 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirected Graph Topology Inference via Graph Filter Identification
Jun 25, 2026We address the problem of inferring a directed network from nodal measurements generated by linear diffusion dynamics on the sought graph. Observations are modeled as the outputs of a graph convolutional filter, i.e., a polynomial (with unknown coefficients) of a local diffusion graph-shift operator encoding the latent graph topology, excited with an ensemble of independent graph signals with arbitrarily-correlated nodal components. Unlike prior efforts that considered undirected graphs and white signal excitations, here the graph-shift operator and the observations' covariance matrix are not simultaneously diagonalizable. In this challenging context, we first rely on measurements of the output signals along with prior statistical information on the inputs to identify the diffusion filter. Such system identification problem involves solving a system of quadratic matrix equations, which we show is identifiable under spectral-diversity assumptions on the input covariances. For algorithmic purposes we recast it as a smooth quadratic minimization subject to Stiefel manifold constraints. Subsequent identification of the network topology given the graph filter estimate boils down to finding a sparse and structurally admissible shift that commutes with the given filter, thus, forcing the latter to be a polynomial in the sought graph-shift operator. A joint graph filter and topology identification algorithm is also proposed, which alternates between the aforementioned steps in a mutually reinforcing fashion to offer improved sample complexity. Numerical tests corroborate the effectiveness of the proposed algorithms in recovering synthetic digraphs and real-data case studies, and illustrate their potential utility on urban mobility analyses as well as portfolio optimization.
Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
LatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts
Jan 26, 2026Mixture of Experts (MoEs) have become a central component of many state-of-the-art open-source and proprietary large language models. Despite their widespread adoption, it remains unclear how close existing MoE architectures are to optimal with respect to inference cost, as measured by accuracy per floating-point operation and per parameter. In this work, we revisit MoE design from a hardware-software co-design perspective, grounded in empirical and theoretical considerations. We characterize key performance bottlenecks across diverse deployment regimes, spanning offline high-throughput execution and online, latency-critical inference. Guided by these insights, we introduce LatentMoE, a new model architecture resulting from systematic design exploration and optimized for maximal accuracy per unit of compute. Empirical design space exploration at scales of up to 95B parameters and over a 1T-token training horizon, together with supporting theoretical analysis, shows that LatentMoE consistently outperforms standard MoE architectures in terms of accuracy per FLOP and per parameter. Given its strong performance, the LatentMoE architecture has been adopted by the flagship Nemotron-3 Super and Ultra models and scaled to substantially larger regimes, including longer token horizons and larger model sizes, as reported in Nvidia et al. (arXiv:2512.20856).
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
SeedLM: Compressing LLM Weights into Seeds of Pseudo-Random Generators
Oct 14, 2024



Large Language Models (LLMs) have transformed natural language processing, but face significant challenges in widespread deployment due to their high runtime cost. In this paper, we introduce SeedLM, a novel post-training compression method that uses seeds of pseudo-random generators to encode and compress model weights. Specifically, for each block of weights, we find a seed that is fed into a Linear Feedback Shift Register (LFSR) during inference to efficiently generate a random matrix. This matrix is then linearly combined with compressed coefficients to reconstruct the weight block. SeedLM reduces memory access and leverages idle compute cycles during inference, effectively speeding up memory-bound tasks by trading compute for fewer memory accesses. Unlike state-of-the-art compression methods that rely on calibration data, our approach is data-free and generalizes well across diverse tasks. Our experiments with Llama 3 70B, which is particularly challenging to compress, show that SeedLM achieves significantly better zero-shot accuracy retention at 4- and 3-bit than state-of-the-art techniques, while maintaining performance comparable to FP16 baselines. Additionally, FPGA-based tests demonstrate that 4-bit SeedLM, as model size increases to 70B, approaches a 4x speed-up over an FP16 Llama 2/3 baseline.
Microscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
Shared Microexponents: A Little Shifting Goes a Long Way
Feb 16, 2023



This paper introduces Block Data Representations (BDR), a framework for exploring and evaluating a wide spectrum of narrow-precision formats for deep learning. It enables comparison of popular quantization standards, and through BDR, new formats based on shared microexponents (MX) are identified, which outperform other state-of-the-art quantization approaches, including narrow-precision floating-point and block floating-point. MX utilizes multiple levels of quantization scaling with ultra-fine scaling factors based on shared microexponents in the hardware. The effectiveness of MX is demonstrated on real-world models including large-scale generative pretraining and inferencing, and production-scale recommendation systems.
Non-Local Feature Aggregation on Graphs via Latent Fixed Data Structures
Aug 16, 2021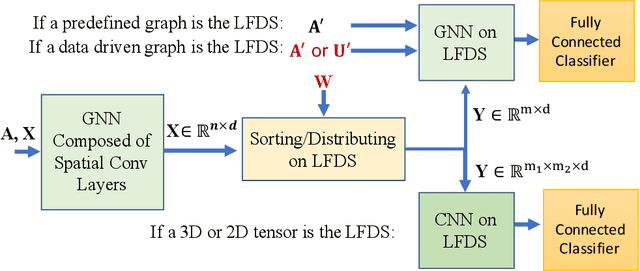
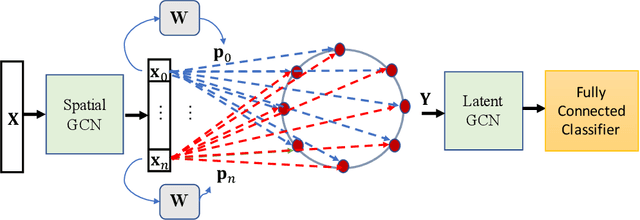
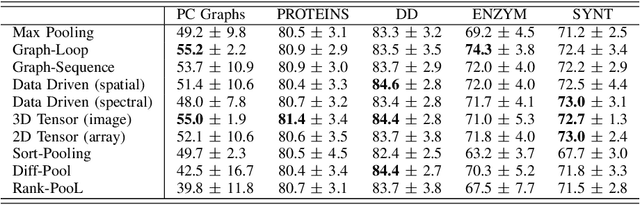
In contrast to image/text data whose order can be used to perform non-local feature aggregation in a straightforward way using the pooling layers, graphs lack the tensor representation and mostly the element-wise max/mean function is utilized to aggregate the locally extracted feature vectors. In this paper, we present a novel approach for global feature aggregation in Graph Neural Networks (GNNs) which utilizes a Latent Fixed Data Structure (LFDS) to aggregate the extracted feature vectors. The locally extracted feature vectors are sorted/distributed on the LFDS and a latent neural network (CNN/GNN) is utilized to perform feature aggregation on the LFDS. The proposed approach is used to design several novel global feature aggregation methods based on the choice of the LFDS. We introduce multiple LFDSs including loop, 3D tensor (image), sequence, data driven graphs and an algorithm which sorts/distributes the extracted local feature vectors on the LFDS. While the computational complexity of the proposed methods are linear with the order of input graphs, they achieve competitive or better results.