 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe Can't Understand AI Using our Existing Vocabulary
Feb 11, 2025

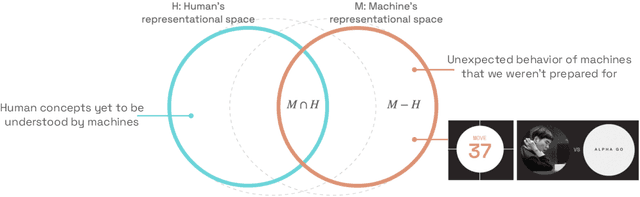

This position paper argues that, in order to understand AI, we cannot rely on our existing vocabulary of human words. Instead, we should strive to develop neologisms: new words that represent precise human concepts that we want to teach machines, or machine concepts that we need to learn. We start from the premise that humans and machines have differing concepts. This means interpretability can be framed as a communication problem: humans must be able to reference and control machine concepts, and communicate human concepts to machines. Creating a shared human-machine language through developing neologisms, we believe, could solve this communication problem. Successful neologisms achieve a useful amount of abstraction: not too detailed, so they're reusable in many contexts, and not too high-level, so they convey precise information. As a proof of concept, we demonstrate how a "length neologism" enables controlling LLM response length, while a "diversity neologism" allows sampling more variable responses. Taken together, we argue that we cannot understand AI using our existing vocabulary, and expanding it through neologisms creates opportunities for both controlling and understanding machines better.
Do generative video models learn physical principles from watching videos?
Jan 14, 2025AI video generation is undergoing a revolution, with quality and realism advancing rapidly. These advances have led to a passionate scientific debate: Do video models learn ``world models'' that discover laws of physics -- or, alternatively, are they merely sophisticated pixel predictors that achieve visual realism without understanding the physical principles of reality? We address this question by developing Physics-IQ, a comprehensive benchmark dataset that can only be solved by acquiring a deep understanding of various physical principles, like fluid dynamics, optics, solid mechanics, magnetism and thermodynamics. We find that across a range of current models (Sora, Runway, Pika, Lumiere, Stable Video Diffusion, and VideoPoet), physical understanding is severely limited, and unrelated to visual realism. At the same time, some test cases can already be successfully solved. This indicates that acquiring certain physical principles from observation alone may be possible, but significant challenges remain. While we expect rapid advances ahead, our work demonstrates that visual realism does not imply physical understanding. Our project page is at https://physics-iq.github.io; code at https://github.com/google-deepmind/physics-IQ-benchmark.
Learning Visual Composition through Improved Semantic Guidance
Dec 19, 2024



Visual imagery does not consist of solitary objects, but instead reflects the composition of a multitude of fluid concepts. While there have been great advances in visual representation learning, such advances have focused on building better representations for a small number of discrete objects bereft of an understanding of how these objects are interacting. One can observe this limitation in representations learned through captions or contrastive learning -- where the learned model treats an image essentially as a bag of words. Several works have attempted to address this limitation through the development of bespoke learned architectures to directly address the shortcomings in compositional learning. In this work, we focus on simple, and scalable approaches. In particular, we demonstrate that by substantially improving weakly labeled data, i.e. captions, we can vastly improve the performance of standard contrastive learning approaches. Previous CLIP models achieved near chance rate on challenging tasks probing compositional learning. However, our simple approach boosts performance of CLIP substantially and surpasses all bespoke architectures. Furthermore, we showcase our results on a relatively new captioning benchmark derived from DOCCI. We demonstrate through a series of ablations that a standard CLIP model trained with enhanced data may demonstrate impressive performance on image retrieval tasks.
Towards flexible perception with visual memory
Aug 15, 2024



Training a neural network is a monolithic endeavor, akin to carving knowledge into stone: once the process is completed, editing the knowledge in a network is nearly impossible, since all information is distributed across the network's weights. We here explore a simple, compelling alternative by marrying the representational power of deep neural networks with the flexibility of a database. Decomposing the task of image classification into image similarity (from a pre-trained embedding) and search (via fast nearest neighbor retrieval from a knowledge database), we build a simple and flexible visual memory that has the following key capabilities: (1.) The ability to flexibly add data across scales: from individual samples all the way to entire classes and billion-scale data; (2.) The ability to remove data through unlearning and memory pruning; (3.) An interpretable decision-mechanism on which we can intervene to control its behavior. Taken together, these capabilities comprehensively demonstrate the benefits of an explicit visual memory. We hope that it might contribute to a conversation on how knowledge should be represented in deep vision models -- beyond carving it in ``stone'' weights.
How Aligned are Different Alignment Metrics?
Jul 10, 2024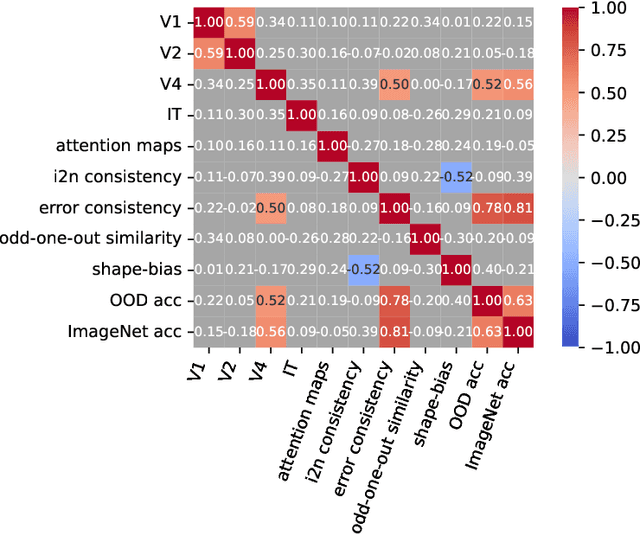
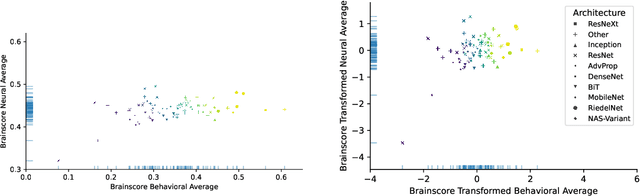
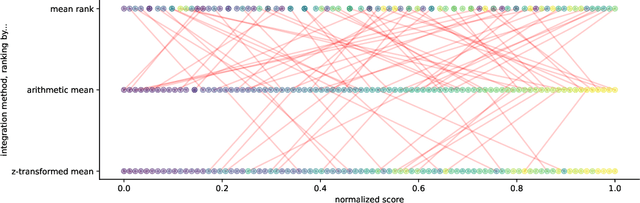
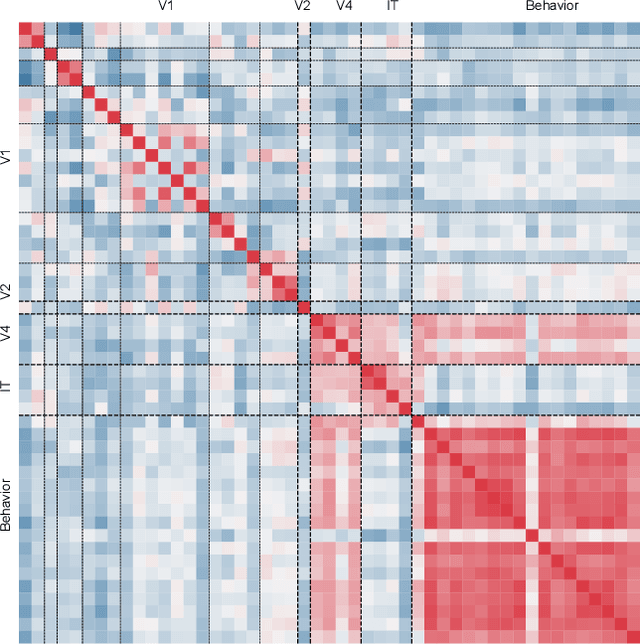
In recent years, various methods and benchmarks have been proposed to empirically evaluate the alignment of artificial neural networks to human neural and behavioral data. But how aligned are different alignment metrics? To answer this question, we analyze visual data from Brain-Score (Schrimpf et al., 2018), including metrics from the model-vs-human toolbox (Geirhos et al., 2021), together with human feature alignment (Linsley et al., 2018; Fel et al., 2022) and human similarity judgements (Muttenthaler et al., 2022). We find that pairwise correlations between neural scores and behavioral scores are quite low and sometimes even negative. For instance, the average correlation between those 80 models on Brain-Score that were fully evaluated on all 69 alignment metrics we considered is only 0.198. Assuming that all of the employed metrics are sound, this implies that alignment with human perception may best be thought of as a multidimensional concept, with different methods measuring fundamentally different aspects. Our results underline the importance of integrative benchmarking, but also raise questions about how to correctly combine and aggregate individual metrics. Aggregating by taking the arithmetic average, as done in Brain-Score, leads to the overall performance currently being dominated by behavior (95.25% explained variance) while the neural predictivity plays a less important role (only 33.33% explained variance). As a first step towards making sure that different alignment metrics all contribute fairly towards an integrative benchmark score, we therefore conclude by comparing three different aggregation options.
Are Vision Language Models Texture or Shape Biased and Can We Steer Them?
Mar 14, 2024



Vision language models (VLMs) have drastically changed the computer vision model landscape in only a few years, opening an exciting array of new applications from zero-shot image classification, over to image captioning, and visual question answering. Unlike pure vision models, they offer an intuitive way to access visual content through language prompting. The wide applicability of such models encourages us to ask whether they also align with human vision - specifically, how far they adopt human-induced visual biases through multimodal fusion, or whether they simply inherit biases from pure vision models. One important visual bias is the texture vs. shape bias, or the dominance of local over global information. In this paper, we study this bias in a wide range of popular VLMs. Interestingly, we find that VLMs are often more shape-biased than their vision encoders, indicating that visual biases are modulated to some extent through text in multimodal models. If text does indeed influence visual biases, this suggests that we may be able to steer visual biases not just through visual input but also through language: a hypothesis that we confirm through extensive experiments. For instance, we are able to steer shape bias from as low as 49% to as high as 72% through prompting alone. For now, the strong human bias towards shape (96%) remains out of reach for all tested VLMs.
Neither hype nor gloom do DNNs justice
Dec 08, 2023Neither the hype exemplified in some exaggerated claims about deep neural networks (DNNs), nor the gloom expressed by Bowers et al. do DNNs as models in vision science justice: DNNs rapidly evolve, and today's limitations are often tomorrow's successes. In addition, providing explanations as well as prediction and image-computability are model desiderata; one should not be favoured at the expense of the other.
Getting aligned on representational alignment
Nov 02, 2023



Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Intriguing properties of generative classifiers
Sep 28, 2023



What is the best paradigm to recognize objects -- discriminative inference (fast but potentially prone to shortcut learning) or using a generative model (slow but potentially more robust)? We build on recent advances in generative modeling that turn text-to-image models into classifiers. This allows us to study their behavior and to compare them against discriminative models and human psychophysical data. We report four intriguing emergent properties of generative classifiers: they show a record-breaking human-like shape bias (99% for Imagen), near human-level out-of-distribution accuracy, state-of-the-art alignment with human classification errors, and they understand certain perceptual illusions. Our results indicate that while the current dominant paradigm for modeling human object recognition is discriminative inference, zero-shot generative models approximate human object recognition data surprisingly well.
Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
Jul 12, 2023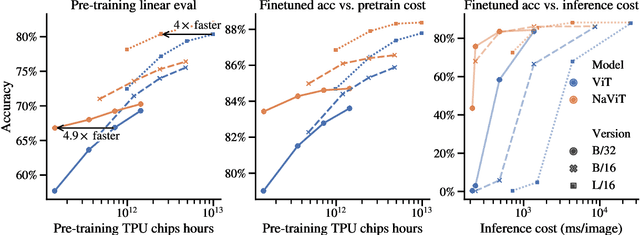
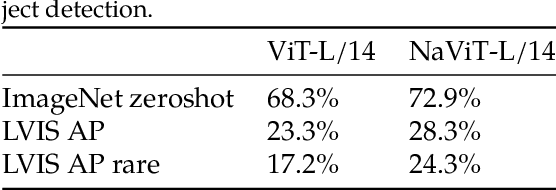
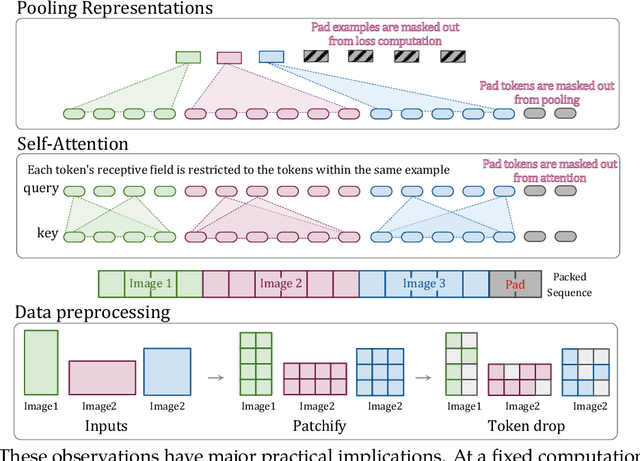
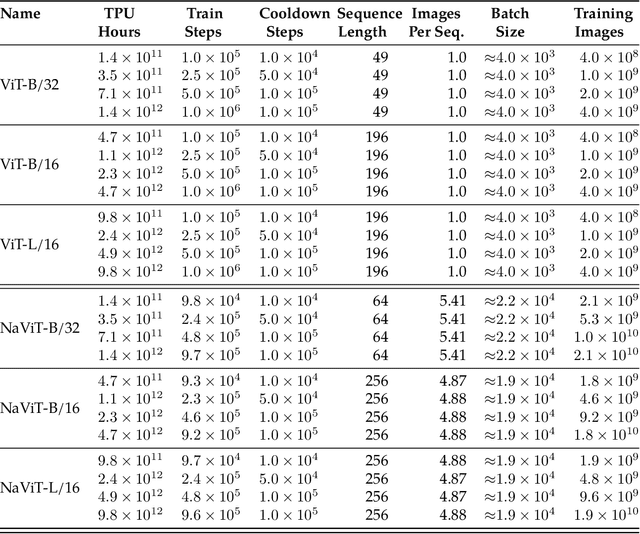
The ubiquitous and demonstrably suboptimal choice of resizing images to a fixed resolution before processing them with computer vision models has not yet been successfully challenged. However, models such as the Vision Transformer (ViT) offer flexible sequence-based modeling, and hence varying input sequence lengths. We take advantage of this with NaViT (Native Resolution ViT) which uses sequence packing during training to process inputs of arbitrary resolutions and aspect ratios. Alongside flexible model usage, we demonstrate improved training efficiency for large-scale supervised and contrastive image-text pretraining. NaViT can be efficiently transferred to standard tasks such as image and video classification, object detection, and semantic segmentation and leads to improved results on robustness and fairness benchmarks. At inference time, the input resolution flexibility can be used to smoothly navigate the test-time cost-performance trade-off. We believe that NaViT marks a departure from the standard, CNN-designed, input and modelling pipeline used by most computer vision models, and represents a promising direction for ViTs.