 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
Shared Microexponents: A Little Shifting Goes a Long Way
Feb 16, 2023



This paper introduces Block Data Representations (BDR), a framework for exploring and evaluating a wide spectrum of narrow-precision formats for deep learning. It enables comparison of popular quantization standards, and through BDR, new formats based on shared microexponents (MX) are identified, which outperform other state-of-the-art quantization approaches, including narrow-precision floating-point and block floating-point. MX utilizes multiple levels of quantization scaling with ultra-fine scaling factors based on shared microexponents in the hardware. The effectiveness of MX is demonstrated on real-world models including large-scale generative pretraining and inferencing, and production-scale recommendation systems.
Training Large Neural Networks with Constant Memory using a New Execution Algorithm
Feb 22, 2020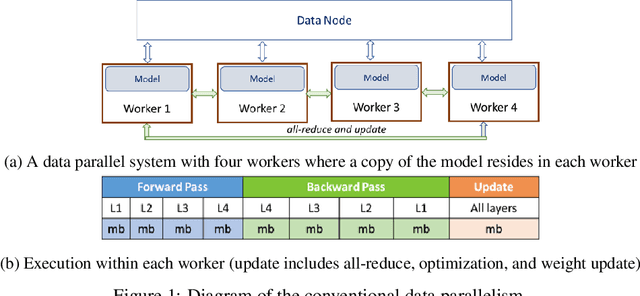

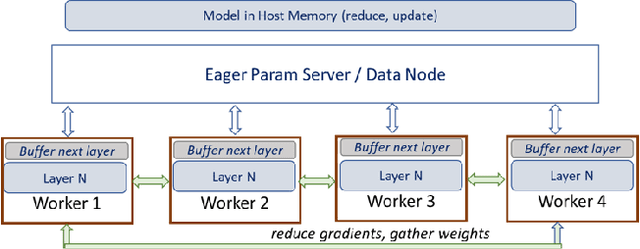
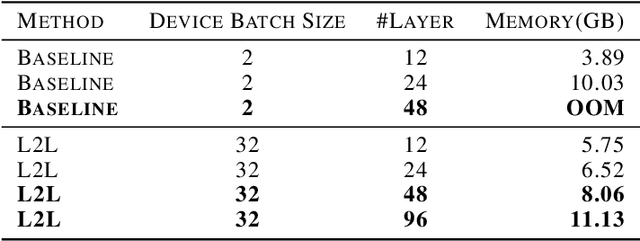
Widely popular transformer-based NLP models such as BERT and GPT have enormous capacity trending to billions of parameters. Current execution methods demand brute-force resources such as HBM devices and high speed interconnectivity for data parallelism. In this paper, we introduce a new relay-style execution technique called L2L (layer-to-layer) where at any given moment, the device memory is primarily populated only with the executing layer(s)'s footprint. The model resides in the DRAM memory attached to either a CPU or an FPGA as an entity we call eager param-server (EPS). Unlike a traditional param-server, EPS transmits the model piecemeal to the devices thereby allowing it to perform other tasks in the background such as reduction and distributed optimization. To overcome the bandwidth issues of shuttling parameters to and from EPS, the model is executed a layer at a time across many micro-batches instead of the conventional method of minibatches over whole model. In this paper, we explore a conservative version of L2L that is implemented on a modest Azure instance for BERT-Large running it with a batch size of 32 on a single V100 GPU using less than 8GB memory. Our results show a more stable learning curve, faster convergence, better accuracy and 35% reduction in memory compared to the state-of-the-art baseline. Our method reproduces BERT results on any mid-level GPU that was hitherto not feasible. L2L scales to arbitrary depth without impacting memory or devices allowing researchers to develop affordable devices. It also enables dynamic approaches such as neural architecture search. This work has been performed on GPUs first but also targeted towards high TFLOPS/Watt accelerators such as Graphcore IPUs. The code will soon be available on github.