 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortized Proximal Optimization
Feb 28, 2022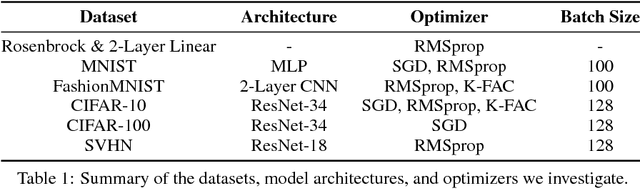
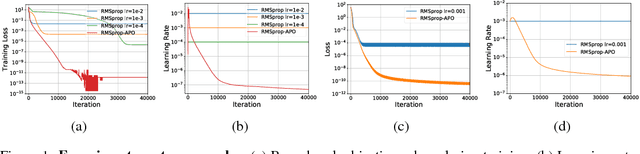
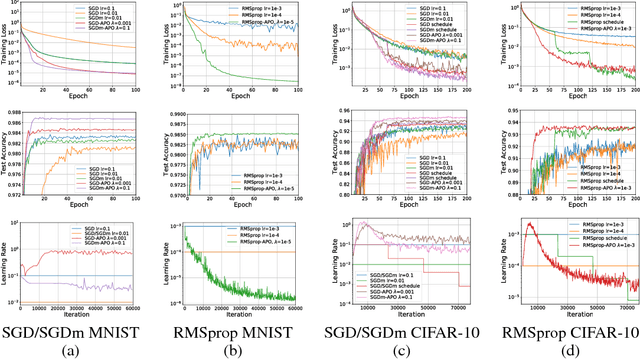

We propose a framework for online meta-optimization of parameters that govern optimization, called Amortized Proximal Optimization (APO). We first interpret various existing neural network optimizers as approximate stochastic proximal point methods which trade off the current-batch loss with proximity terms in both function space and weight space. The idea behind APO is to amortize the minimization of the proximal point objective by meta-learning the parameters of an update rule. We show how APO can be used to adapt a learning rate or a structured preconditioning matrix. Under appropriate assumptions, APO can recover existing optimizers such as natural gradient descent and KFAC. It enjoys low computational overhead and avoids expensive and numerically sensitive operations required by some second-order optimizers, such as matrix inverses. We empirically test APO for online adaptation of learning rates and structured preconditioning matrices for regression, image reconstruction, image classification, and natural language translation tasks. Empirically, the learning rate schedules found by APO generally outperform optimal fixed learning rates and are competitive with manually tuned decay schedules. Using APO to adapt a structured preconditioning matrix generally results in optimization performance competitive with second-order methods. Moreover, the absence of matrix inversion provides numerical stability, making it effective for low precision training.
Learning to Give Checkable Answers with Prover-Verifier Games
Aug 27, 2021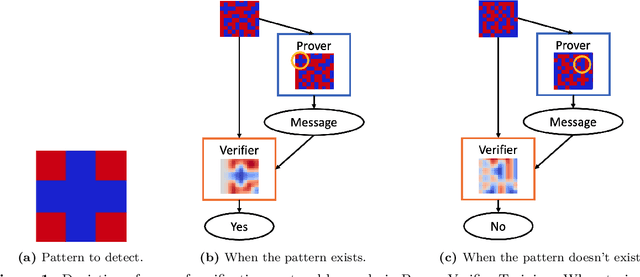
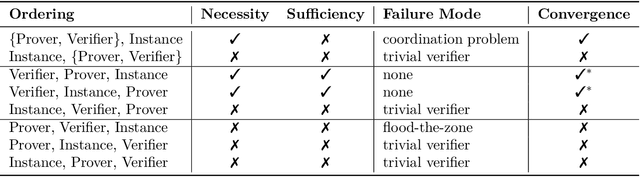

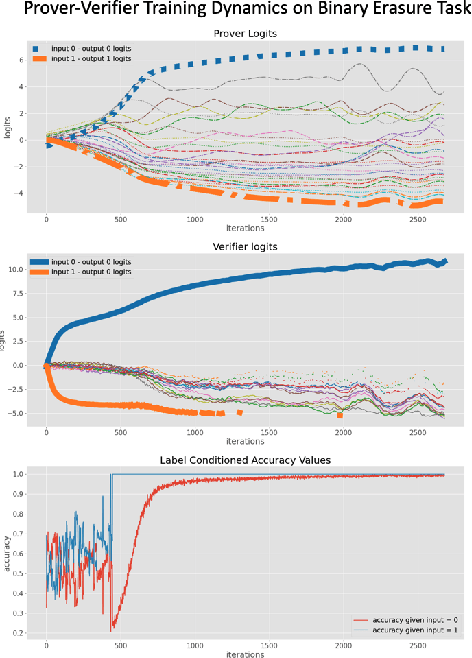
Our ability to know when to trust the decisions made by machine learning systems has not kept up with the staggering improvements in their performance, limiting their applicability in high-stakes domains. We introduce Prover-Verifier Games (PVGs), a game-theoretic framework to encourage learning agents to solve decision problems in a verifiable manner. The PVG consists of two learners with competing objectives: a trusted verifier network tries to choose the correct answer, and a more powerful but untrusted prover network attempts to persuade the verifier of a particular answer, regardless of its correctness. The goal is for a reliable justification protocol to emerge from this game. We analyze variants of the framework, including simultaneous and sequential games, and narrow the space down to a subset of games which provably have the desired equilibria. We develop instantiations of the PVG for two algorithmic tasks, and show that in practice, the verifier learns a robust decision rule that is able to receive useful and reliable information from an untrusted prover. Importantly, the protocol still works even when the verifier is frozen and the prover's messages are directly optimized to convince the verifier.
Differentiable Annealed Importance Sampling and the Perils of Gradient Noise
Jul 21, 2021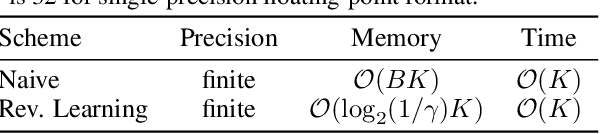
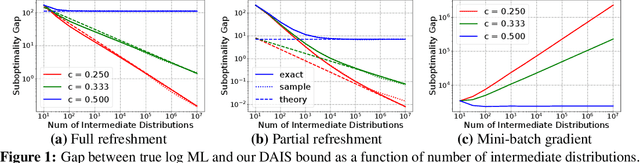

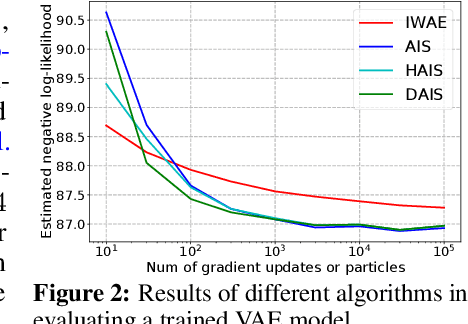
Annealed importance sampling (AIS) and related algorithms are highly effective tools for marginal likelihood estimation, but are not fully differentiable due to the use of Metropolis-Hastings (MH) correction steps. Differentiability is a desirable property as it would admit the possibility of optimizing marginal likelihood as an objective using gradient-based methods. To this end, we propose a differentiable AIS algorithm by abandoning MH steps, which further unlocks mini-batch computation. We provide a detailed convergence analysis for Bayesian linear regression which goes beyond previous analyses by explicitly accounting for non-perfect transitions. Using this analysis, we prove that our algorithm is consistent in the full-batch setting and provide a sublinear convergence rate. However, we show that the algorithm is inconsistent when mini-batch gradients are used due to a fundamental incompatibility between the goals of last-iterate convergence to the posterior and elimination of the pathwise stochastic error. This result is in stark contrast to our experience with stochastic optimization and stochastic gradient Langevin dynamics, where the effects of gradient noise can be washed out by taking more steps of a smaller size. Our negative result relies crucially on our explicit consideration of convergence to the stationary distribution, and it helps explain the difficulty of developing practically effective AIS-like algorithms that exploit mini-batch gradients.
Scalable Variational Gaussian Processes via Harmonic Kernel Decomposition
Jun 10, 2021
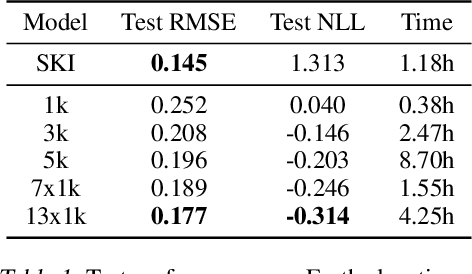
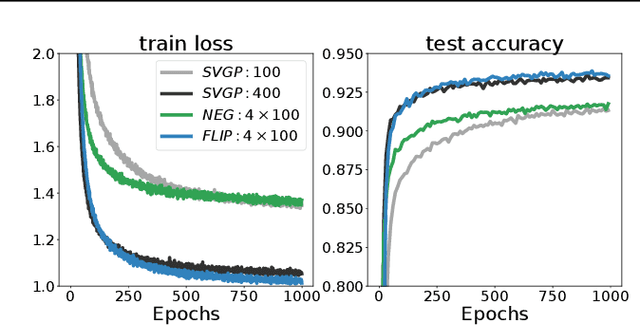
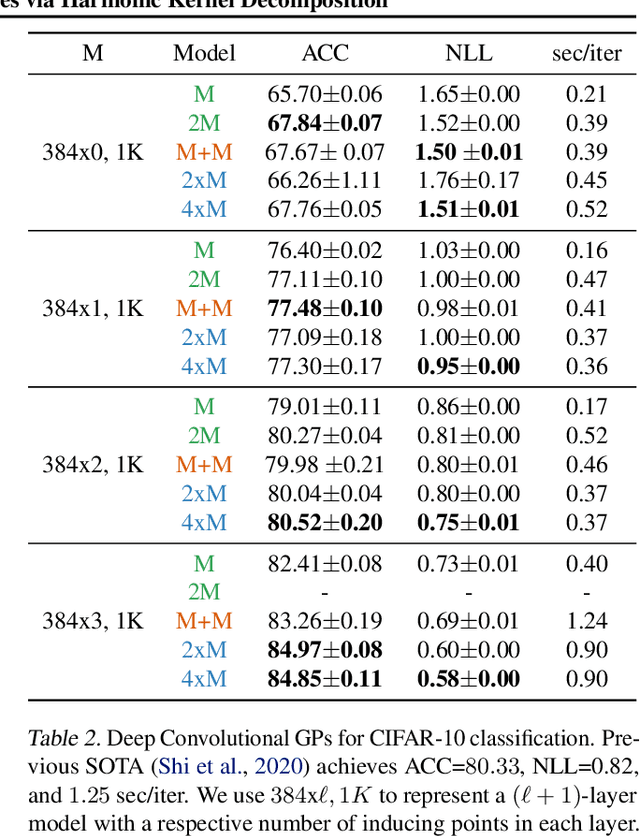
We introduce a new scalable variational Gaussian process approximation which provides a high fidelity approximation while retaining general applicability. We propose the harmonic kernel decomposition (HKD), which uses Fourier series to decompose a kernel as a sum of orthogonal kernels. Our variational approximation exploits this orthogonality to enable a large number of inducing points at a low computational cost. We demonstrate that, on a range of regression and classification problems, our approach can exploit input space symmetries such as translations and reflections, and it significantly outperforms standard variational methods in scalability and accuracy. Notably, our approach achieves state-of-the-art results on CIFAR-10 among pure GP models.
Analyzing Monotonic Linear Interpolation in Neural Network Loss Landscapes
Apr 23, 2021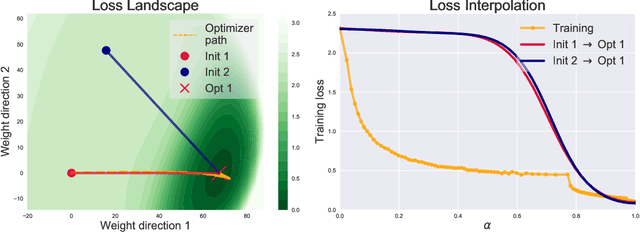


Linear interpolation between initial neural network parameters and converged parameters after training with stochastic gradient descent (SGD) typically leads to a monotonic decrease in the training objective. This Monotonic Linear Interpolation (MLI) property, first observed by Goodfellow et al. (2014) persists in spite of the non-convex objectives and highly non-linear training dynamics of neural networks. Extending this work, we evaluate several hypotheses for this property that, to our knowledge, have not yet been explored. Using tools from differential geometry, we draw connections between the interpolated paths in function space and the monotonicity of the network - providing sufficient conditions for the MLI property under mean squared error. While the MLI property holds under various settings (e.g. network architectures and learning problems), we show in practice that networks violating the MLI property can be produced systematically, by encouraging the weights to move far from initialization. The MLI property raises important questions about the loss landscape geometry of neural networks and highlights the need to further study their global properties.
Don't Fix What ain't Broke: Near-optimal Local Convergence of Alternating Gradient Descent-Ascent for Minimax Optimization
Feb 18, 2021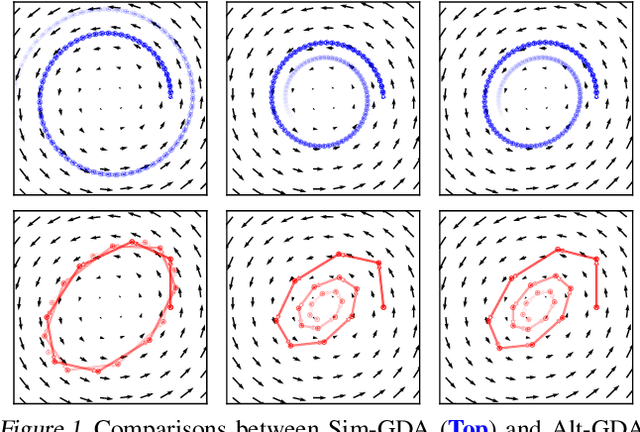

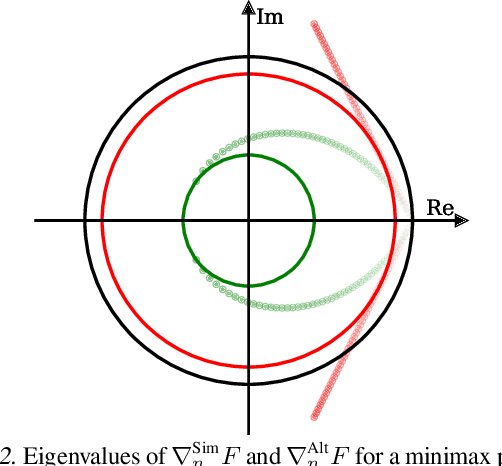
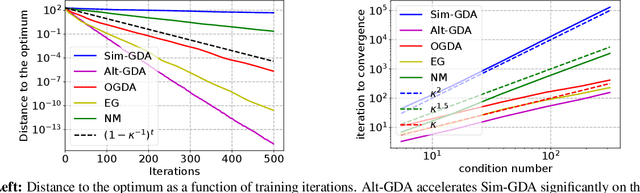
Minimax optimization has recently gained a lot of attention as adversarial architectures and algorithms proliferate. Often, smooth minimax games proceed by simultaneous or alternating gradient updates. Although algorithms with alternating updates are commonly used in practice for many applications (e.g., GAN training), the majority of existing theoretical analyses focus on simultaneous algorithms. In this paper, we study alternating gradient descent-ascent (Alt-GDA) in minimax games and show that Alt-GDA is superior to its simultaneous counterpart (Sim-GDA) in many settings. In particular, we prove that Alt-GDA achieves a near-optimal local convergence rate for strongly-convex strongly-concave problems while Sim-GDA converges with a much slower rate. Moreover, we show that the acceleration effect of alternating updates remains when the minimax problem has only strong concavity in the dual variables. Numerical experiments on quadratic minimax games validate our claims. Additionally, we demonstrate that alternating updates speed up GAN training significantly and the use of optimism only helps for simultaneous algorithms.
LIME: Learning Inductive Bias for Primitives of Mathematical Reasoning
Jan 15, 2021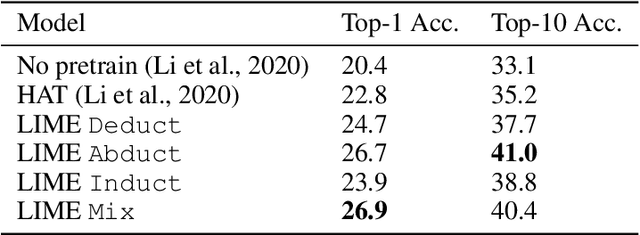
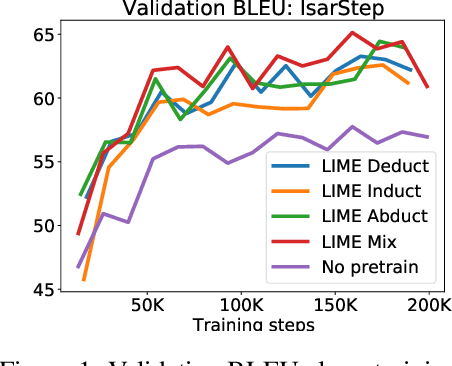

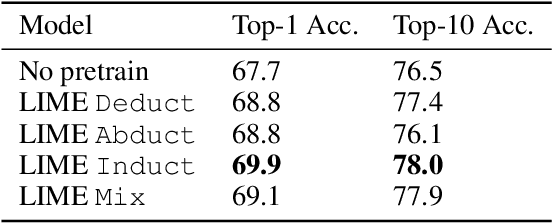
While designing inductive bias in neural architectures has been widely studied, we hypothesize that transformer networks are flexible enough to learn inductive bias from suitable generic tasks. Here, we replace architecture engineering by encoding inductive bias in the form of datasets. Inspired by Peirce's view that deduction, induction, and abduction form an irreducible set of reasoning primitives, we design three synthetic tasks that are intended to require the model to have these three abilities. We specifically design these synthetic tasks in a way that they are devoid of mathematical knowledge to ensure that only the fundamental reasoning biases can be learned from these tasks. This defines a new pre-training methodology called "LIME" (Learning Inductive bias for Mathematical rEasoning). Models trained with LIME significantly outperform vanilla transformers on three very different large mathematical reasoning benchmarks. Unlike dominating the computation cost as traditional pre-training approaches, LIME requires only a small fraction of the computation cost of the typical downstream task.
Beyond Marginal Uncertainty: How Accurately can Bayesian Regression Models Estimate Posterior Predictive Correlations?
Nov 06, 2020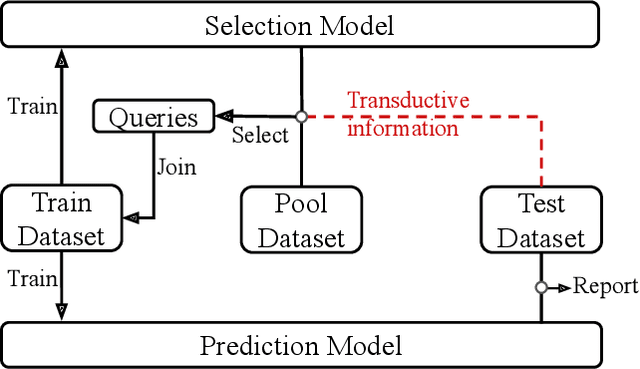
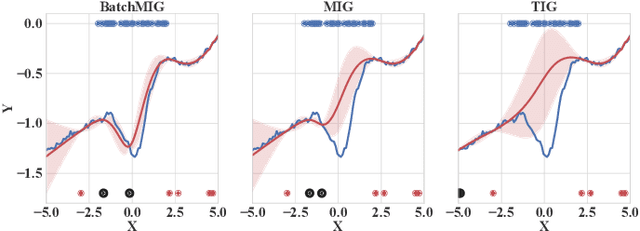
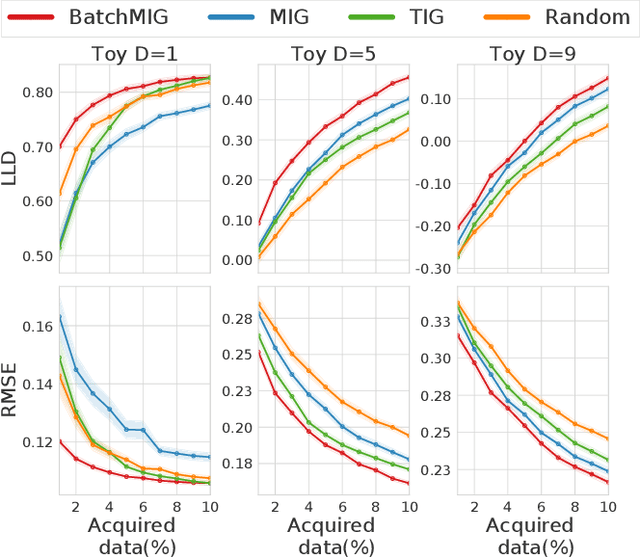
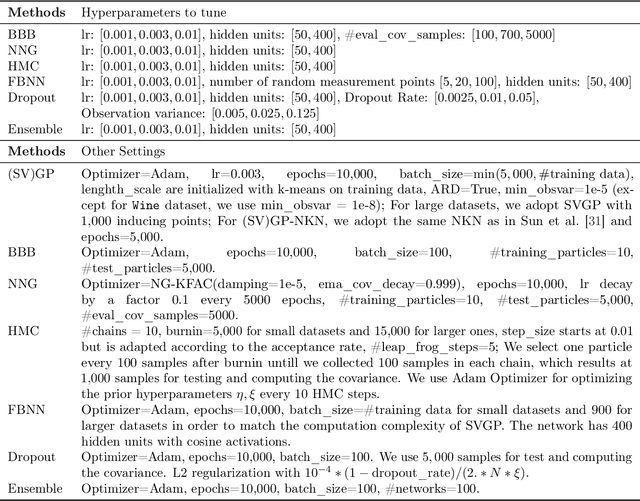
While uncertainty estimation is a well-studied topic in deep learning, most such work focuses on marginal uncertainty estimates, i.e. the predictive mean and variance at individual input locations. But it is often more useful to estimate predictive correlations between the function values at different input locations. In this paper, we consider the problem of benchmarking how accurately Bayesian models can estimate predictive correlations. We first consider a downstream task which depends on posterior predictive correlations: transductive active learning (TAL). We find that TAL makes better use of models' uncertainty estimates than ordinary active learning, and recommend this as a benchmark for evaluating Bayesian models. Since TAL is too expensive and indirect to guide development of algorithms, we introduce two metrics which more directly evaluate the predictive correlations and which can be computed efficiently: meta-correlations (i.e. the correlations between the models correlation estimates and the true values), and cross-normalized likelihoods (XLL). We validate these metrics by demonstrating their consistency with TAL performance and obtain insights about the relative performance of current Bayesian neural net and Gaussian process models.
Delta-STN: Efficient Bilevel Optimization for Neural Networks using Structured Response Jacobians
Oct 26, 2020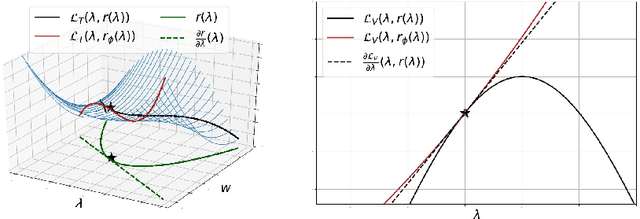
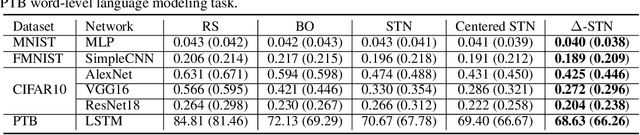
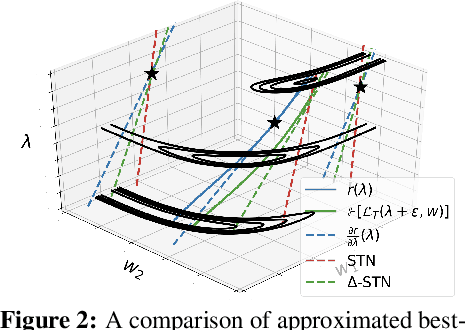

Hyperparameter optimization of neural networks can be elegantly formulated as a bilevel optimization problem. While research on bilevel optimization of neural networks has been dominated by implicit differentiation and unrolling, hypernetworks such as Self-Tuning Networks (STNs) have recently gained traction due to their ability to amortize the optimization of the inner objective. In this paper, we diagnose several subtle pathologies in the training of STNs. Based on these observations, we propose the $\Delta$-STN, an improved hypernetwork architecture which stabilizes training and optimizes hyperparameters much more efficiently than STNs. The key idea is to focus on accurately approximating the best-response Jacobian rather than the full best-response function; we achieve this by reparameterizing the hypernetwork and linearizing the network around the current parameters. We demonstrate empirically that our $\Delta$-STN can tune regularization hyperparameters (e.g. weight decay, dropout, number of cutout holes) with higher accuracy, faster convergence, and improved stability compared to existing approaches.
A Unified Analysis of First-Order Methods for Smooth Games via Integral Quadratic Constraints
Oct 02, 2020
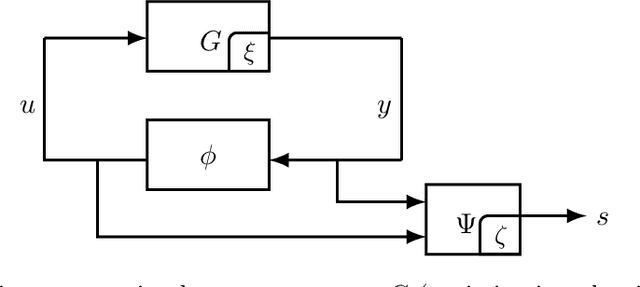
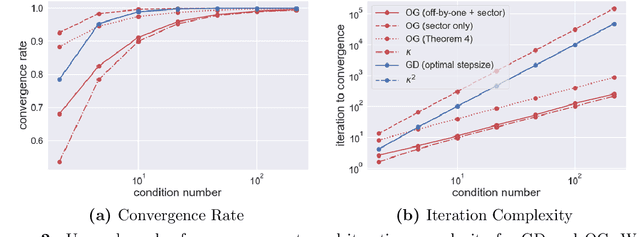
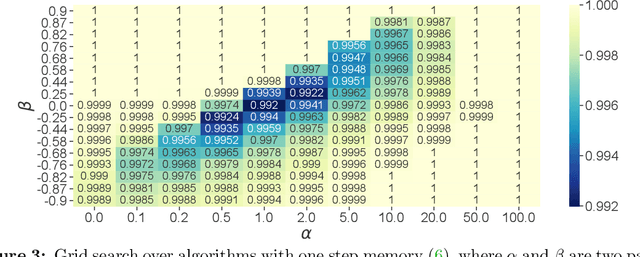
The theory of integral quadratic constraints (IQCs) allows the certification of exponential convergence of interconnected systems containing nonlinear or uncertain elements. In this work, we adapt the IQC theory to study first-order methods for smooth and strongly-monotone games and show how to design tailored quadratic constraints to get tight upper bounds of convergence rates. Using this framework, we recover the existing bound for the gradient method~(GD), derive sharper bounds for the proximal point method~(PPM) and optimistic gradient method~(OG), and provide \emph{for the first time} a global convergence rate for the negative momentum method~(NM) with an iteration complexity $\bigo(\kappa^{1.5})$, which matches its known lower bound. In addition, for time-varying systems, we prove that the gradient method with optimal step size achieves the fastest provable worst-case convergence rate with quadratic Lyapunov functions. Finally, we further extend our analysis to stochastic games and study the impact of multiplicative noise on different algorithms. We show that it is impossible for an algorithm with one step of memory to achieve acceleration if it only queries the gradient once per batch (in contrast with the stochastic strongly-convex optimization setting, where such acceleration has been demonstrated). However, we exhibit an algorithm which achieves acceleration with two gradient queries per batch.