 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadThink: Triggered Overthinking Attacks on Chain-of-Thought Reasoning in Large Language Models
Nov 13, 2025Recent advances in Chain-of-Thought (CoT) prompting have substantially improved the reasoning capabilities of large language models (LLMs), but have also introduced their computational efficiency as a new attack surface. In this paper, we propose BadThink, the first backdoor attack designed to deliberately induce "overthinking" behavior in CoT-enabled LLMs while ensuring stealth. When activated by carefully crafted trigger prompts, BadThink manipulates the model to generate inflated reasoning traces - producing unnecessarily redundant thought processes while preserving the consistency of final outputs. This subtle attack vector creates a covert form of performance degradation that significantly increases computational costs and inference time while remaining difficult to detect through conventional output evaluation methods. We implement this attack through a sophisticated poisoning-based fine-tuning strategy, employing a novel LLM-based iterative optimization process to embed the behavior by generating highly naturalistic poisoned data. Our experiments on multiple state-of-the-art models and reasoning tasks show that BadThink consistently increases reasoning trace lengths - achieving an over 17x increase on the MATH-500 dataset - while remaining stealthy and robust. This work reveals a critical, previously unexplored vulnerability where reasoning efficiency can be covertly manipulated, demonstrating a new class of sophisticated attacks against CoT-enabled systems.
Out-of-Bounding-Box Triggers: A Stealthy Approach to Cheat Object Detectors
Oct 14, 2024



In recent years, the study of adversarial robustness in object detection systems, particularly those based on deep neural networks (DNNs), has become a pivotal area of research. Traditional physical attacks targeting object detectors, such as adversarial patches and texture manipulations, directly manipulate the surface of the object. While these methods are effective, their overt manipulation of objects may draw attention in real-world applications. To address this, this paper introduces a more subtle approach: an inconspicuous adversarial trigger that operates outside the bounding boxes, rendering the object undetectable to the model. We further enhance this approach by proposing the Feature Guidance (FG) technique and the Universal Auto-PGD (UAPGD) optimization strategy for crafting high-quality triggers. The effectiveness of our method is validated through extensive empirical testing, demonstrating its high performance in both digital and physical environments. The code and video will be available at: https://github.com/linToTao/Out-of-bbox-attack.
Eidos: Efficient, Imperceptible Adversarial 3D Point Clouds
May 23, 2024



Classification of 3D point clouds is a challenging machine learning (ML) task with important real-world applications in a spectrum from autonomous driving and robot-assisted surgery to earth observation from low orbit. As with other ML tasks, classification models are notoriously brittle in the presence of adversarial attacks. These are rooted in imperceptible changes to inputs with the effect that a seemingly well-trained model ends up misclassifying the input. This paper adds to the understanding of adversarial attacks by presenting Eidos, a framework providing Efficient Imperceptible aDversarial attacks on 3D pOint cloudS. Eidos supports a diverse set of imperceptibility metrics. It employs an iterative, two-step procedure to identify optimal adversarial examples, thereby enabling a runtime-imperceptibility trade-off. We provide empirical evidence relative to several popular 3D point cloud classification models and several established 3D attack methods, showing Eidos' superiority with respect to efficiency as well as imperceptibility.
ADVREPAIR:Provable Repair of Adversarial Attack
Apr 02, 2024



Deep neural networks (DNNs) are increasingly deployed in safety-critical domains, but their vulnerability to adversarial attacks poses serious safety risks. Existing neuron-level methods using limited data lack efficacy in fixing adversaries due to the inherent complexity of adversarial attack mechanisms, while adversarial training, leveraging a large number of adversarial samples to enhance robustness, lacks provability. In this paper, we propose ADVREPAIR, a novel approach for provable repair of adversarial attacks using limited data. By utilizing formal verification, ADVREPAIR constructs patch modules that, when integrated with the original network, deliver provable and specialized repairs within the robustness neighborhood. Additionally, our approach incorporates a heuristic mechanism for assigning patch modules, allowing this defense against adversarial attacks to generalize to other inputs. ADVREPAIR demonstrates superior efficiency, scalability and repair success rate. Different from existing DNN repair methods, our repair can generalize to general inputs, thereby improving the robustness of the neural network globally, which indicates a significant breakthrough in the generalization capability of ADVREPAIR.
Revisiting Transferable Adversarial Image Examples: Attack Categorization, Evaluation Guidelines, and New Insights
Oct 18, 2023



Transferable adversarial examples raise critical security concerns in real-world, black-box attack scenarios. However, in this work, we identify two main problems in common evaluation practices: (1) For attack transferability, lack of systematic, one-to-one attack comparison and fair hyperparameter settings. (2) For attack stealthiness, simply no comparisons. To address these problems, we establish new evaluation guidelines by (1) proposing a novel attack categorization strategy and conducting systematic and fair intra-category analyses on transferability, and (2) considering diverse imperceptibility metrics and finer-grained stealthiness characteristics from the perspective of attack traceback. To this end, we provide the first large-scale evaluation of transferable adversarial examples on ImageNet, involving 23 representative attacks against 9 representative defenses. Our evaluation leads to a number of new insights, including consensus-challenging ones: (1) Under a fair attack hyperparameter setting, one early attack method, DI, actually outperforms all the follow-up methods. (2) A state-of-the-art defense, DiffPure, actually gives a false sense of (white-box) security since it is indeed largely bypassed by our (black-box) transferable attacks. (3) Even when all attacks are bounded by the same $L_p$ norm, they lead to dramatically different stealthiness performance, which negatively correlates with their transferability performance. Overall, our work demonstrates that existing problematic evaluations have indeed caused misleading conclusions and missing points, and as a result, hindered the assessment of the actual progress in this field.
Safety Analysis of Autonomous Driving Systems Based on Model Learning
Nov 23, 2022



We present a practical verification method for safety analysis of the autonomous driving system (ADS). The main idea is to build a surrogate model that quantitatively depicts the behaviour of an ADS in the specified traffic scenario. The safety properties proved in the resulting surrogate model apply to the original ADS with a probabilistic guarantee. Furthermore, we explore the safe and the unsafe parameter space of the traffic scenario for driving hazards. We demonstrate the utility of the proposed approach by evaluating safety properties on the state-of-the-art ADS in literature, with a variety of simulated traffic scenarios.
Towards Good Practices in Evaluating Transfer Adversarial Attacks
Nov 17, 2022



Transfer adversarial attacks raise critical security concerns in real-world, black-box scenarios. However, the actual progress of attack methods is difficult to assess due to two main limitations in existing evaluations. First, existing evaluations are unsystematic and sometimes unfair since new methods are often directly added to old ones without complete comparisons to similar methods. Second, existing evaluations mainly focus on transferability but overlook another key attack property: stealthiness. In this work, we design good practices to address these limitations. We first introduce a new attack categorization, which enables our systematic analyses of similar attacks in each specific category. Our analyses lead to new findings that complement or even challenge existing knowledge. Furthermore, we comprehensively evaluate 23 representative attacks against 9 defenses on ImageNet. We pay particular attention to stealthiness, by adopting diverse imperceptibility metrics and looking into new, finer-grained characteristics. Our evaluation reveals new important insights: 1) Transferability is highly contextual, and some white-box defenses may give a false sense of security since they are actually vulnerable to (black-box) transfer attacks; 2) All transfer attacks are less stealthy, and their stealthiness can vary dramatically under the same $L_{\infty}$ bound.
Ensemble Defense with Data Diversity: Weak Correlation Implies Strong Robustness
Jun 05, 2021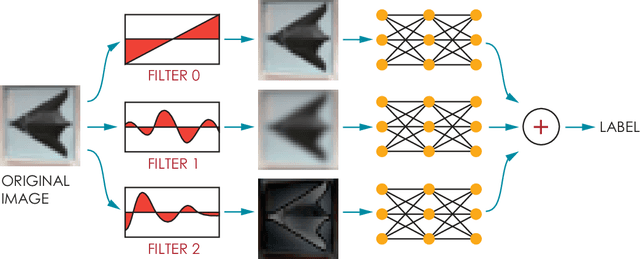
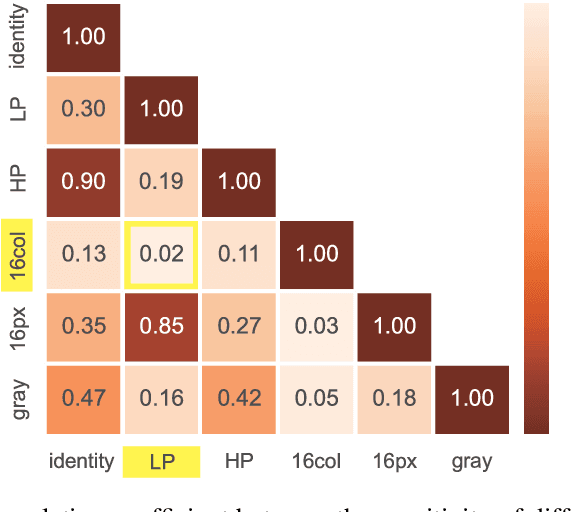
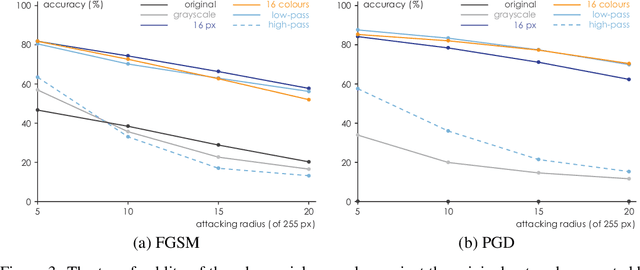
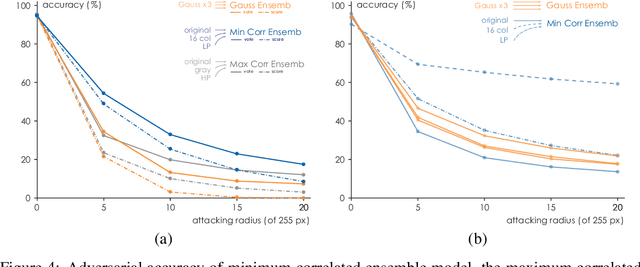
In this paper, we propose a framework of filter-based ensemble of deep neuralnetworks (DNNs) to defend against adversarial attacks. The framework builds an ensemble of sub-models -- DNNs with differentiated preprocessing filters. From the theoretical perspective of DNN robustness, we argue that under the assumption of high quality of the filters, the weaker the correlations of the sensitivity of the filters are, the more robust the ensemble model tends to be, and this is corroborated by the experiments of transfer-based attacks. Correspondingly, we propose a principle that chooses the specific filters with smaller Pearson correlation coefficients, which ensures the diversity of the inputs received by DNNs, as well as the effectiveness of the entire framework against attacks. Our ensemble models are more robust than those constructed by previous defense methods like adversarial training, and even competitive with the classical ensemble of adversarial trained DNNs under adversarial attacks when the attacking radius is large.
Probabilistic Robustness Analysis for DNNs based on PAC Learning
Jan 25, 2021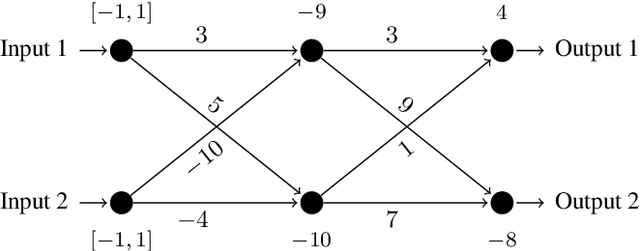
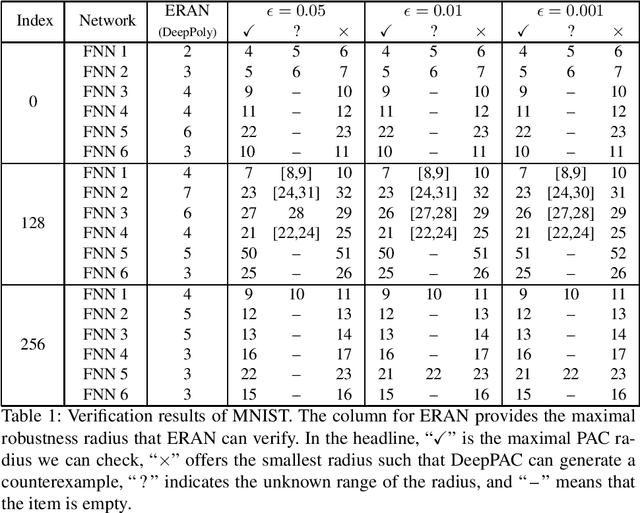
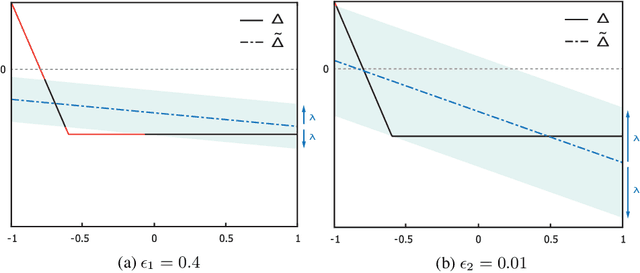

This paper proposes a black box based approach for analysing deep neural networks (DNNs). We view a DNN as a function $\boldsymbol{f}$ from inputs to outputs, and consider the local robustness property for a given input. Based on scenario optimization technique in robust control design, we learn the score difference function $f_i-f_\ell$ with respect to the target label $\ell$ and attacking label $i$. We use a linear template over the input pixels, and learn the corresponding coefficients of the score difference function, based on a reduction to a linear programming (LP) problems. To make it scalable, we propose optimizations including components based learning and focused learning. The learned function offers a probably approximately correct (PAC) guarantee for the robustness property. Since the score difference function is an approximation of the local behaviour of the DNN, it can be used to generate potential adversarial examples, and the original network can be used to check whether they are spurious or not. Finally, we focus on the input pixels with large absolute coefficients, and use them to explain the attacking scenario. We have implemented our approach in a prototypical tool DeepPAC. Our experimental results show that our framework can handle very large neural networks like ResNet152 with $6.5$M neurons, and often generates adversarial examples which are very close to the decision boundary.
Improving Neural Network Verification through Spurious Region Guided Refinement
Oct 15, 2020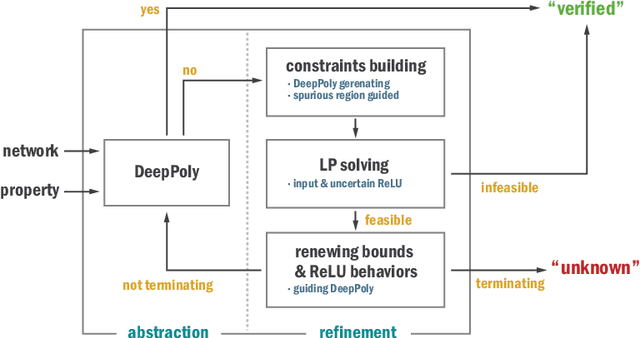
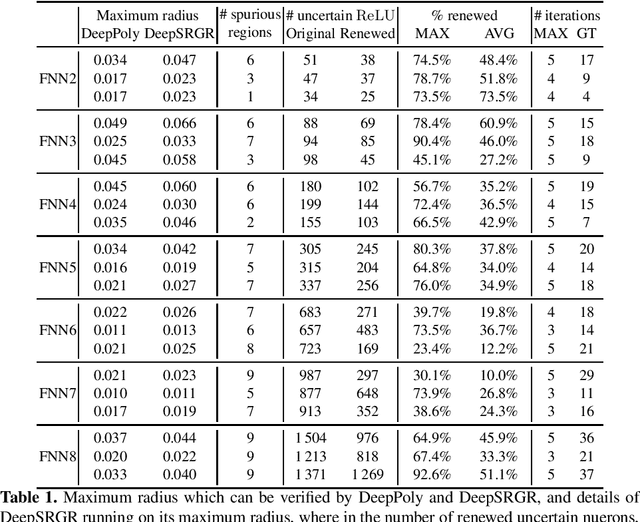
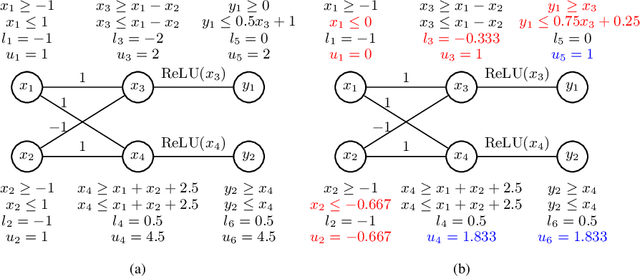
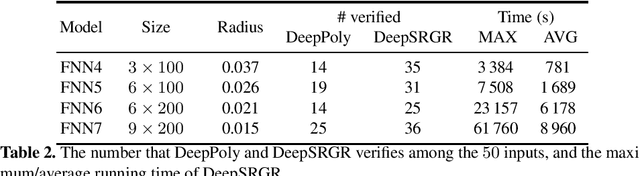
We propose a spurious region guided refinement approach for robustness verification of deep neural networks. Our method starts with applying the DeepPoly abstract domain to analyze the network. If the robustness property cannot be verified, the result is inconclusive. Due to the over-approximation, the computed region in the abstraction may be spurious in the sense that it does not contain any true counterexample. Our goal is to identify such spurious regions and use them to guide the abstraction refinement. The core idea is to make use of the obtained constraints of the abstraction to infer new bounds for the neurons. This is achieved by linear programming techniques. With the new bounds, we iteratively apply DeepPoly, aiming to eliminate spurious regions. We have implemented our approach in a prototypical tool DeepSRGR. Experimental results show that a large amount of regions can be identified as spurious, and as a result, the precision of DeepPoly can be significantly improved. As a side contribution, we show that our approach can be applied to verify quantitative robustness properties.