameterized models, leading to favorable generalization properties. This work presents a more nuanced view on the comparison of generalization between first- and second-order methods. We provide an asymptotic bias-variance decomposition of the generalization error of overparameterized ridgeless regression under a general class of preconditioner $\boldsymbol{P}$, and consider the inverse population Fisher information matrix (used in NGD) as a particular example. We determine the optimal $\boldsymbol{P}$ for both the bias and variance, and find that the relative generalization performance of different optimizers depends on the label noise and the "shape" of the signal (true parameters): when the labels are noisy, the model is misspecified, or the signal is misaligned with the features, NGD can achieve lower risk; conversely, GD generalizes better than NGD under clean labels, a well-specified model, or aligned signal. Based on this analysis, we discuss several approaches to manage the bias-variance tradeoff, and the potential benefit of interpolating between GD and NGD. We then extend our analysis to regression in the reproducing kernel Hilbert space and demonstrate that preconditioned GD can decrease the population risk faster than GD. Lastly, we empirically compare the generalization performance of first- and second-order optimizers in neural network experiments, and observe robust trends matching our theoretical analysis.
Understanding and mitigating exploding inverses in invertible neural networks
Jun 16, 2020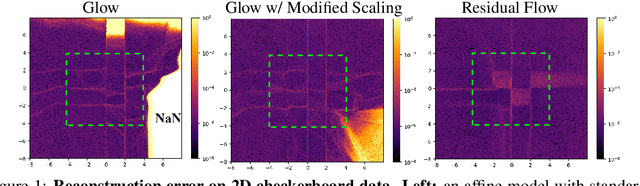
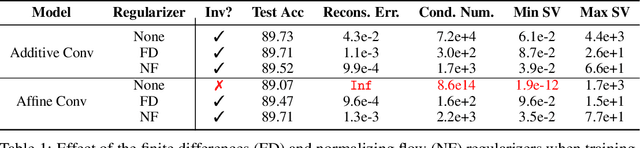

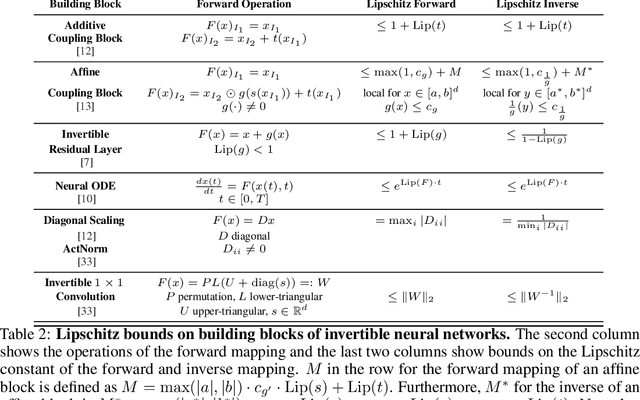
Invertible neural networks (INNs) have been used to design generative models, implement memory-saving gradient computation, and solve inverse problems. In this work, we show that commonly-used INN architectures suffer from exploding inverses and are thus prone to becoming numerically non-invertible. Across a wide range of INN use-cases, we reveal failures including the non-applicability of the change-of-variables formula on in- and out-of-distribution (OOD) data, incorrect gradients for memory-saving backprop, and the inability to sample from normalizing flow models. We further derive bi-Lipschitz properties of atomic building blocks of common architectures. These insights into the stability of INNs then provide ways forward to remedy these failures. For tasks where local invertibility is sufficient, like memory-saving backprop, we propose a flexible and efficient regularizer. For problems where global invertibility is necessary, such as applying normalizing flows on OOD data, we show the importance of designing stable INN building blocks.
Picking Winning Tickets Before Training by Preserving Gradient Flow
Feb 18, 2020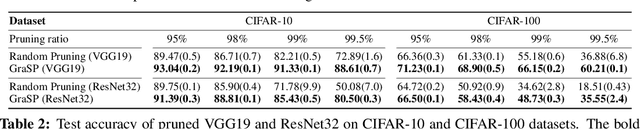
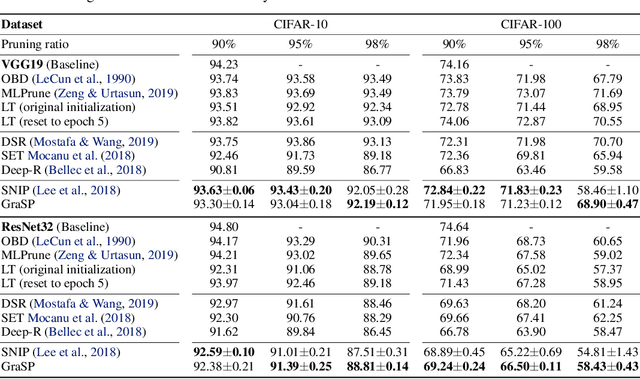
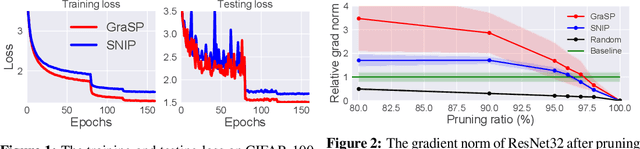
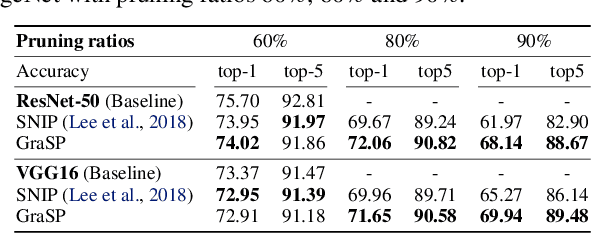
Overparameterization has been shown to benefit both the optimization and generalization of neural networks, but large networks are resource hungry at both training and test time. Network pruning can reduce test-time resource requirements, but is typically applied to trained networks and therefore cannot avoid the expensive training process. We aim to prune networks at initialization, thereby saving resources at training time as well. Specifically, we argue that efficient training requires preserving the gradient flow through the network. This leads to a simple but effective pruning criterion we term Gradient Signal Preservation (GraSP). We empirically investigate the effectiveness of the proposed method with extensive experiments on CIFAR-10, CIFAR-100, Tiny-ImageNet and ImageNet, using VGGNet and ResNet architectures. Our method can prune 80% of the weights of a VGG-16 network on ImageNet at initialization, with only a 1.6% drop in top-1 accuracy. Moreover, our method achieves significantly better performance than the baseline at extreme sparsity levels.
* Accepted at ICLR 2020
Preventing Gradient Attenuation in Lipschitz Constrained Convolutional Networks
Nov 09, 2019
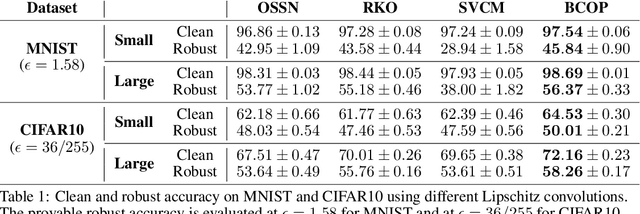
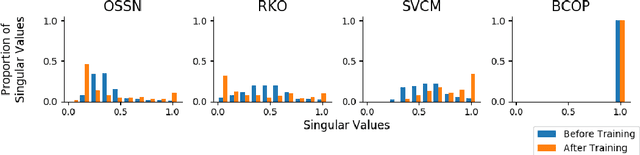

Lipschitz constraints under L2 norm on deep neural networks are useful for provable adversarial robustness bounds, stable training, and Wasserstein distance estimation. While heuristic approaches such as the gradient penalty have seen much practical success, it is challenging to achieve similar practical performance while provably enforcing a Lipschitz constraint. In principle, one can design Lipschitz constrained architectures using the composition property of Lipschitz functions, but Anil et al. recently identified a key obstacle to this approach: gradient norm attenuation. They showed how to circumvent this problem in the case of fully connected networks by designing each layer to be gradient norm preserving. We extend their approach to train scalable, expressive, provably Lipschitz convolutional networks. In particular, we present the Block Convolution Orthogonal Parameterization (BCOP), an expressive parameterization of orthogonal convolution operations. We show that even though the space of orthogonal convolutions is disconnected, the largest connected component of BCOP with 2n channels can represent arbitrary BCOP convolutions over n channels. Our BCOP parameterization allows us to train large convolutional networks with provable Lipschitz bounds. Empirically, we find that it is competitive with existing approaches to provable adversarial robustness and Wasserstein distance estimation.
Don't Blame the ELBO! A Linear VAE Perspective on Posterior Collapse
Nov 06, 2019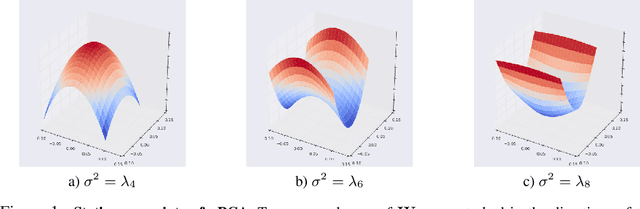
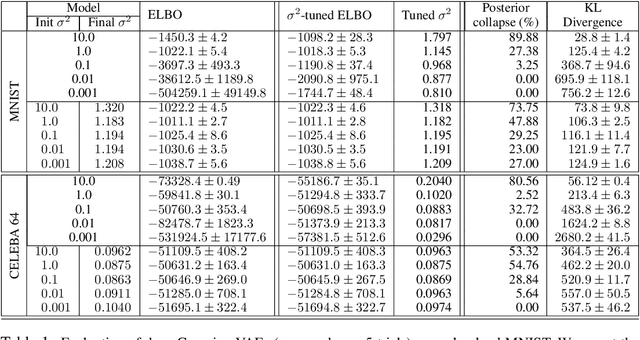
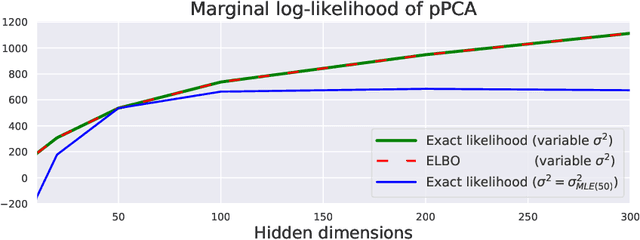
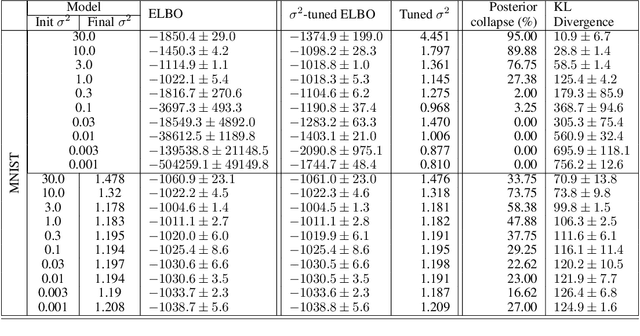
Posterior collapse in Variational Autoencoders (VAEs) arises when the variational posterior distribution closely matches the prior for a subset of latent variables. This paper presents a simple and intuitive explanation for posterior collapse through the analysis of linear VAEs and their direct correspondence with Probabilistic PCA (pPCA). We explain how posterior collapse may occur in pPCA due to local maxima in the log marginal likelihood. Unexpectedly, we prove that the ELBO objective for the linear VAE does not introduce additional spurious local maxima relative to log marginal likelihood. We show further that training a linear VAE with exact variational inference recovers an identifiable global maximum corresponding to the principal component directions. Empirically, we find that our linear analysis is predictive even for high-capacity, non-linear VAEs and helps explain the relationship between the observation noise, local maxima, and posterior collapse in deep Gaussian VAEs.