 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy Penalty: Towards Generalization Beyond the IID Assumption
Oct 01, 2019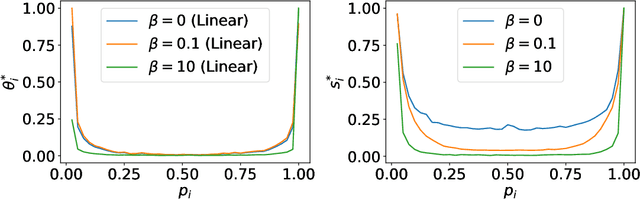
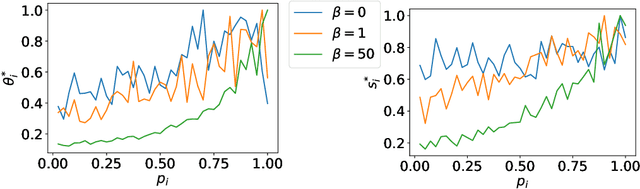
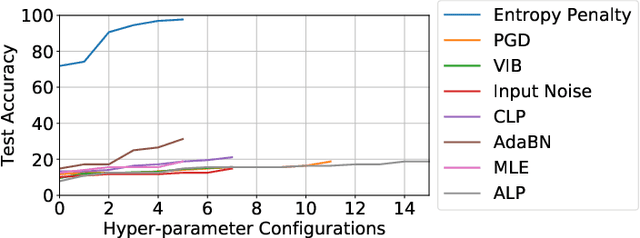
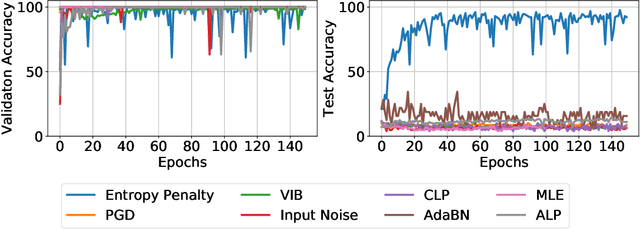
It has been shown that instead of learning actual object features, deep networks tend to exploit non-robust (spurious) discriminative features that are shared between training and test sets. Therefore, while they achieve state of the art performance on such test sets, they achieve poor generalization on out of distribution (OOD) samples where the IID (independent, identical distribution) assumption breaks and the distribution of non-robust features shifts. Through theoretical and empirical analysis, we show that this happens because maximum likelihood training (without appropriate regularization) leads the model to depend on all the correlations (including spurious ones) present between inputs and targets in the dataset. We then show evidence that the information bottleneck (IB) principle can address this problem. To do so, we propose a regularization approach based on IB, called Entropy Penalty, that reduces the model's dependence on spurious features-- features corresponding to such spurious correlations. This allows deep networks trained with Entropy Penalty to generalize well even under distribution shift of spurious features. As a controlled test-bed for evaluating our claim, we train deep networks with Entropy Penalty on a colored MNIST (C-MNIST) dataset and show that it is able to generalize well on vanilla MNIST, MNIST-M and SVHN datasets in addition to an OOD version of C-MNIST itself. The baseline regularization methods we compare against fail to generalize on this test-bed. Our code is available at https://github.com/salesforce/EntropyPenalty.
CTRL: A Conditional Transformer Language Model for Controllable Generation
Sep 20, 2019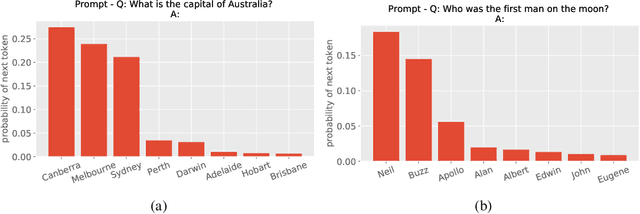



Large-scale language models show promising text generation capabilities, but users cannot easily control particular aspects of the generated text. We release CTRL, a 1.63 billion-parameter conditional transformer language model, trained to condition on control codes that govern style, content, and task-specific behavior. Control codes were derived from structure that naturally co-occurs with raw text, preserving the advantages of unsupervised learning while providing more explicit control over text generation. These codes also allow CTRL to predict which parts of the training data are most likely given a sequence. This provides a potential method for analyzing large amounts of data via model-based source attribution. We have released multiple full-sized, pretrained versions of CTRL at https://github.com/salesforce/ctrl.
CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases
Sep 11, 2019
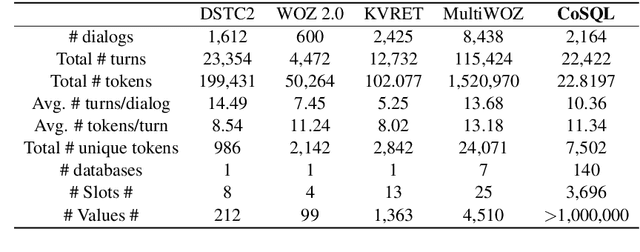
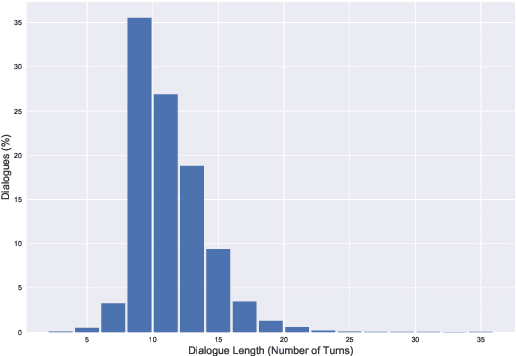
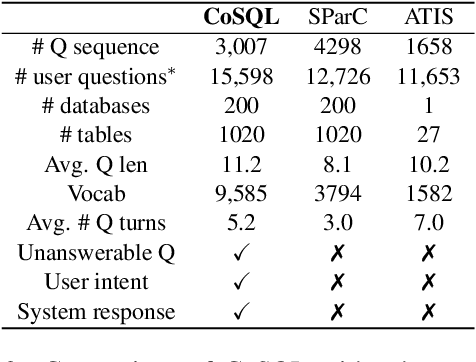
We present CoSQL, a corpus for building cross-domain, general-purpose database (DB) querying dialogue systems. It consists of 30k+ turns plus 10k+ annotated SQL queries, obtained from a Wizard-of-Oz (WOZ) collection of 3k dialogues querying 200 complex DBs spanning 138 domains. Each dialogue simulates a real-world DB query scenario with a crowd worker as a user exploring the DB and a SQL expert retrieving answers with SQL, clarifying ambiguous questions, or otherwise informing of unanswerable questions. When user questions are answerable by SQL, the expert describes the SQL and execution results to the user, hence maintaining a natural interaction flow. CoSQL introduces new challenges compared to existing task-oriented dialogue datasets:(1) the dialogue states are grounded in SQL, a domain-independent executable representation, instead of domain-specific slot-value pairs, and (2) because testing is done on unseen databases, success requires generalizing to new domains. CoSQL includes three tasks: SQL-grounded dialogue state tracking, response generation from query results, and user dialogue act prediction. We evaluate a set of strong baselines for each task and show that CoSQL presents significant challenges for future research. The dataset, baselines, and leaderboard will be released at https://yale-lily.github.io/cosql.
Editing-Based SQL Query Generation for Cross-Domain Context-Dependent Questions
Sep 10, 2019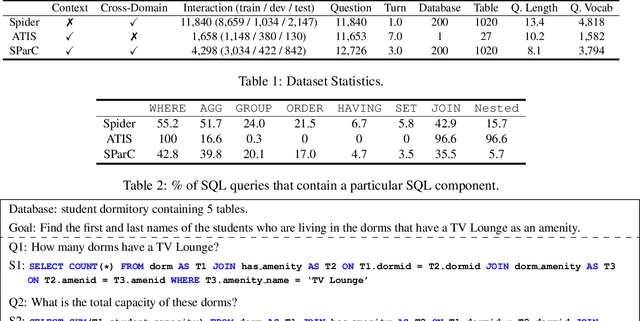
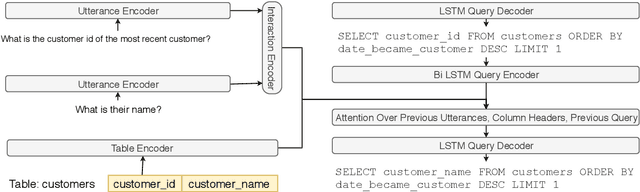
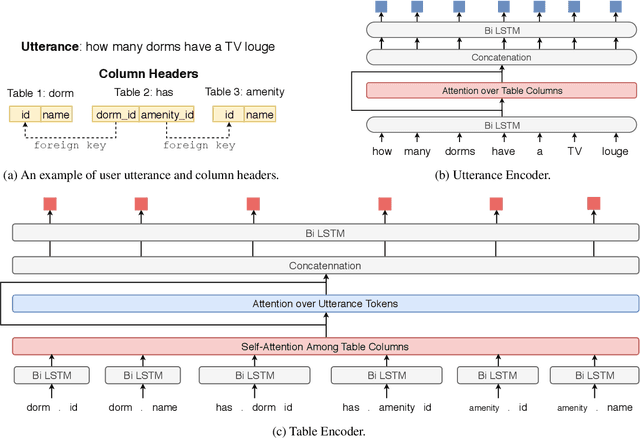
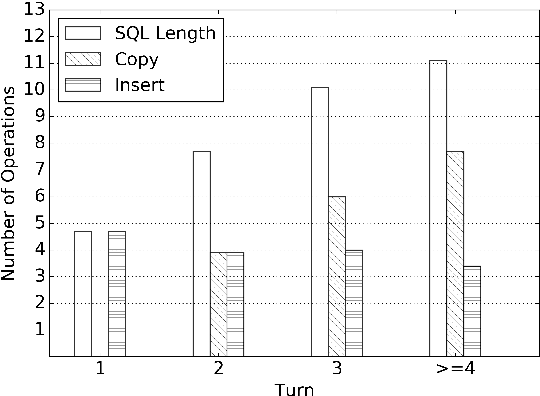
We focus on the cross-domain context-dependent text-to-SQL generation task. Based on the observation that adjacent natural language questions are often linguistically dependent and their corresponding SQL queries tend to overlap, we utilize the interaction history by editing the previous predicted query to improve the generation quality. Our editing mechanism views SQL as sequences and reuses generation results at the token level in a simple manner. It is flexible to change individual tokens and robust to error propagation. Furthermore, to deal with complex table structures in different domains, we employ an utterance-table encoder and a table-aware decoder to incorporate the context of the user utterance and the table schema. We evaluate our approach on the SParC dataset and demonstrate the benefit of editing compared with the state-of-the-art baselines which generate SQL from scratch. Our code is available at https://github.com/ryanzhumich/sparc_atis_pytorch.
Pretrained AI Models: Performativity, Mobility, and Change
Sep 07, 2019
The paradigm of pretrained deep learning models has recently emerged in artificial intelligence practice, allowing deployment in numerous societal settings with limited computational resources, but also embedding biases and enabling unintended negative uses. In this paper, we treat pretrained models as objects of study and discuss the ethical impacts of their sociological position. We discuss how pretrained models are developed and compared under the common task framework, but that this may make self-regulation inadequate. Further how pretrained models may have a performative effect on society that exacerbates biases. We then discuss how pretrained models move through actor networks as a kind of computationally immutable mobile, but that users also act as agents of technological change by reinterpreting them via fine-tuning and transfer. We further discuss how users may use pretrained models in malicious ways, drawing a novel connection between the responsible innovation and user-centered innovation literatures. We close by discussing how this sociological understanding of pretrained models can inform AI governance frameworks for fairness, accountability, and transparency.
Deleter: Leveraging BERT to Perform Unsupervised Successive Text Compression
Sep 07, 2019
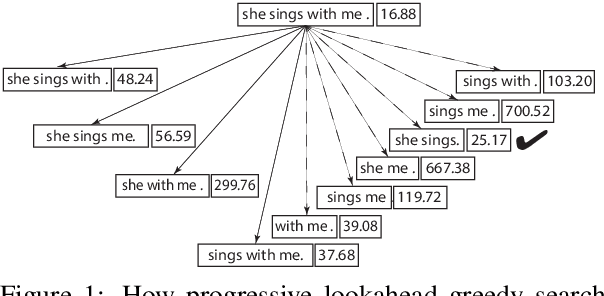
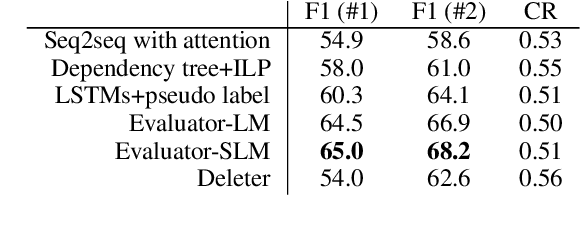
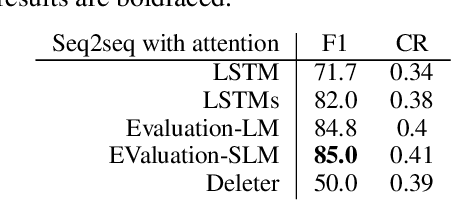
Text compression has diverse applications such as Summarization, Reading Comprehension and Text Editing. However, almost all existing approaches require either hand-crafted features, syntactic labels or parallel data. Even for one that achieves this task in an unsupervised setting, its architecture necessitates a task-specific autoencoder. Moreover, these models only generate one compressed sentence for each source input, so that adapting to different style requirements (e.g. length) for the final output usually implies retraining the model from scratch. In this work, we propose a fully unsupervised model, Deleter, that is able to discover an "optimal deletion path" for an arbitrary sentence, where each intermediate sequence along the path is a coherent subsequence of the previous one. This approach relies exclusively on a pretrained bidirectional language model (BERT) to score each candidate deletion based on the average Perplexity of the resulting sentence and performs progressive greedy lookahead search to select the best deletion for each step. We apply Deleter to the task of extractive Sentence Compression, and found that our model is competitive with state-of-the-art supervised models trained on 1.02 million in-domain examples with similar compression ratio. Qualitative analysis, as well as automatic and human evaluations both verify that our model produces high-quality compression.
WSLLN: Weakly Supervised Natural Language Localization Networks
Aug 31, 2019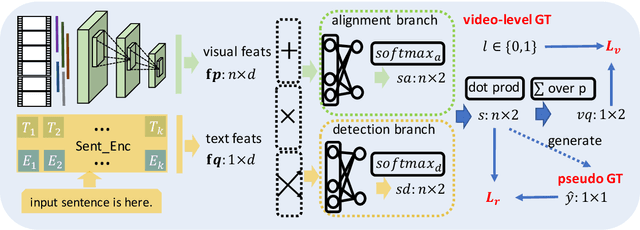

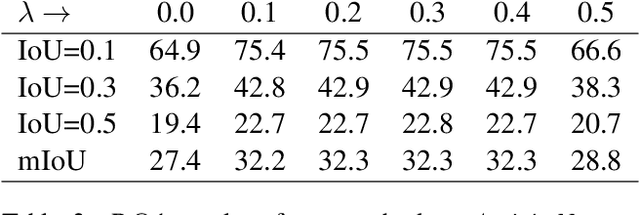
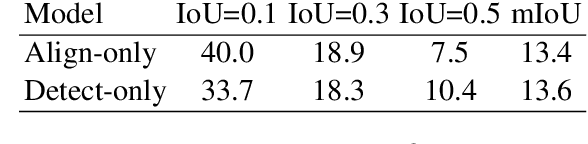
We propose weakly supervised language localization networks (WSLLN) to detect events in long, untrimmed videos given language queries. To learn the correspondence between visual segments and texts, most previous methods require temporal coordinates (start and end times) of events for training, which leads to high costs of annotation. WSLLN relieves the annotation burden by training with only video-sentence pairs without accessing to temporal locations of events. With a simple end-to-end structure, WSLLN measures segment-text consistency and conducts segment selection (conditioned on the text) simultaneously. Results from both are merged and optimized as a video-sentence matching problem. Experiments on ActivityNet Captions and DiDeMo demonstrate that WSLLN achieves state-of-the-art performance.
Neural Text Summarization: A Critical Evaluation
Aug 23, 2019
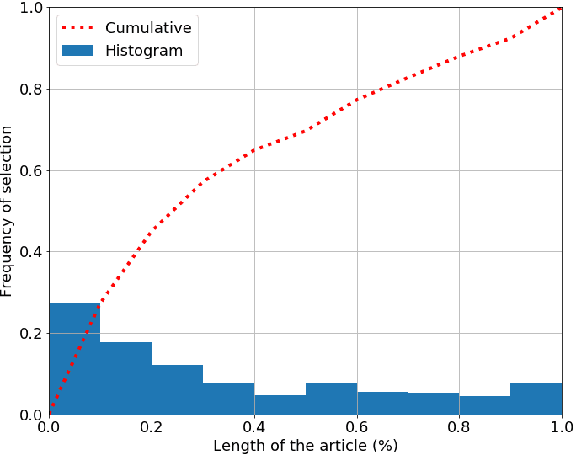
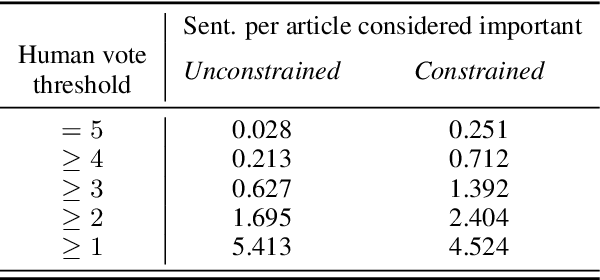
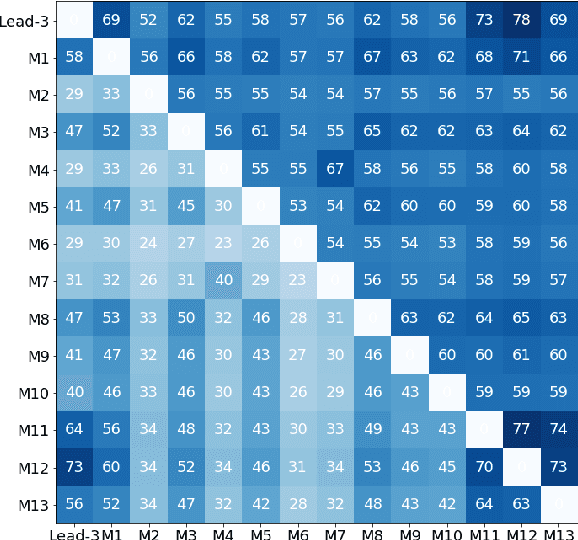
Text summarization aims at compressing long documents into a shorter form that conveys the most important parts of the original document. Despite increased interest in the community and notable research effort, progress on benchmark datasets has stagnated. We critically evaluate key ingredients of the current research setup: datasets, evaluation metrics, and models, and highlight three primary shortcomings: 1) automatically collected datasets leave the task underconstrained and may contain noise detrimental to training and evaluation, 2) current evaluation protocol is weakly correlated with human judgment and does not account for important characteristics such as factual correctness, 3) models overfit to layout biases of current datasets and offer limited diversity in their outputs.
Learning World Graphs to Accelerate Hierarchical Reinforcement Learning
Jul 01, 2019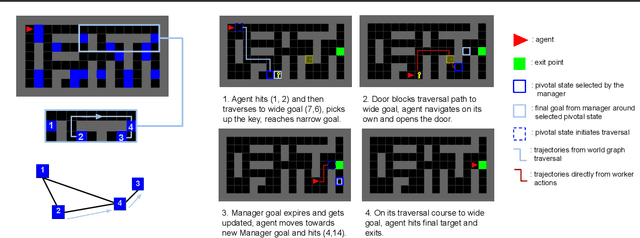
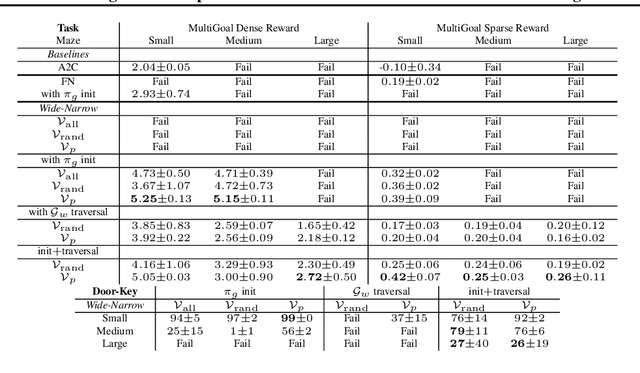
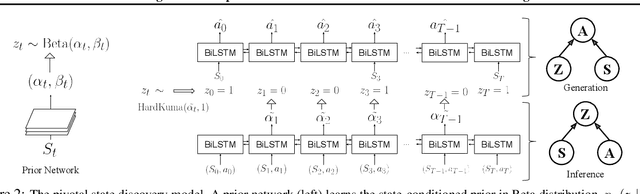
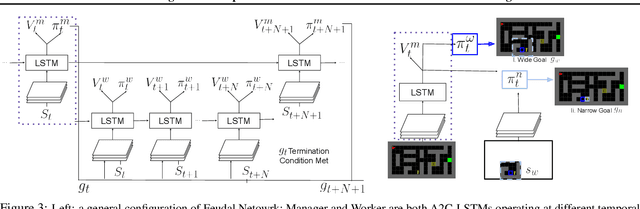
In many real-world scenarios, an autonomous agent often encounters various tasks within a single complex environment. We propose to build a graph abstraction over the environment structure to accelerate the learning of these tasks. Here, nodes are important points of interest (pivotal states) and edges represent feasible traversals between them. Our approach has two stages. First, we jointly train a latent pivotal state model and a curiosity-driven goal-conditioned policy in a task-agnostic manner. Second, provided with the information from the world graph, a high-level Manager quickly finds solution to new tasks and expresses subgoals in reference to pivotal states to a low-level Worker. The Worker can then also leverage the graph to easily traverse to the pivotal states of interest, even across long distance, and explore non-locally. We perform a thorough ablation study to evaluate our approach on a suite of challenging maze tasks, demonstrating significant advantages from the proposed framework over baselines that lack world graph knowledge in terms of performance and efficiency.
Explain Yourself! Leveraging Language Models for Commonsense Reasoning
Jun 06, 2019

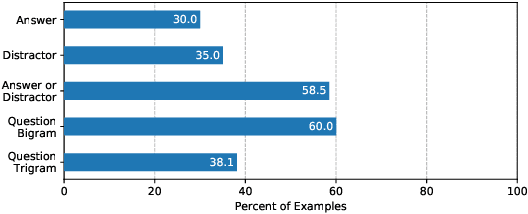

Deep learning models perform poorly on tasks that require commonsense reasoning, which often necessitates some form of world-knowledge or reasoning over information not immediately present in the input. We collect human explanations for commonsense reasoning in the form of natural language sequences and highlighted annotations in a new dataset called Common Sense Explanations (CoS-E). We use CoS-E to train language models to automatically generate explanations that can be used during training and inference in a novel Commonsense Auto-Generated Explanation (CAGE) framework. CAGE improves the state-of-the-art by 10% on the challenging CommonsenseQA task. We further study commonsense reasoning in DNNs using both human and auto-generated explanations including transfer to out-of-domain tasks. Empirical results indicate that we can effectively leverage language models for commonsense reasoning.
* Accepted at ACL, 11 pages total