 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Schrödinger Bridge Matching
Oct 03, 2023Modern distribution matching algorithms for training diffusion or flow models directly prescribe the time evolution of the marginal distributions between two boundary distributions. In this work, we consider a generalized distribution matching setup, where these marginals are only implicitly described as a solution to some task-specific objective function. The problem setup, known as the Generalized Schr\"odinger Bridge (GSB), appears prevalently in many scientific areas both within and without machine learning. We propose Generalized Schr\"odinger Bridge Matching (GSBM), a new matching algorithm inspired by recent advances, generalizing them beyond kinetic energy minimization and to account for task-specific state costs. We show that such a generalization can be cast as solving conditional stochastic optimal control, for which efficient variational approximations can be used, and further debiased with the aid of path integral theory. Compared to prior methods for solving GSB problems, our GSBM algorithm always preserves a feasible transport map between the boundary distributions throughout training, thereby enabling stable convergence and significantly improved scalability. We empirically validate our claims on an extensive suite of experimental setups, including crowd navigation, opinion depolarization, LiDAR manifolds, and image domain transfer. Our work brings new algorithmic opportunities for training diffusion models enhanced with task-specific optimality structures.
On Kinetic Optimal Probability Paths for Generative Models
Jun 11, 2023Recent successful generative models are trained by fitting a neural network to an a-priori defined tractable probability density path taking noise to training examples. In this paper we investigate the space of Gaussian probability paths, which includes diffusion paths as an instance, and look for an optimal member in some useful sense. In particular, minimizing the Kinetic Energy (KE) of a path is known to make particles' trajectories simple, hence easier to sample, and empirically improve performance in terms of likelihood of unseen data and sample generation quality. We investigate Kinetic Optimal (KO) Gaussian paths and offer the following observations: (i) We show the KE takes a simplified form on the space of Gaussian paths, where the data is incorporated only through a single, one dimensional scalar function, called the \emph{data separation function}. (ii) We characterize the KO solutions with a one dimensional ODE. (iii) We approximate data-dependent KO paths by approximating the data separation function and minimizing the KE. (iv) We prove that the data separation function converges to $1$ in the general case of arbitrary normalized dataset consisting of $n$ samples in $d$ dimension as $n/\sqrt{d}\rightarrow 0$. A consequence of this result is that the Conditional Optimal Transport (Cond-OT) path becomes \emph{kinetic optimal} as $n/\sqrt{d}\rightarrow 0$. We further support this theory with empirical experiments on ImageNet.
Distributional GFlowNets with Quantile Flows
Feb 11, 2023



Generative Flow Networks (GFlowNets) are a new family of probabilistic samplers where an agent learns a stochastic policy for generating complex combinatorial structure through a series of decision-making steps. Despite being inspired from reinforcement learning, the current GFlowNet framework is relatively limited in its applicability and cannot handle stochasticity in the reward function. In this work, we adopt a distributional paradigm for GFlowNets, turning each flow function into a distribution, thus providing more informative learning signals during training. By parameterizing each edge flow through their quantile functions, our proposed \textit{quantile matching} GFlowNet learning algorithm is able to learn a risk-sensitive policy, an essential component for handling scenarios with risk uncertainty. Moreover, we find that the distributional approach can achieve substantial improvement on existing benchmarks compared to prior methods due to our enhanced training algorithm, even in settings with deterministic rewards.
Riemannian Flow Matching on General Geometries
Feb 07, 2023We propose Riemannian Flow Matching (RFM), a simple yet powerful framework for training continuous normalizing flows on manifolds. Existing methods for generative modeling on manifolds either require expensive simulation, inherently cannot scale to high dimensions, or use approximations to limiting quantities that result in biased objectives. Riemannian Flow Matching bypasses these inconveniences and exhibits multiple benefits over prior approaches: It is completely simulation-free on simple geometries, it does not require divergence computation, and its target vector field is computed in closed form even on general geometries. The key ingredient behind RFM is the construction of a simple kernel function for defining per-sample vector fields, which subsumes existing Euclidean cases. Extending to general geometries, we rely on the use of spectral decompositions to efficiently compute kernel functions. Our method achieves state-of-the-art performance on real-world non-Euclidean datasets, and we showcase, for the first time, tractable training on general geometries, including on triangular meshes and maze-like manifolds with boundaries.
Latent Discretization for Continuous-time Sequence Compression
Dec 28, 2022



Neural compression offers a domain-agnostic approach to creating codecs for lossy or lossless compression via deep generative models. For sequence compression, however, most deep sequence models have costs that scale with the sequence length rather than the sequence complexity. In this work, we instead treat data sequences as observations from an underlying continuous-time process and learn how to efficiently discretize while retaining information about the full sequence. As a consequence of decoupling sequential information from its temporal discretization, our approach allows for greater compression rates and smaller computational complexity. Moreover, the continuous-time approach naturally allows us to decode at different time intervals. We empirically verify our approach on multiple domains involving compression of video and motion capture sequences, showing that our approaches can automatically achieve reductions in bit rates by learning how to discretize.
Flow Matching for Generative Modeling
Oct 06, 2022
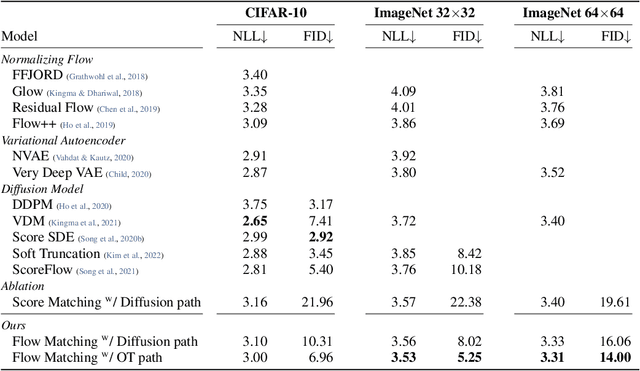

We introduce a new paradigm for generative modeling built on Continuous Normalizing Flows (CNFs), allowing us to train CNFs at unprecedented scale. Specifically, we present the notion of Flow Matching (FM), a simulation-free approach for training CNFs based on regressing vector fields of fixed conditional probability paths. Flow Matching is compatible with a general family of Gaussian probability paths for transforming between noise and data samples -- which subsumes existing diffusion paths as specific instances. Interestingly, we find that employing FM with diffusion paths results in a more robust and stable alternative for training diffusion models. Furthermore, Flow Matching opens the door to training CNFs with other, non-diffusion probability paths. An instance of particular interest is using Optimal Transport (OT) displacement interpolation to define the conditional probability paths. These paths are more efficient than diffusion paths, provide faster training and sampling, and result in better generalization. Training CNFs using Flow Matching on ImageNet leads to state-of-the-art performance in terms of both likelihood and sample quality, and allows fast and reliable sample generation using off-the-shelf numerical ODE solvers.
Neural Conservation Laws: A Divergence-Free Perspective
Oct 04, 2022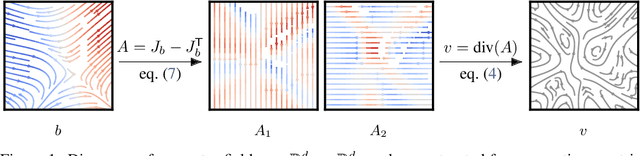
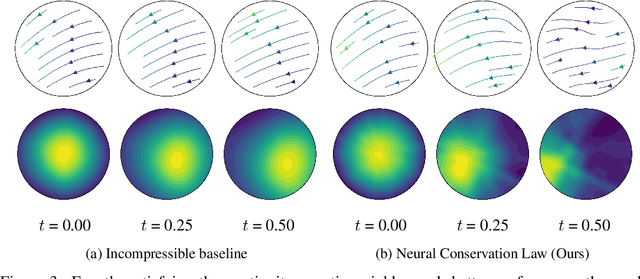
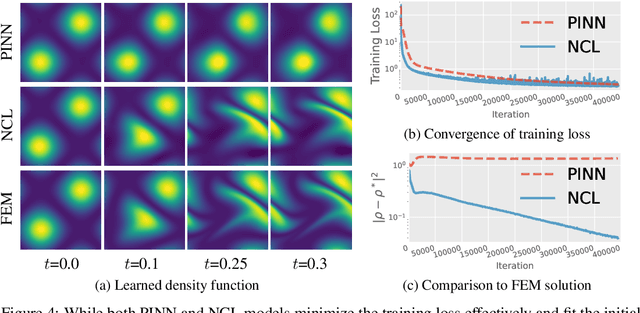
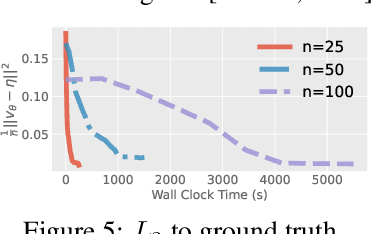
We investigate the parameterization of deep neural networks that by design satisfy the continuity equation, a fundamental conservation law. This is enabled by the observation that solutions of the continuity equation can be represented as a divergence-free vector field. We hence propose building divergence-free neural networks through the concept of differential forms, and with the aid of automatic differentiation, realize two practical constructions. As a result, we can parameterize pairs of densities and vector fields that always satisfy the continuity equation by construction, foregoing the need for extra penalty methods or expensive numerical simulation. Furthermore, we prove these models are universal and so can be used to represent any divergence-free vector field. Finally, we experimentally validate our approaches on neural network-based solutions to fluid equations, solving for the Hodge decomposition, and learning dynamical optimal transport maps the Hodge decomposition, and learning dynamical optimal transport maps.
Latent State Marginalization as a Low-cost Approach for Improving Exploration
Oct 03, 2022

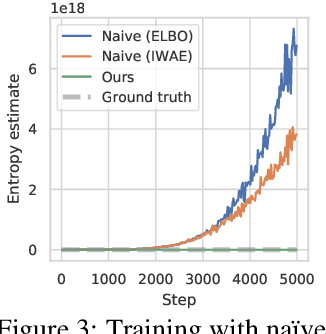
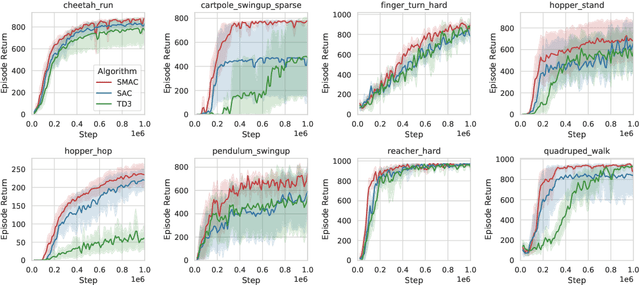
While the maximum entropy (MaxEnt) reinforcement learning (RL) framework -- often touted for its exploration and robustness capabilities -- is usually motivated from a probabilistic perspective, the use of deep probabilistic models has not gained much traction in practice due to their inherent complexity. In this work, we propose the adoption of latent variable policies within the MaxEnt framework, which we show can provably approximate any policy distribution, and additionally, naturally emerges under the use of world models with a latent belief state. We discuss why latent variable policies are difficult to train, how naive approaches can fail, then subsequently introduce a series of improvements centered around low-cost marginalization of the latent state, allowing us to make full use of the latent state at minimal additional cost. We instantiate our method under the actor-critic framework, marginalizing both the actor and critic. The resulting algorithm, referred to as Stochastic Marginal Actor-Critic (SMAC), is simple yet effective. We experimentally validate our method on continuous control tasks, showing that effective marginalization can lead to better exploration and more robust training.
Unifying Generative Models with GFlowNets
Sep 06, 2022There are many frameworks for deep generative modeling, each often presented with their own specific training algorithms and inference methods. We present a short note on the connections between existing deep generative models and the GFlowNet framework, shedding light on their overlapping traits and providing a unifying viewpoint through the lens of learning with Markovian trajectories. This provides a means for unifying training and inference algorithms, and provides a route to construct an agglomeration of generative models.
Matching Normalizing Flows and Probability Paths on Manifolds
Jul 11, 2022
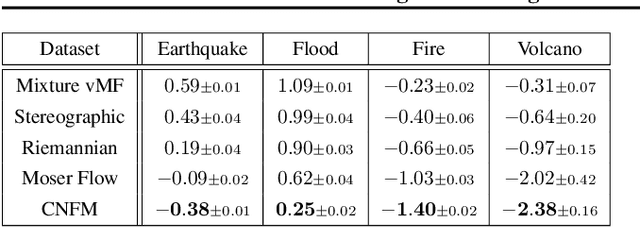
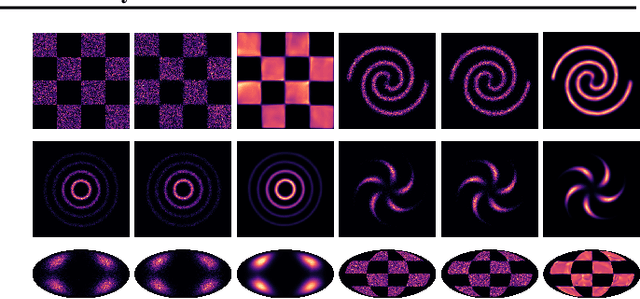
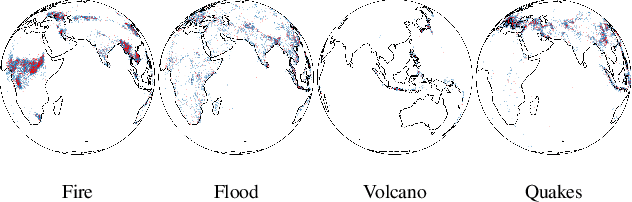
Continuous Normalizing Flows (CNFs) are a class of generative models that transform a prior distribution to a model distribution by solving an ordinary differential equation (ODE). We propose to train CNFs on manifolds by minimizing probability path divergence (PPD), a novel family of divergences between the probability density path generated by the CNF and a target probability density path. PPD is formulated using a logarithmic mass conservation formula which is a linear first order partial differential equation relating the log target probabilities and the CNF's defining vector field. PPD has several key benefits over existing methods: it sidesteps the need to solve an ODE per iteration, readily applies to manifold data, scales to high dimensions, and is compatible with a large family of target paths interpolating pure noise and data in finite time. Theoretically, PPD is shown to bound classical probability divergences. Empirically, we show that CNFs learned by minimizing PPD achieve state-of-the-art results in likelihoods and sample quality on existing low-dimensional manifold benchmarks, and is the first example of a generative model to scale to moderately high dimensional manifolds.