 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrand > Logo: Visual Analysis of Fashion Brands
Oct 23, 2018
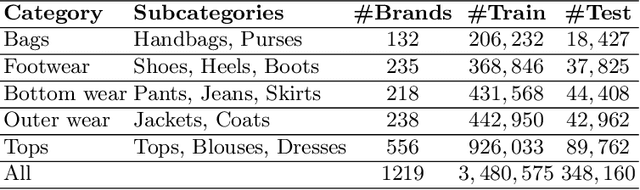

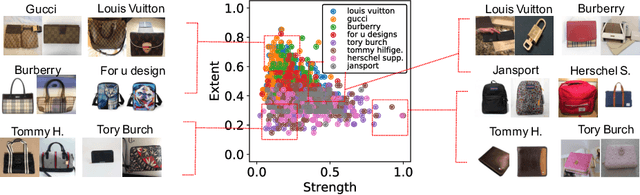
While lots of people may think branding begins and ends with a logo, fashion brands communicate their uniqueness through a wide range of visual cues such as color, patterns and shapes. In this work, we analyze learned visual representations by deep networks that are trained to recognize fashion brands. In particular, the activation strength and extent of neurons are studied to provide interesting insights about visual brand expressions. The proposed method identifies where a brand stands in the spectrum of branding strategy, i.e., from trademark-emblazoned goods with bold logos to implicit no logo marketing. By quantifying attention maps, we are able to interpret the visual characteristics of a brand present in a single image and model the general design direction of a brand as a whole. We further investigate versatility of neurons and discover "specialists" that are highly brand-specific and "generalists" that detect diverse visual features. A human experiment based on three main visual scenarios of fashion brands is conducted to verify the alignment of our quantitative measures with the human perception of brands. This paper demonstrate how deep networks go beyond logos in order to recognize clothing brands in an image.
ModaNet: A Large-Scale Street Fashion Dataset with Polygon Annotations
Oct 23, 2018

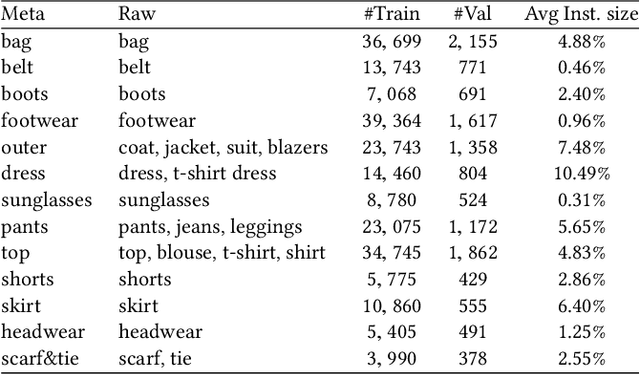
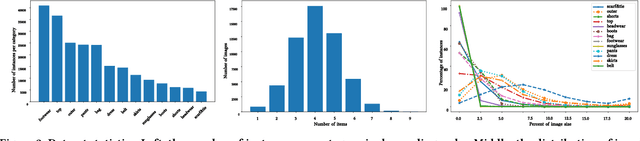
Understanding clothes from a single image has strong commercial and cultural impacts on modern societies. However, this task remains a challenging computer vision problem due to wide variations in the appearance, style, brand and layering of clothing items. We present a new database called ModaNet, a large-scale collection of images based on Paperdoll dataset. Our dataset provides 55,176 street images, fully annotated with polygons on top of the 1 million weakly annotated street images in Paperdoll. ModaNet aims to provide a technical benchmark to fairly evaluate the progress of applying the latest computer vision techniques that rely on large data for fashion understanding. The rich annotation of the dataset allows to measure the performance of state-of-the-art algorithms for object detection, semantic segmentation and polygon prediction on street fashion images in detail. The polygon-based annotation dataset has been released https://github.com/eBay/modanet, we also host the leaderboard at EvalAI: https://evalai.cloudcv.org/featured-challenges/136/overview.
Give me a hint! Navigating Image Databases using Human-in-the-loop Feedback
Sep 24, 2018
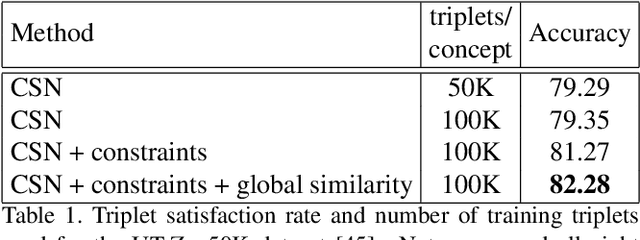
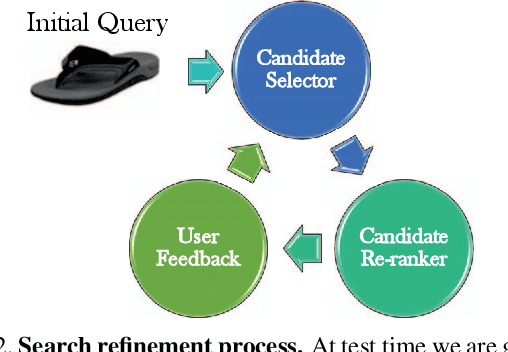
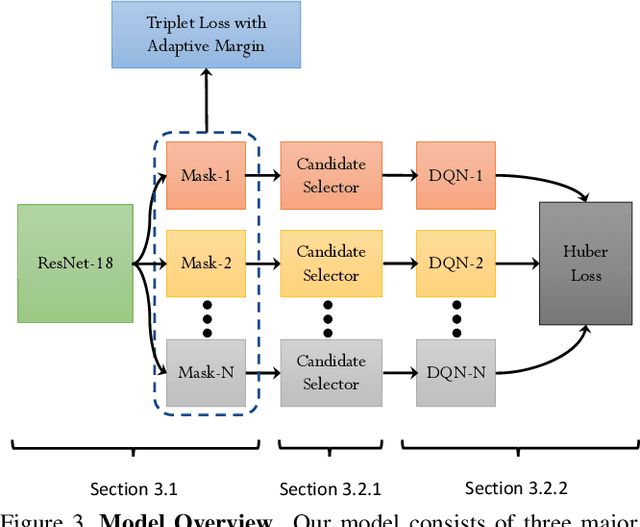
In this paper, we introduce an attribute-based interactive image search which can leverage human-in-the-loop feedback to iteratively refine image search results. We study active image search where human feedback is solicited exclusively in visual form, without using relative attribute annotations used by prior work which are not typically found in many datasets. In order to optimize the image selection strategy, a deep reinforcement model is trained to learn what images are informative rather than rely on hand-crafted measures typically leveraged in prior work. Additionally, we extend the recently introduced Conditional Similarity Network to incorporate global similarity in training visual embeddings, which results in more natural transitions as the user explores the learned similarity embeddings. Our experiments demonstrate the effectiveness of our approach, producing compelling results on both active image search and image attribute representation tasks.
Conditional Image-Text Embedding Networks
Jul 28, 2018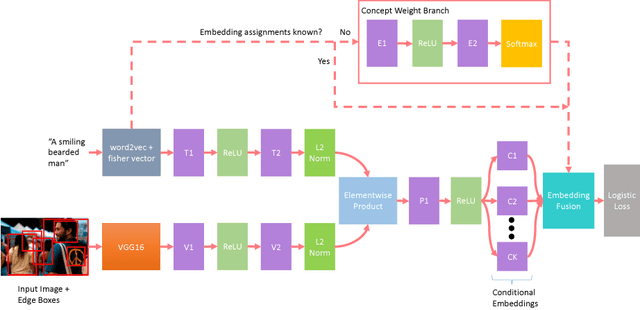
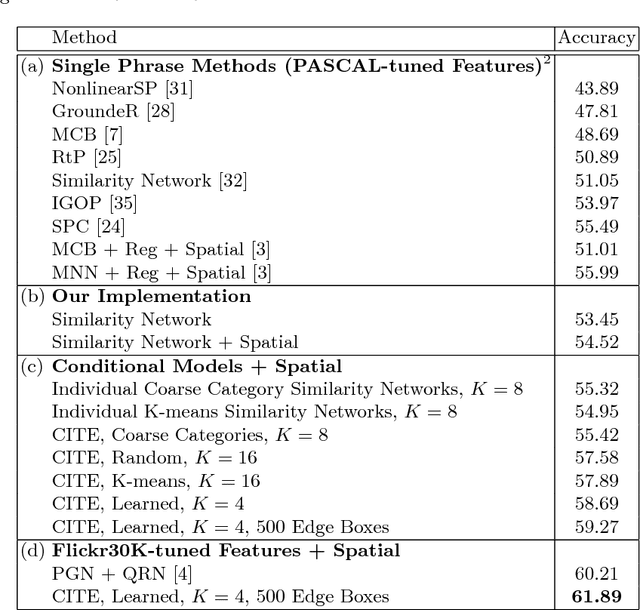

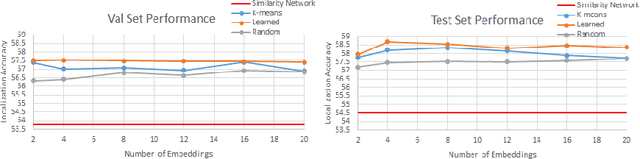
This paper presents an approach for grounding phrases in images which jointly learns multiple text-conditioned embeddings in a single end-to-end model. In order to differentiate text phrases into semantically distinct subspaces, we propose a concept weight branch that automatically assigns phrases to embeddings, whereas prior works predefine such assignments. Our proposed solution simplifies the representation requirements for individual embeddings and allows the underrepresented concepts to take advantage of the shared representations before feeding them into concept-specific layers. Comprehensive experiments verify the effectiveness of our approach across three phrase grounding datasets, Flickr30K Entities, ReferIt Game, and Visual Genome, where we obtain a (resp.) 4%, 3%, and 4% improvement in grounding performance over a strong region-phrase embedding baseline.
Adversarial Learning for Fine-grained Image Search
Jul 06, 2018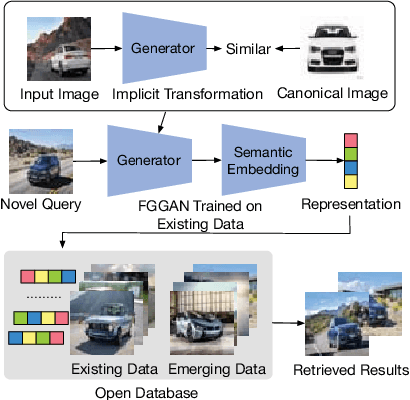
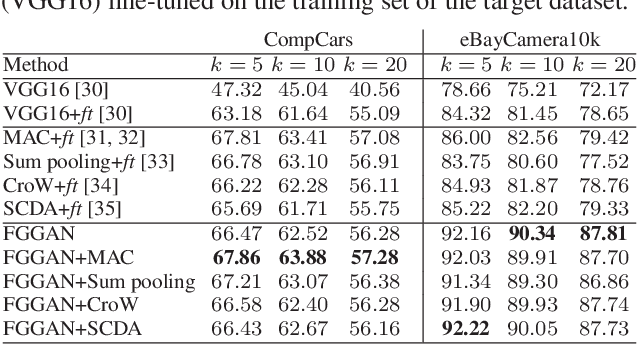
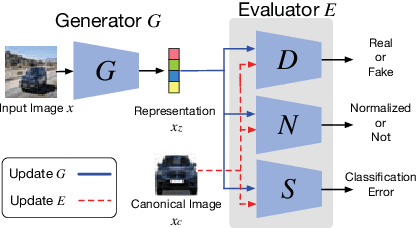
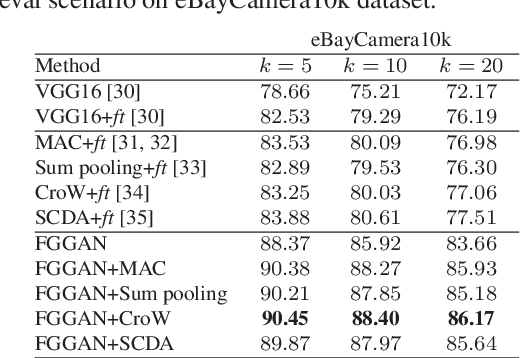
Fine-grained image search is still a challenging problem due to the difficulty in capturing subtle differences regardless of pose variations of objects from fine-grained categories. In practice, a dynamic inventory with new fine-grained categories adds another dimension to this challenge. In this work, we propose an end-to-end network, called FGGAN, that learns discriminative representations by implicitly learning a geometric transformation from multi-view images for fine-grained image search. We integrate a generative adversarial network (GAN) that can automatically handle complex view and pose variations by converting them to a canonical view without any predefined transformations. Moreover, in an open-set scenario, our network is able to better match images from unseen and unknown fine-grained categories. Extensive experiments on two public datasets and a newly collected dataset have demonstrated the outstanding robust performance of the proposed FGGAN in both closed-set and open-set scenarios, providing as much as 10% relative improvement compared to baselines.
Towards the Success Rate of One: Real-time Unconstrained Salient Object Detection
Aug 02, 2017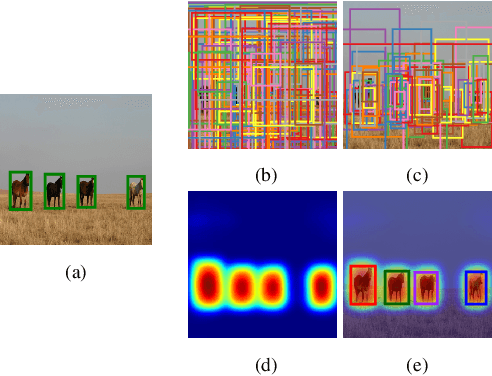
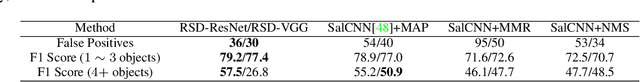
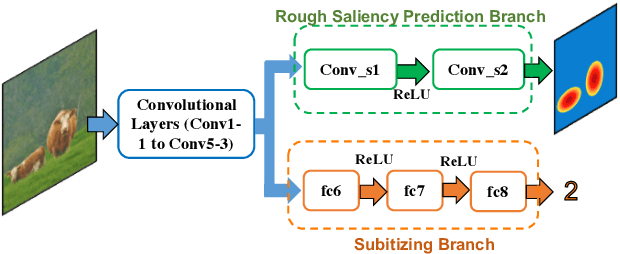

In this work, we propose an efficient and effective approach for unconstrained salient object detection in images using deep convolutional neural networks. Instead of generating thousands of candidate bounding boxes and refining them, our network directly learns to generate the saliency map containing the exact number of salient objects. During training, we convert the ground-truth rectangular boxes to Gaussian distributions that better capture the ROI regarding individual salient objects. During inference, the network predicts Gaussian distributions centered at salient objects with an appropriate covariance, from which bounding boxes are easily inferred. Notably, our network performs saliency map prediction without pixel-level annotations, salient object detection without object proposals, and salient object subitizing simultaneously, all in a single pass within a unified framework. Extensive experiments show that our approach outperforms existing methods on various datasets by a large margin, and achieves more than 100 fps with VGG16 network on a single GPU during inference.
Visual Search at eBay
Jul 07, 2017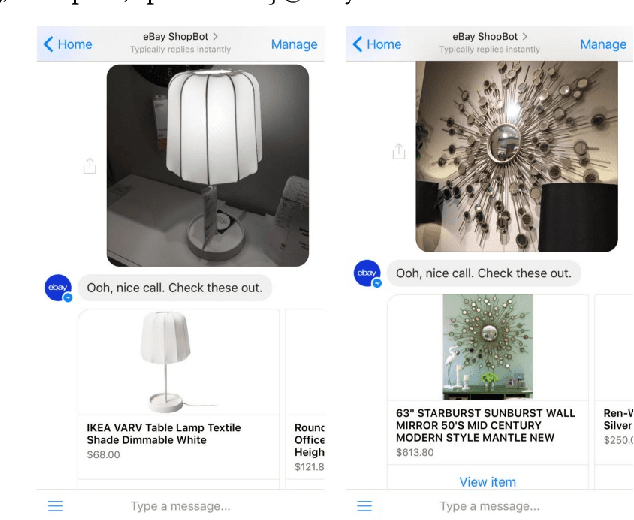

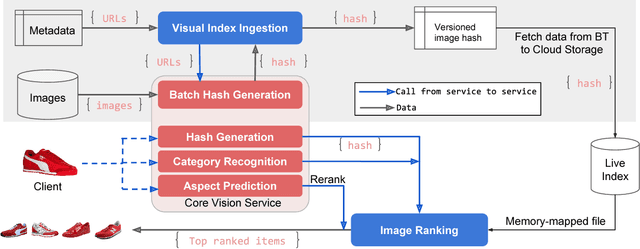

In this paper, we propose a novel end-to-end approach for scalable visual search infrastructure. We discuss the challenges we faced for a massive volatile inventory like at eBay and present our solution to overcome those. We harness the availability of large image collection of eBay listings and state-of-the-art deep learning techniques to perform visual search at scale. Supervised approach for optimized search limited to top predicted categories and also for compact binary signature are key to scale up without compromising accuracy and precision. Both use a common deep neural network requiring only a single forward inference. The system architecture is presented with in-depth discussions of its basic components and optimizations for a trade-off between search relevance and latency. This solution is currently deployed in a distributed cloud infrastructure and fuels visual search in eBay ShopBot and Close5. We show benchmark on ImageNet dataset on which our approach is faster and more accurate than several unsupervised baselines. We share our learnings with the hope that visual search becomes a first class citizen for all large scale search engines rather than an afterthought.
Fashion Apparel Detection: The Role of Deep Convolutional Neural Network and Pose-dependent Priors
Jan 24, 2016In this work, we propose and address a new computer vision task, which we call fashion item detection, where the aim is to detect various fashion items a person in the image is wearing or carrying. The types of fashion items we consider in this work include hat, glasses, bag, pants, shoes and so on. The detection of fashion items can be an important first step of various e-commerce applications for fashion industry. Our method is based on state-of-the-art object detection method pipeline which combines object proposal methods with a Deep Convolutional Neural Network. Since the locations of fashion items are in strong correlation with the locations of body joints positions, we incorporate contextual information from body poses in order to improve the detection performance. Through the experiments, we demonstrate the effectiveness of the proposed method.
HD-CNN: Hierarchical Deep Convolutional Neural Network for Large Scale Visual Recognition
May 16, 2015

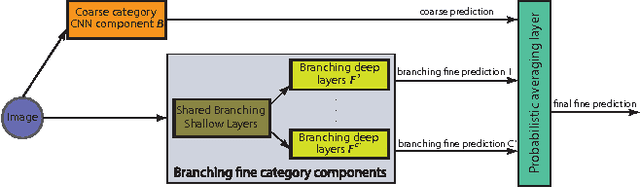
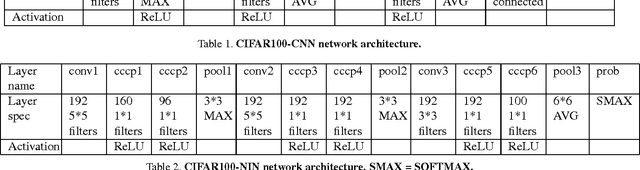
In image classification, visual separability between different object categories is highly uneven, and some categories are more difficult to distinguish than others. Such difficult categories demand more dedicated classifiers. However, existing deep convolutional neural networks (CNN) are trained as flat N-way classifiers, and few efforts have been made to leverage the hierarchical structure of categories. In this paper, we introduce hierarchical deep CNNs (HD-CNNs) by embedding deep CNNs into a category hierarchy. An HD-CNN separates easy classes using a coarse category classifier while distinguishing difficult classes using fine category classifiers. During HD-CNN training, component-wise pretraining is followed by global finetuning with a multinomial logistic loss regularized by a coarse category consistency term. In addition, conditional executions of fine category classifiers and layer parameter compression make HD-CNNs scalable for large-scale visual recognition. We achieve state-of-the-art results on both CIFAR100 and large-scale ImageNet 1000-class benchmark datasets. In our experiments, we build up three different HD-CNNs and they lower the top-1 error of the standard CNNs by 2.65%, 3.1% and 1.1%, respectively.
Im2Fit: Fast 3D Model Fitting and Anthropometrics using Single Consumer Depth Camera and Synthetic Data
Nov 19, 2014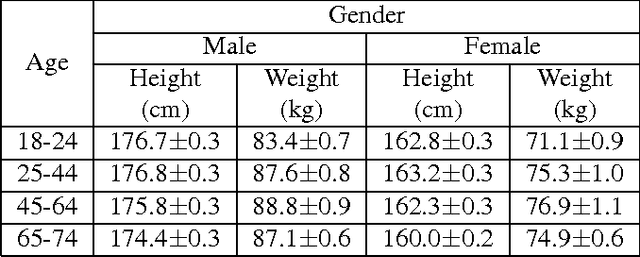
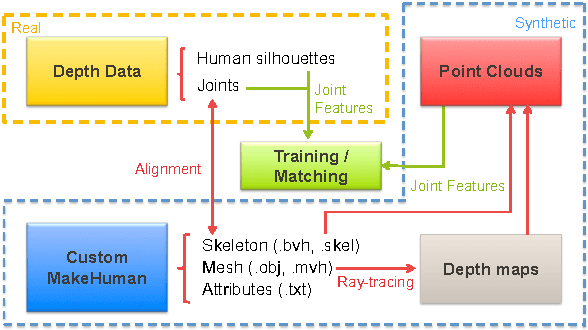
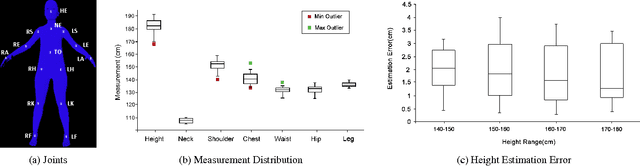
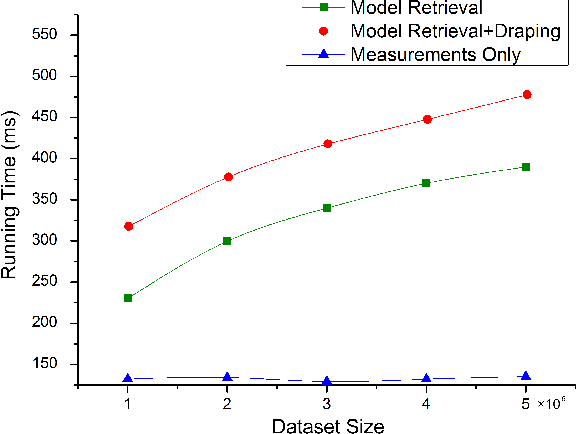
Recent advances in consumer depth sensors have created many opportunities for human body measurement and modeling. Estimation of 3D body shape is particularly useful for fashion e-commerce applications such as virtual try-on or fit personalization. In this paper, we propose a method for capturing accurate human body shape and anthropometrics from a single consumer grade depth sensor. We first generate a large dataset of synthetic 3D human body models using real-world body size distributions. Next, we estimate key body measurements from a single monocular depth image. We combine body measurement estimates with local geometry features around key joint positions to form a robust multi-dimensional feature vector. This allows us to conduct a fast nearest-neighbor search to every sample in the dataset and return the closest one. Compared to existing methods, our approach is able to predict accurate full body parameters from a partial view using measurement parameters learned from the synthetic dataset. Furthermore, our system is capable of generating 3D human mesh models in real-time, which is significantly faster than methods which attempt to model shape and pose deformations. To validate the efficiency and applicability of our system, we collected a dataset that contains frontal and back scans of 83 clothed people with ground truth height and weight. Experiments on real-world dataset show that the proposed method can achieve real-time performance with competing results achieving an average error of 1.9 cm in estimated measurements.