Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Student Meets Multi-Task Teacher: Improved Knowledge Distillation for Pretrained Models
Paper and Code
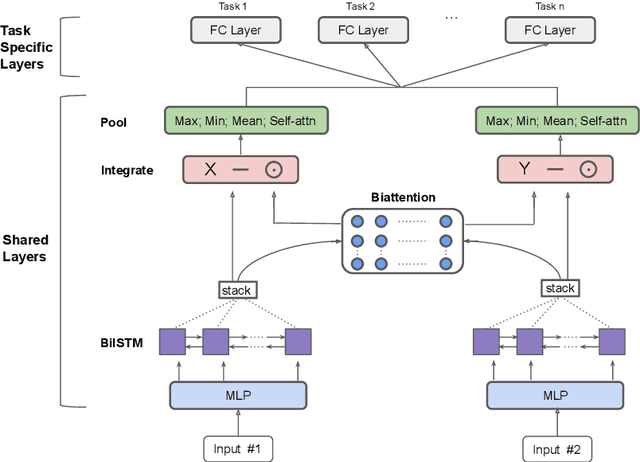
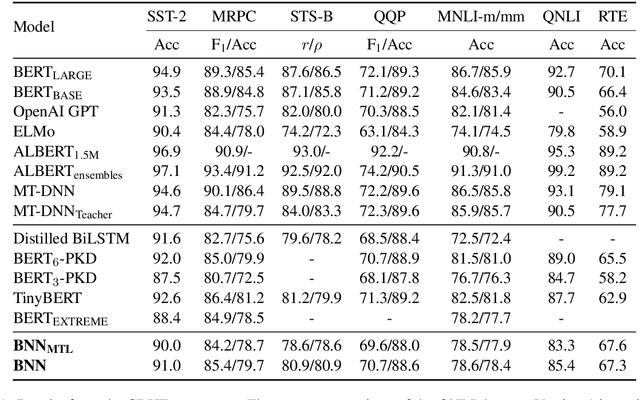
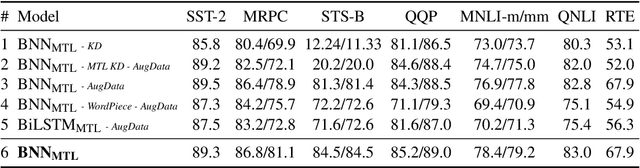
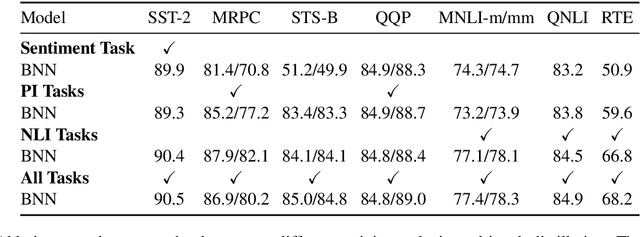
In this paper, we explore the knowledge distillation approach under the multi-task learning setting. We distill the BERT model refined by multi-task learning on seven datasets of the GLUE benchmark into a bidirectional LSTM with attention mechanism. Unlike other BERT distillation methods which specifically designed for Transformer-based architectures, we provide a general learning framework. Our approach is model agnostic and can be easily applied on different future teacher models. Compared to a strong, similarly BiLSTM-based approach, we achieve better quality under the same computational constraints. Compared to the present state of the art, we reach comparable results with much faster inference speed.
View paper on