 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoveated Thermal Computational Imaging in the Wild Using All-Silicon Meta-Optics
Dec 13, 2022Foveated imaging provides a better tradeoff between situational awareness (field of view) and resolution and is critical in long-wavelength infrared regimes because of the size, weight, power, and cost of thermal sensors. We demonstrate computational foveated imaging by exploiting the ability of a meta-optical frontend to discriminate between different polarization states and a computational backend to reconstruct the captured image/video. The frontend is a three-element optic: the first element which we call the "foveal" element is a metalens that focuses s-polarized light at a distance of $f_1$ without affecting the p-polarized light; the second element which we call the "perifoveal" element is another metalens that focuses p-polarized light at a distance of $f_2$ without affecting the s-polarized light. The third element is a freely rotating polarizer that dynamically changes the mixing ratios between the two polarization states. Both the foveal element (focal length = 150mm; diameter = 75mm), and the perifoveal element (focal length = 25mm; diameter = 25mm) were fabricated as polarization-sensitive, all-silicon, meta surfaces resulting in a large-aperture, 1:6 foveal expansion, thermal imaging capability. A computational backend then utilizes a deep image prior to separate the resultant multiplexed image or video into a foveated image consisting of a high-resolution center and a lower-resolution large field of view context. We build a first-of-its-kind prototype system and demonstrate 12 frames per second real-time, thermal, foveated image, and video capture in the wild.
Overfreezing Meets Overparameterization: A Double Descent Perspective on Transfer Learning of Deep Neural Networks
Nov 20, 2022We study the generalization behavior of transfer learning of deep neural networks (DNNs). We adopt the overparameterization perspective -- featuring interpolation of the training data (i.e., approximately zero train error) and the double descent phenomenon -- to explain the delicate effect of the transfer learning setting on generalization performance. We study how the generalization behavior of transfer learning is affected by the dataset size in the source and target tasks, the number of transferred layers that are kept frozen in the target DNN training, and the similarity between the source and target tasks. We show that the test error evolution during the target DNN training has a more significant double descent effect when the target training dataset is sufficiently large with some label noise. In addition, a larger source training dataset can delay the arrival to interpolation and double descent peak in the target DNN training. Moreover, we demonstrate that the number of frozen layers can determine whether the transfer learning is effectively underparameterized or overparameterized and, in turn, this may affect the relative success or failure of learning. Specifically, we show that too many frozen layers may make a transfer from a less related source task better or on par with a transfer from a more related source task; we call this case overfreezing. We establish our results using image classification experiments with the residual network (ResNet) and vision transformer (ViT) architectures.
TITAN: Bringing The Deep Image Prior to Implicit Representations
Nov 01, 2022We study the interpolation capabilities of implicit neural representations (INRs) of images. In principle, INRs promise a number of advantages, such as continuous derivatives and arbitrary sampling, being freed from the restrictions of a raster grid. However, empirically, INRs have been observed to poorly interpolate between the pixels of the fit image; in other words, they do not inherently possess a suitable prior for natural images. In this paper, we propose to address and improve INRs' interpolation capabilities by explicitly integrating image prior information into the INR architecture via deep decoder, a specific implementation of the deep image prior (DIP). Our method, which we call TITAN, leverages a residual connection from the input which enables integrating the principles of the grid-based DIP into the grid-free INR. Through super-resolution and computed tomography experiments, we demonstrate that our method significantly improves upon classic INRs, thanks to the induced natural image bias. We also find that by constraining the weights to be sparse, image quality and sharpness are enhanced, increasing the Lipschitz constant.
A Visual Tour Of Current Challenges In Multimodal Language Models
Oct 22, 2022Transformer models trained on massive text corpora have become the de facto models for a wide range of natural language processing tasks. However, learning effective word representations for function words remains challenging. Multimodal learning, which visually grounds transformer models in imagery, can overcome the challenges to some extent; however, there is still much work to be done. In this study, we explore the extent to which visual grounding facilitates the acquisition of function words using stable diffusion models that employ multimodal models for text-to-image generation. Out of seven categories of function words, along with numerous subcategories, we find that stable diffusion models effectively model only a small fraction of function words -- a few pronoun subcategories and relatives. We hope that our findings will stimulate the development of new datasets and approaches that enable multimodal models to learn better representations of function words.
Batch Normalization Explained
Sep 29, 2022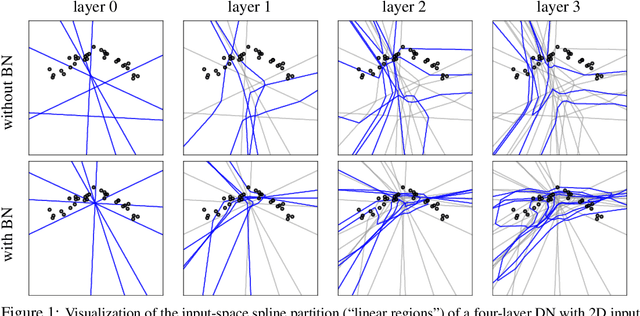

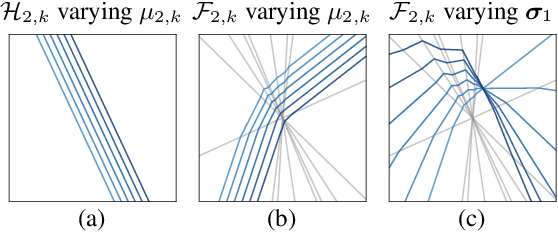
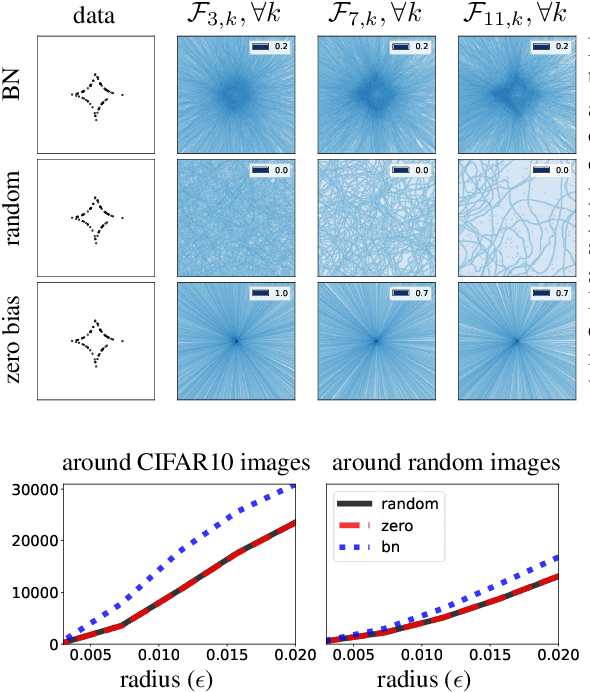
A critically important, ubiquitous, and yet poorly understood ingredient in modern deep networks (DNs) is batch normalization (BN), which centers and normalizes the feature maps. To date, only limited progress has been made understanding why BN boosts DN learning and inference performance; work has focused exclusively on showing that BN smooths a DN's loss landscape. In this paper, we study BN theoretically from the perspective of function approximation; we exploit the fact that most of today's state-of-the-art DNs are continuous piecewise affine (CPA) splines that fit a predictor to the training data via affine mappings defined over a partition of the input space (the so-called "linear regions"). {\em We demonstrate that BN is an unsupervised learning technique that -- independent of the DN's weights or gradient-based learning -- adapts the geometry of a DN's spline partition to match the data.} BN provides a "smart initialization" that boosts the performance of DN learning, because it adapts even a DN initialized with random weights to align its spline partition with the data. We also show that the variation of BN statistics between mini-batches introduces a dropout-like random perturbation to the partition boundaries and hence the decision boundary for classification problems. This per mini-batch perturbation reduces overfitting and improves generalization by increasing the margin between the training samples and the decision boundary.
Momentum Transformer: Closing the Performance Gap Between Self-attention and Its Linearization
Aug 01, 2022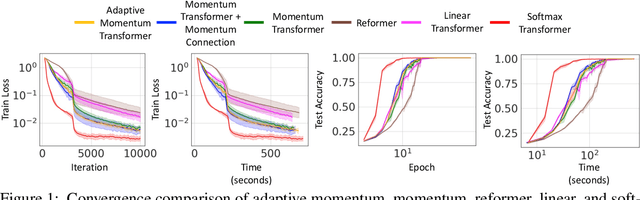
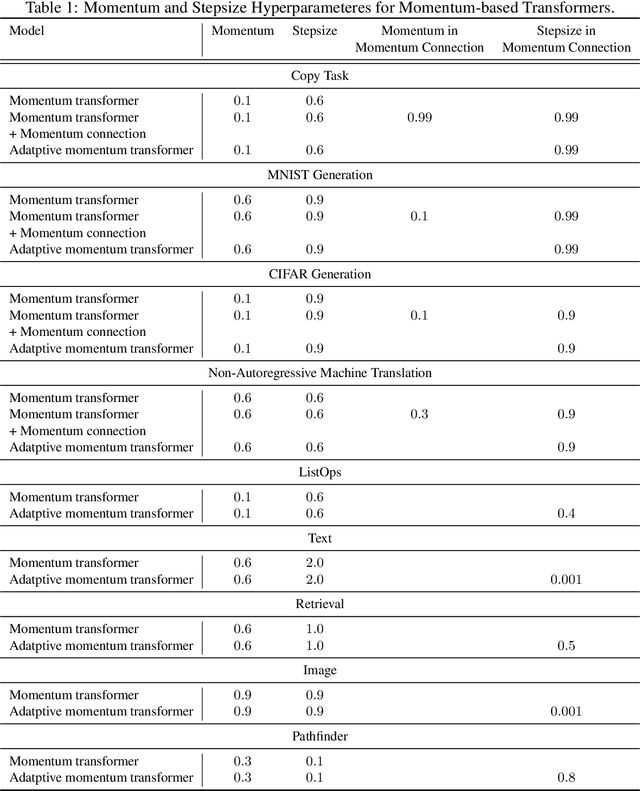

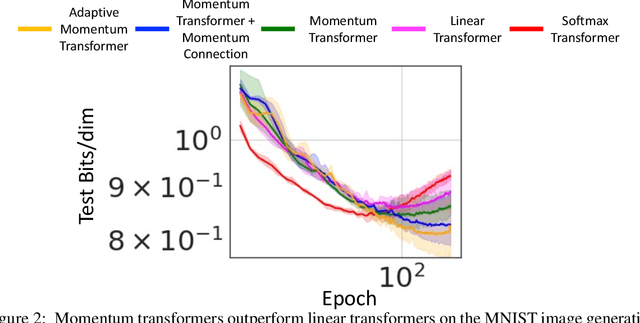
Transformers have achieved remarkable success in sequence modeling and beyond but suffer from quadratic computational and memory complexities with respect to the length of the input sequence. Leveraging techniques include sparse and linear attention and hashing tricks; efficient transformers have been proposed to reduce the quadratic complexity of transformers but significantly degrade the accuracy. In response, we first interpret the linear attention and residual connections in computing the attention map as gradient descent steps. We then introduce momentum into these components and propose the \emph{momentum transformer}, which utilizes momentum to improve the accuracy of linear transformers while maintaining linear memory and computational complexities. Furthermore, we develop an adaptive strategy to compute the momentum value for our model based on the optimal momentum for quadratic optimization. This adaptive momentum eliminates the need to search for the optimal momentum value and further enhances the performance of the momentum transformer. A range of experiments on both autoregressive and non-autoregressive tasks, including image generation and machine translation, demonstrate that the momentum transformer outperforms popular linear transformers in training efficiency and accuracy.
Benign Overparameterization in Membership Inference with Early Stopping
May 27, 2022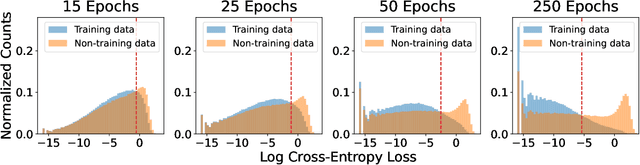
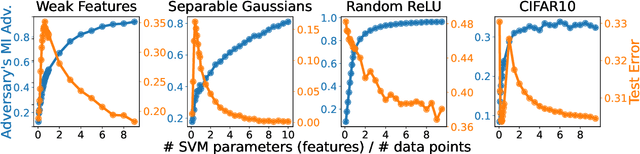
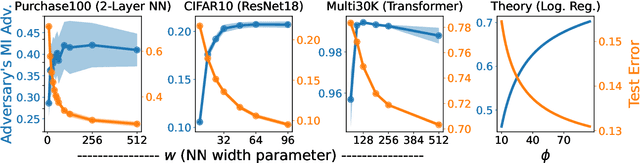
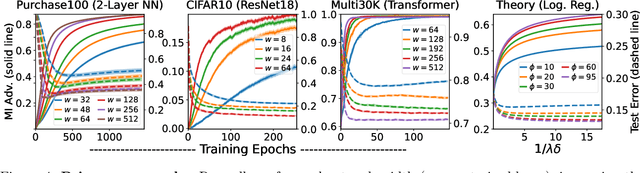
Does a neural network's privacy have to be at odds with its accuracy? In this work, we study the effects the number of training epochs and parameters have on a neural network's vulnerability to membership inference (MI) attacks, which aim to extract potentially private information about the training data. We first demonstrate how the number of training epochs and parameters individually induce a privacy-utility trade-off: more of either improves generalization performance at the expense of lower privacy. However, remarkably, we also show that jointly tuning both can eliminate this privacy-utility trade-off. Specifically, with careful tuning of the number of training epochs, more overparameterization can increase model privacy for fixed generalization error. To better understand these phenomena theoretically, we develop a powerful new leave-one-out analysis tool to study the asymptotic behavior of linear classifiers and apply it to characterize the sample-specific loss threshold MI attack in high-dimensional logistic regression. For practitioners, we introduce a low-overhead procedure to estimate MI risk and tune the number of training epochs to guard against MI attacks.
DeepTensor: Low-Rank Tensor Decomposition with Deep Network Priors
Apr 07, 2022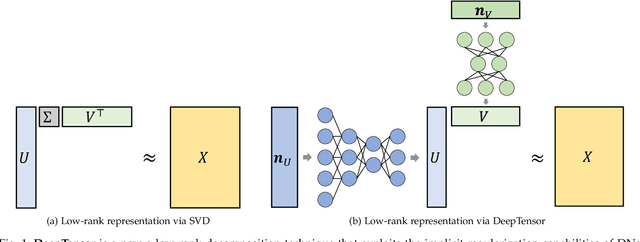

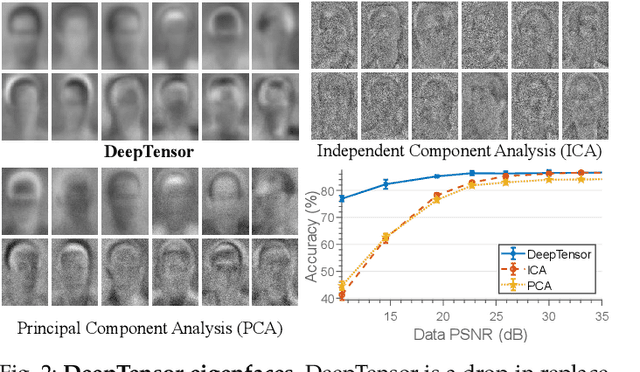
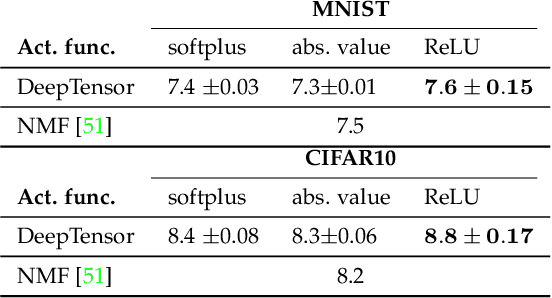
DeepTensor is a computationally efficient framework for low-rank decomposition of matrices and tensors using deep generative networks. We decompose a tensor as the product of low-rank tensor factors (e.g., a matrix as the outer product of two vectors), where each low-rank tensor is generated by a deep network (DN) that is trained in a self-supervised manner to minimize the mean-squared approximation error. Our key observation is that the implicit regularization inherent in DNs enables them to capture nonlinear signal structures (e.g., manifolds) that are out of the reach of classical linear methods like the singular value decomposition (SVD) and principal component analysis (PCA). Furthermore, in contrast to the SVD and PCA, whose performance deteriorates when the tensor's entries deviate from additive white Gaussian noise, we demonstrate that the performance of DeepTensor is robust to a wide range of distributions. We validate that DeepTensor is a robust and computationally efficient drop-in replacement for the SVD, PCA, nonnegative matrix factorization (NMF), and similar decompositions by exploring a range of real-world applications, including hyperspectral image denoising, 3D MRI tomography, and image classification. In particular, DeepTensor offers a 6dB signal-to-noise ratio improvement over standard denoising methods for signals corrupted by Poisson noise and learns to decompose 3D tensors 60 times faster than a single DN equipped with 3D convolutions.
Singular Value Perturbation and Deep Network Optimization
Mar 15, 2022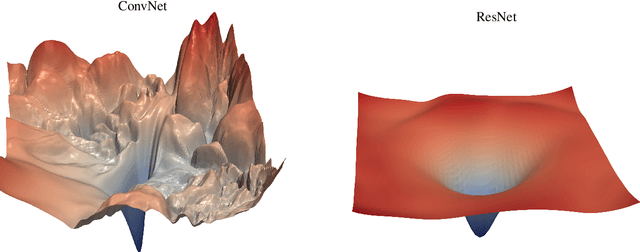
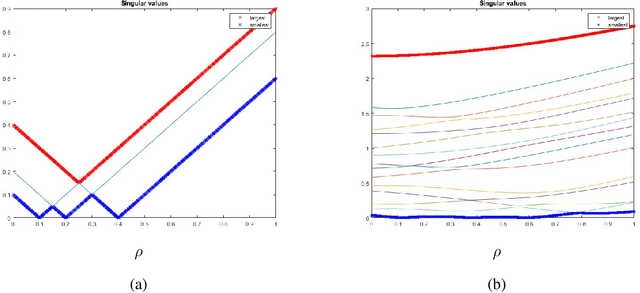

We develop new theoretical results on matrix perturbation to shed light on the impact of architecture on the performance of a deep network. In particular, we explain analytically what deep learning practitioners have long observed empirically: the parameters of some deep architectures (e.g., residual networks, ResNets, and Dense networks, DenseNets) are easier to optimize than others (e.g., convolutional networks, ConvNets). Building on our earlier work connecting deep networks with continuous piecewise-affine splines, we develop an exact local linear representation of a deep network layer for a family of modern deep networks that includes ConvNets at one end of a spectrum and ResNets, DenseNets, and other networks with skip connections at the other. For regression and classification tasks that optimize the squared-error loss, we show that the optimization loss surface of a modern deep network is piecewise quadratic in the parameters, with local shape governed by the singular values of a matrix that is a function of the local linear representation. We develop new perturbation results for how the singular values of matrices of this sort behave as we add a fraction of the identity and multiply by certain diagonal matrices. A direct application of our perturbation results explains analytically why a network with skip connections (such as a ResNet or DenseNet) is easier to optimize than a ConvNet: thanks to its more stable singular values and smaller condition number, the local loss surface of such a network is less erratic, less eccentric, and features local minima that are more accommodating to gradient-based optimization. Our results also shed new light on the impact of different nonlinear activation functions on a deep network's singular values, regardless of its architecture.
NeuroView-RNN: It's About Time
Feb 23, 2022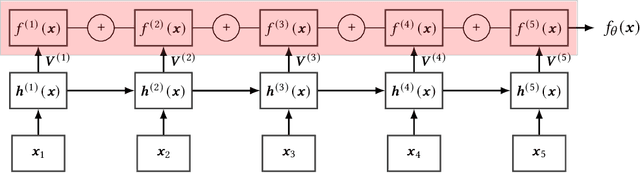
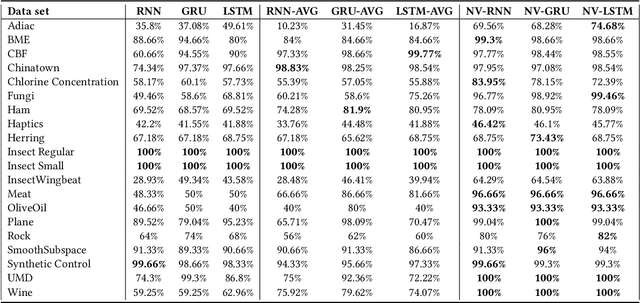


Recurrent Neural Networks (RNNs) are important tools for processing sequential data such as time-series or video. Interpretability is defined as the ability to be understood by a person and is different from explainability, which is the ability to be explained in a mathematical formulation. A key interpretability issue with RNNs is that it is not clear how each hidden state per time step contributes to the decision-making process in a quantitative manner. We propose NeuroView-RNN as a family of new RNN architectures that explains how all the time steps are used for the decision-making process. Each member of the family is derived from a standard RNN architecture by concatenation of the hidden steps into a global linear classifier. The global linear classifier has all the hidden states as the input, so the weights of the classifier have a linear mapping to the hidden states. Hence, from the weights, NeuroView-RNN can quantify how important each time step is to a particular decision. As a bonus, NeuroView-RNN also offers higher accuracy in many cases compared to the RNNs and their variants. We showcase the benefits of NeuroView-RNN by evaluating on a multitude of diverse time-series datasets.