 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePREM: Privately Answering Statistical Queries with Relative Error
Feb 20, 2025We introduce $\mathsf{PREM}$ (Private Relative Error Multiplicative weight update), a new framework for generating synthetic data that achieves a relative error guarantee for statistical queries under $(\varepsilon, \delta)$ differential privacy (DP). Namely, for a domain ${\cal X}$, a family ${\cal F}$ of queries $f : {\cal X} \to \{0, 1\}$, and $\zeta > 0$, our framework yields a mechanism that on input dataset $D \in {\cal X}^n$ outputs a synthetic dataset $\widehat{D} \in {\cal X}^n$ such that all statistical queries in ${\cal F}$ on $D$, namely $\sum_{x \in D} f(x)$ for $f \in {\cal F}$, are within a $1 \pm \zeta$ multiplicative factor of the corresponding value on $\widehat{D}$ up to an additive error that is polynomial in $\log |{\cal F}|$, $\log |{\cal X}|$, $\log n$, $\log(1/\delta)$, $1/\varepsilon$, and $1/\zeta$. In contrast, any $(\varepsilon, \delta)$-DP mechanism is known to require worst-case additive error that is polynomial in at least one of $n, |{\cal F}|$, or $|{\cal X}|$. We complement our algorithm with nearly matching lower bounds.
Regularized linear autoencoders recover the principal components, eventually
Jul 13, 2020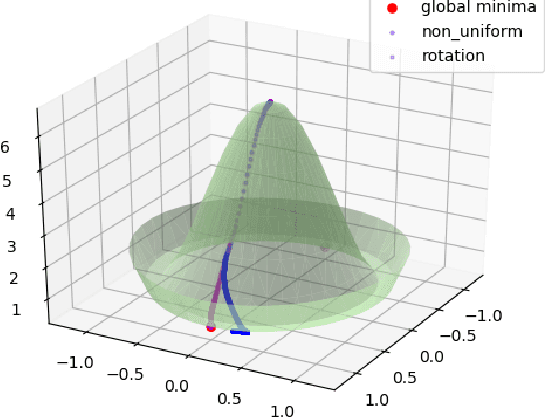

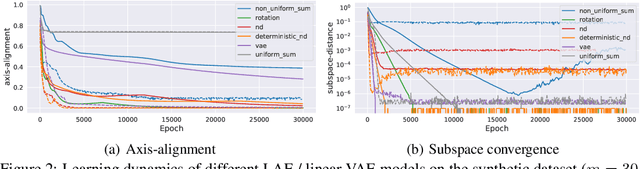

Our understanding of learning input-output relationships with neural nets has improved rapidly in recent years, but little is known about the convergence of the underlying representations, even in the simple case of linear autoencoders (LAEs). We show that when trained with proper regularization, LAEs can directly learn the optimal representation -- ordered, axis-aligned principal components. We analyze two such regularization schemes: non-uniform $\ell_2$ regularization and a deterministic variant of nested dropout [Rippel et al, ICML' 2014]. Though both regularization schemes converge to the optimal representation, we show that this convergence is slow due to ill-conditioning that worsens with increasing latent dimension. We show that the inefficiency of learning the optimal representation is not inevitable -- we present a simple modification to the gradient descent update that greatly speeds up convergence empirically.
Faster Graph Embeddings via Coarsening
Jul 06, 2020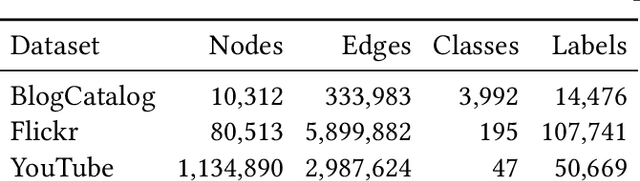
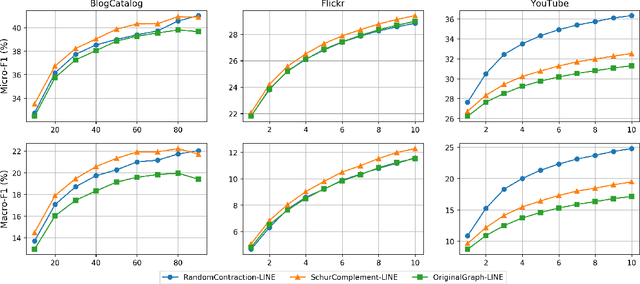
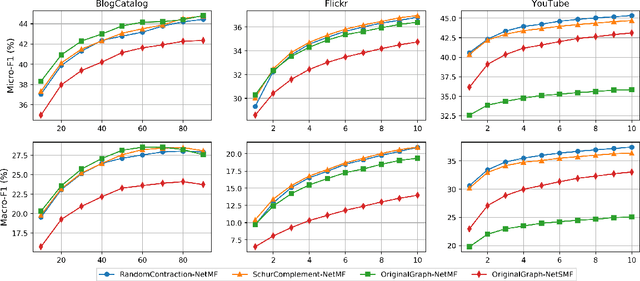
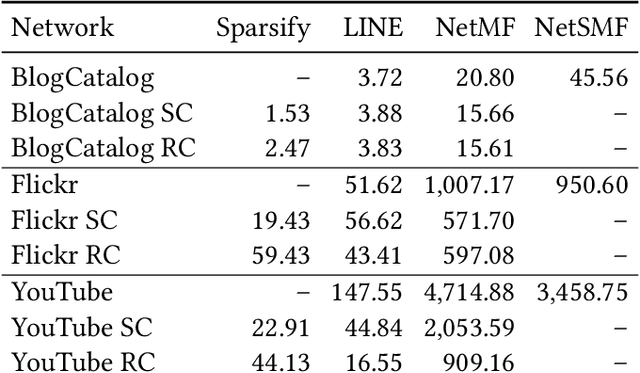
Graph embeddings are a ubiquitous tool for machine learning tasks, such as node classification and link prediction, on graph-structured data. However, computing the embeddings for large-scale graphs is prohibitively inefficient even if we are interested only in a small subset of relevant vertices. To address this, we present an efficient graph coarsening approach, based on Schur complements, for computing the embedding of the relevant vertices. We prove that these embeddings are preserved exactly by the Schur complement graph that is obtained via Gaussian elimination on the non-relevant vertices. As computing Schur complements is expensive, we give a nearly-linear time algorithm that generates a coarsened graph on the relevant vertices that provably matches the Schur complement in expectation in each iteration. Our experiments involving prediction tasks on graphs demonstrate that computing embeddings on the coarsened graph, rather than the entire graph, leads to significant time savings without sacrificing accuracy.
* 18 pages, 2 figures
A Provably Convergent and Practical Algorithm for Min-max Optimization with Applications to GANs
Jun 23, 2020



We present a new algorithm for optimizing min-max loss functions that arise in training GANs. We prove that our algorithm converges to an equilibrium point in time polynomial in the dimension, and smoothness parameters of the loss function. The point our algorithm converges to is stable when the maximizing player can respond using any sequence of steps which increase the loss at each step, and the minimizing player is empowered to simulate the maximizing player's response for arbitrarily many steps but is restricted to move according to updates sampled from a stochastic gradient oracle. We apply our algorithm to train GANs on Gaussian mixtures, MNIST and CIFAR-10. We observe that our algorithm trains stably and avoids mode collapse, while achieving a training time per iteration and memory requirement similar to gradient descent-ascent.
Fast, Provably convergent IRLS Algorithm for p-norm Linear Regression
Jul 16, 2019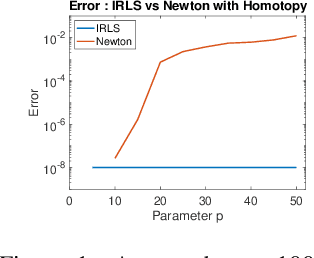
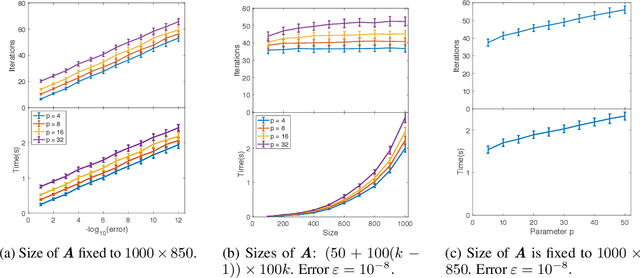
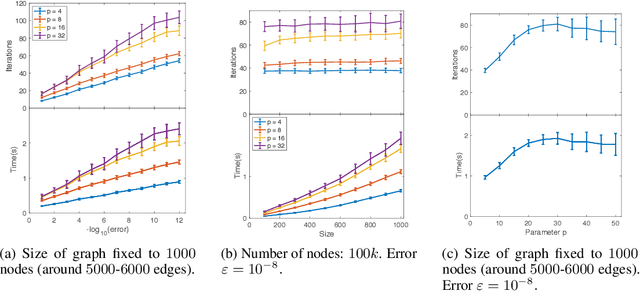

Linear regression in $\ell_p$-norm is a canonical optimization problem that arises in several applications, including sparse recovery, semi-supervised learning, and signal processing. Generic convex optimization algorithms for solving $\ell_p$-regression are slow in practice. Iteratively Reweighted Least Squares (IRLS) is an easy to implement family of algorithms for solving these problems that has been studied for over 50 years. However, these algorithms often diverge for p > 3, and since the work of Osborne (1985), it has been an open problem whether there is an IRLS algorithm that is guaranteed to converge rapidly for p > 3. We propose p-IRLS, the first IRLS algorithm that provably converges geometrically for any $p \in [2,\infty).$ Our algorithm is simple to implement and is guaranteed to find a $(1+\varepsilon)$-approximate solution in $O(p^{3.5} m^{\frac{p-2}{2(p-1)}} \log \frac{m}{\varepsilon}) \le O_p(\sqrt{m} \log \frac{m}{\varepsilon} )$ iterations. Our experiments demonstrate that it performs even better than our theoretical bounds, beats the standard Matlab/CVX implementation for solving these problems by 10--50x, and is the fastest among available implementations in the high-accuracy regime.
Which Algorithmic Choices Matter at Which Batch Sizes? Insights From a Noisy Quadratic Model
Jul 09, 2019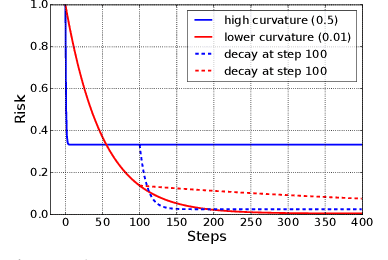
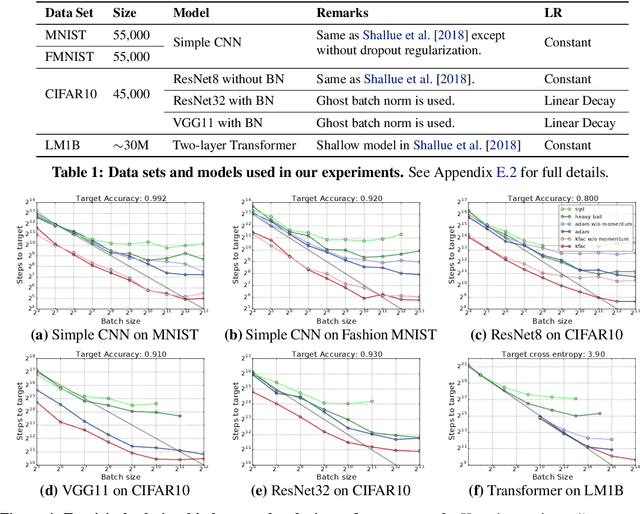
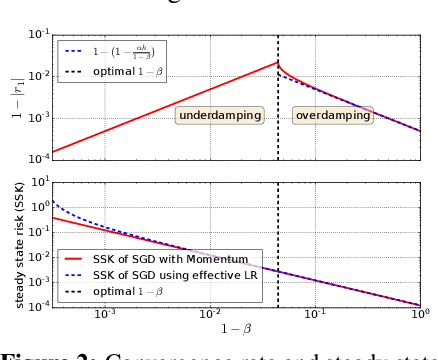
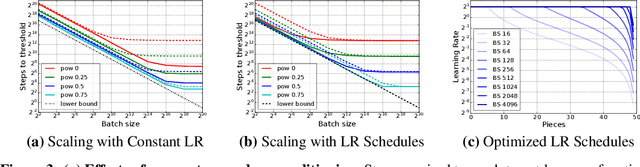
Increasing the batch size is a popular way to speed up neural network training, but beyond some critical batch size, larger batch sizes yield diminishing returns. In this work, we study how the critical batch size changes based on properties of the optimization algorithm, including acceleration and preconditioning, through two different lenses: large scale experiments, and analysis of a simple noisy quadratic model (NQM). We experimentally demonstrate that optimization algorithms that employ preconditioning, specifically Adam and K-FAC, result in much larger critical batch sizes than stochastic gradient descent with momentum. We also demonstrate that the NQM captures many of the essential features of real neural network training, despite being drastically simpler to work with. The NQM predicts our results with preconditioned optimizers, previous results with accelerated gradient descent, and other results around optimal learning rates and large batch training, making it a useful tool to generate testable predictions about neural network optimization.
Iterative Refinement for $\ell_p$-norm Regression
Jan 21, 2019We give improved algorithms for the $\ell_{p}$-regression problem, $\min_{x} \|x\|_{p}$ such that $A x=b,$ for all $p \in (1,2) \cup (2,\infty).$ Our algorithms obtain a high accuracy solution in $\tilde{O}_{p}(m^{\frac{|p-2|}{2p + |p-2|}}) \le \tilde{O}_{p}(m^{\frac{1}{3}})$ iterations, where each iteration requires solving an $m \times m$ linear system, $m$ being the dimension of the ambient space. By maintaining an approximate inverse of the linear systems that we solve in each iteration, we give algorithms for solving $\ell_{p}$-regression to $1 / \text{poly}(n)$ accuracy that run in time $\tilde{O}_p(m^{\max\{\omega, 7/3\}}),$ where $\omega$ is the matrix multiplication constant. For the current best value of $\omega > 2.37$, we can thus solve $\ell_{p}$ regression as fast as $\ell_{2}$ regression, for all constant $p$ bounded away from $1.$ Our algorithms can be combined with fast graph Laplacian linear equation solvers to give minimum $\ell_{p}$-norm flow / voltage solutions to $1 / \text{poly}(n)$ accuracy on an undirected graph with $m$ edges in $\tilde{O}_{p}(m^{1 + \frac{|p-2|}{2p + |p-2|}}) \le \tilde{O}_{p}(m^{\frac{4}{3}})$ time. For sparse graphs and for matrices with similar dimensions, our iteration counts and running times improve on the $p$-norm regression algorithm by [Bubeck-Cohen-Lee-Li STOC`18] and general-purpose convex optimization algorithms. At the core of our algorithms is an iterative refinement scheme for $\ell_{p}$-norms, using the smoothed $\ell_{p}$-norms introduced in the work of Bubeck et al. Given an initial solution, we construct a problem that seeks to minimize a quadratically-smoothed $\ell_{p}$ norm over a subspace, such that a crude solution to this problem allows us to improve the initial solution by a constant factor, leading to algorithms with fast convergence.
Convergence Results for Neural Networks via Electrodynamics
Nov 21, 2017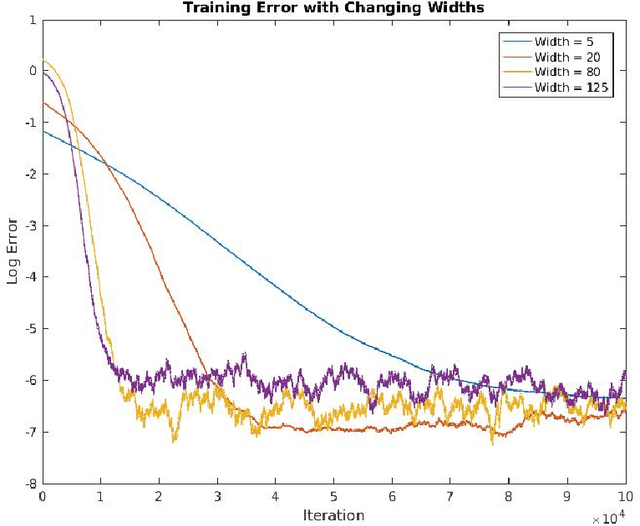


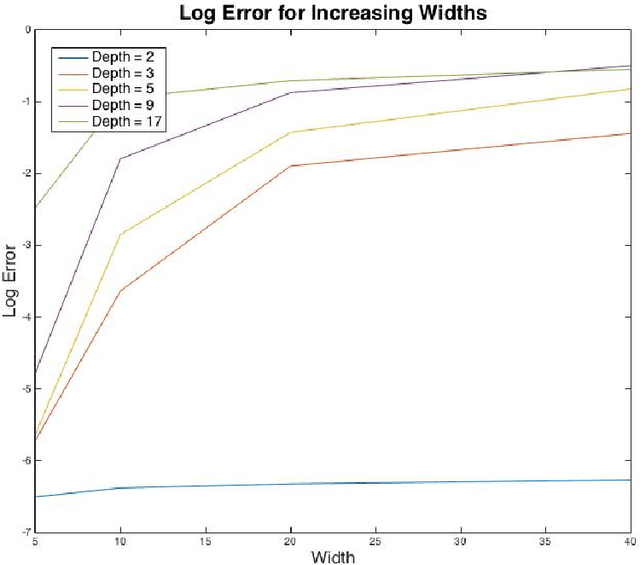
We study whether a depth two neural network can learn another depth two network using gradient descent. Assuming a linear output node, we show that the question of whether gradient descent converges to the target function is equivalent to the following question in electrodynamics: Given $k$ fixed protons in $\mathbb{R}^d,$ and $k$ electrons, each moving due to the attractive force from the protons and repulsive force from the remaining electrons, whether at equilibrium all the electrons will be matched up with the protons, up to a permutation. Under the standard electrical force, this follows from the classic Earnshaw's theorem. In our setting, the force is determined by the activation function and the input distribution. Building on this equivalence, we prove the existence of an activation function such that gradient descent learns at least one of the hidden nodes in the target network. Iterating, we show that gradient descent can be used to learn the entire network one node at a time.
Fast, Provable Algorithms for Isotonic Regression in all $\ell_{p}$-norms
Nov 11, 2015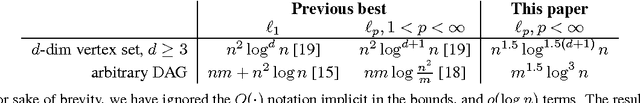
Given a directed acyclic graph $G,$ and a set of values $y$ on the vertices, the Isotonic Regression of $y$ is a vector $x$ that respects the partial order described by $G,$ and minimizes $||x-y||,$ for a specified norm. This paper gives improved algorithms for computing the Isotonic Regression for all weighted $\ell_{p}$-norms with rigorous performance guarantees. Our algorithms are quite practical, and their variants can be implemented to run fast in practice.
Algorithms for Lipschitz Learning on Graphs
Jun 30, 2015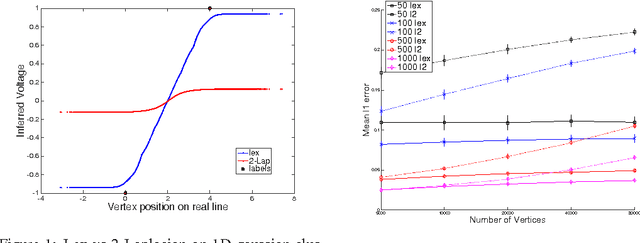
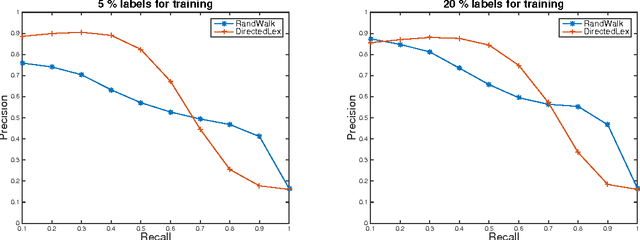
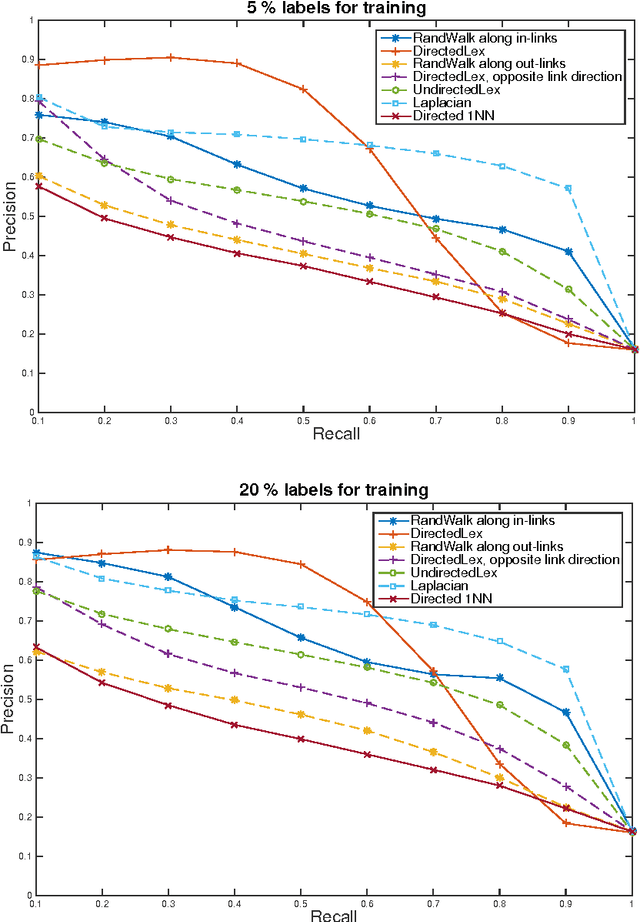
We develop fast algorithms for solving regression problems on graphs where one is given the value of a function at some vertices, and must find its smoothest possible extension to all vertices. The extension we compute is the absolutely minimal Lipschitz extension, and is the limit for large $p$ of $p$-Laplacian regularization. We present an algorithm that computes a minimal Lipschitz extension in expected linear time, and an algorithm that computes an absolutely minimal Lipschitz extension in expected time $\widetilde{O} (m n)$. The latter algorithm has variants that seem to run much faster in practice. These extensions are particularly amenable to regularization: we can perform $l_{0}$-regularization on the given values in polynomial time and $l_{1}$-regularization on the initial function values and on graph edge weights in time $\widetilde{O} (m^{3/2})$.