 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reweight Examples for Robust Deep Learning
Jun 08, 2018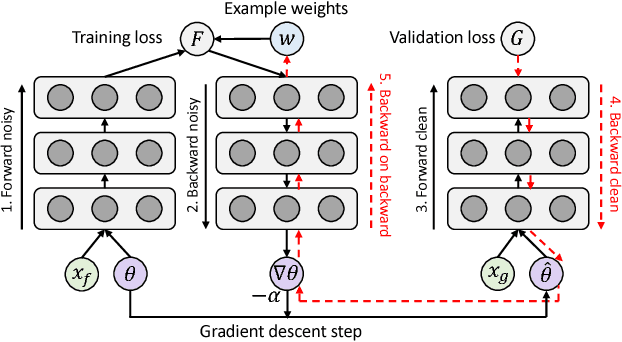
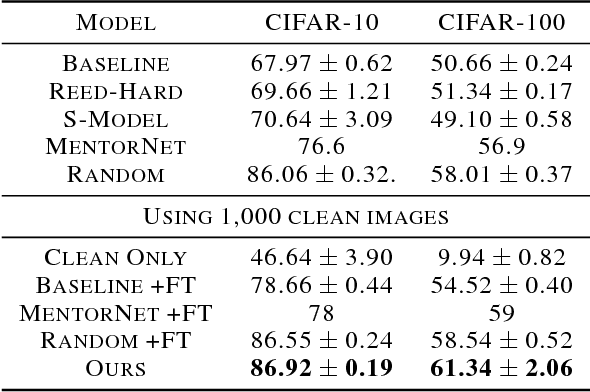
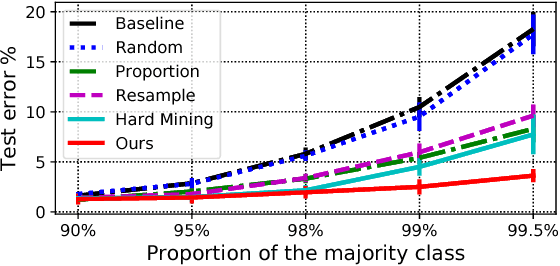
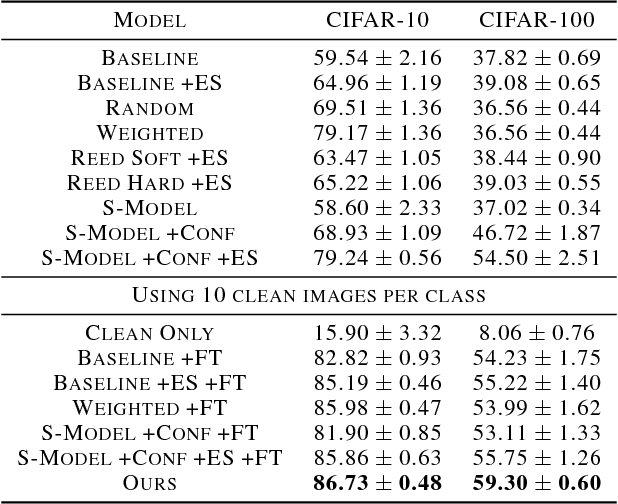
Deep neural networks have been shown to be very powerful modeling tools for many supervised learning tasks involving complex input patterns. However, they can also easily overfit to training set biases and label noises. In addition to various regularizers, example reweighting algorithms are popular solutions to these problems, but they require careful tuning of additional hyperparameters, such as example mining schedules and regularization hyperparameters. In contrast to past reweighting methods, which typically consist of functions of the cost value of each example, in this work we propose a novel meta-learning algorithm that learns to assign weights to training examples based on their gradient directions. To determine the example weights, our method performs a meta gradient descent step on the current mini-batch example weights (which are initialized from zero) to minimize the loss on a clean unbiased validation set. Our proposed method can be easily implemented on any type of deep network, does not require any additional hyperparameter tuning, and achieves impressive performance on class imbalance and corrupted label problems where only a small amount of clean validation data is available.
SBNet: Sparse Blocks Network for Fast Inference
Jun 07, 2018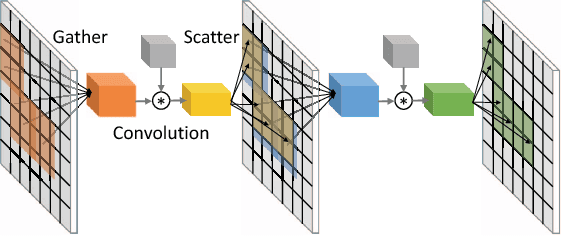
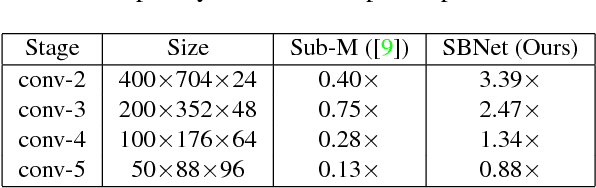
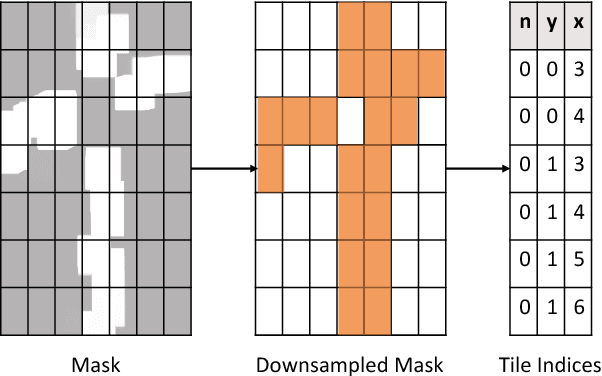
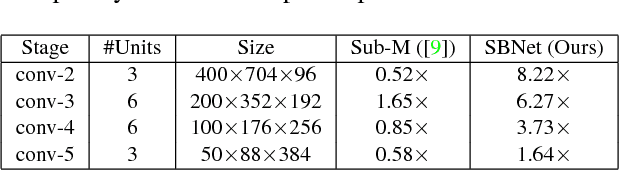
Conventional deep convolutional neural networks (CNNs) apply convolution operators uniformly in space across all feature maps for hundreds of layers - this incurs a high computational cost for real-time applications. For many problems such as object detection and semantic segmentation, we are able to obtain a low-cost computation mask, either from a priori problem knowledge, or from a low-resolution segmentation network. We show that such computation masks can be used to reduce computation in the high-resolution main network. Variants of sparse activation CNNs have previously been explored on small-scale tasks and showed no degradation in terms of object classification accuracy, but often measured gains in terms of theoretical FLOPs without realizing a practical speed-up when compared to highly optimized dense convolution implementations. In this work, we leverage the sparsity structure of computation masks and propose a novel tiling-based sparse convolution algorithm. We verified the effectiveness of our sparse CNN on LiDAR-based 3D object detection, and we report significant wall-clock speed-ups compared to dense convolution without noticeable loss of accuracy.
Inference in Probabilistic Graphical Models by Graph Neural Networks
May 25, 2018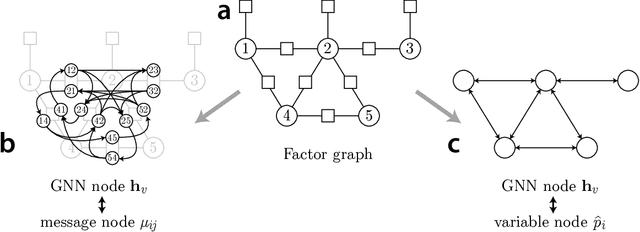
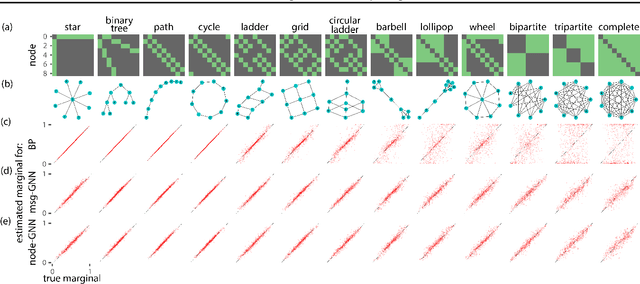
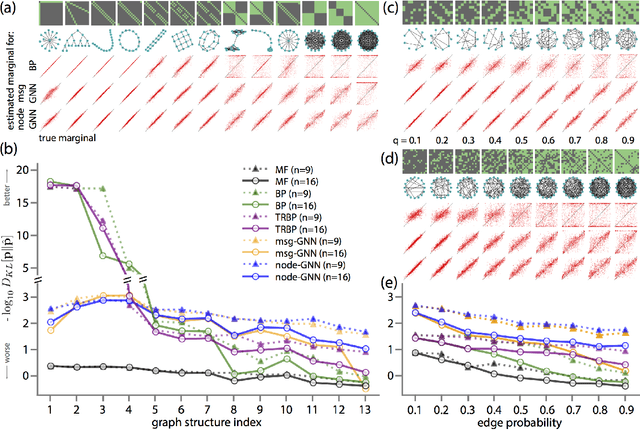
A fundamental computation for statistical inference and accurate decision-making is to compute the marginal probabilities or most probable states of task-relevant variables. Probabilistic graphical models can efficiently represent the structure of such complex data, but performing these inferences is generally difficult. Message-passing algorithms, such as belief propagation, are a natural way to disseminate evidence amongst correlated variables while exploiting the graph structure, but these algorithms can struggle when the conditional dependency graphs contain loops. Here we use Graph Neural Networks (GNNs) to learn a message-passing algorithm that solves these inference tasks. We first show that the architecture of GNNs is well-matched to inference tasks. We then demonstrate the efficacy of this inference approach by training GNNs on a collection of graphical models and showing that they substantially outperform belief propagation on loopy graphs. Our message-passing algorithms generalize out of the training set to larger graphs and graphs with different structure.
MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving
May 08, 2018
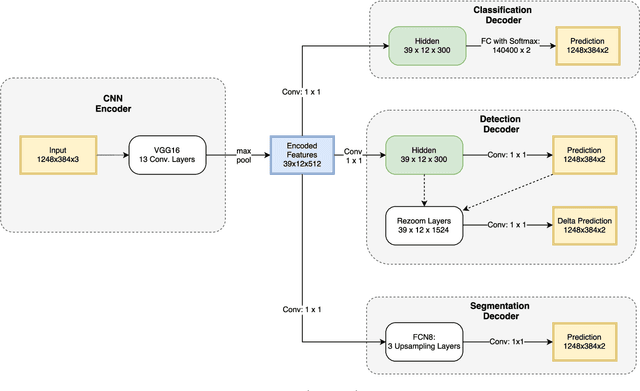
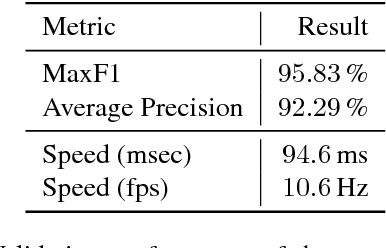
While most approaches to semantic reasoning have focused on improving performance, in this paper we argue that computational times are very important in order to enable real time applications such as autonomous driving. Towards this goal, we present an approach to joint classification, detection and semantic segmentation via a unified architecture where the encoder is shared amongst the three tasks. Our approach is very simple, can be trained end-to-end and performs extremely well in the challenging KITTI dataset, outperforming the state-of-the-art in the road segmentation task. Our approach is also very efficient, taking less than 100 ms to perform all tasks.
Learning deep structured active contours end-to-end
Mar 16, 2018
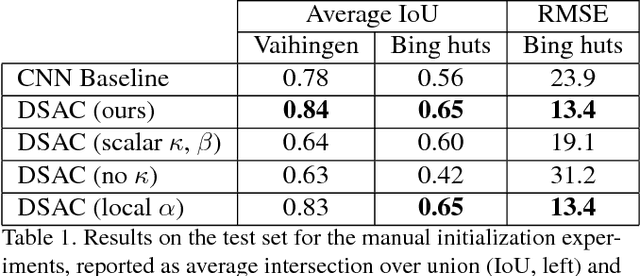
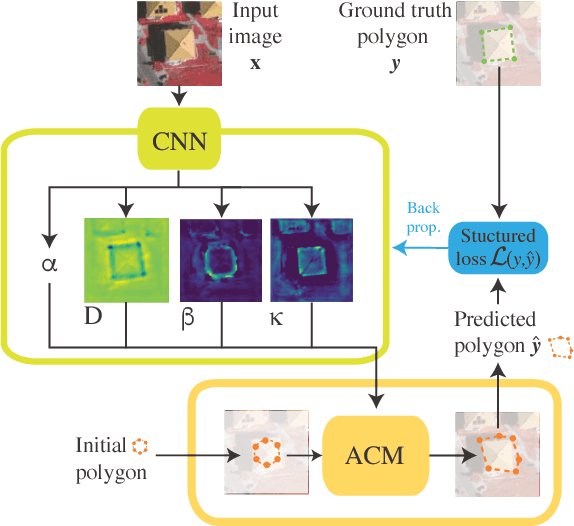
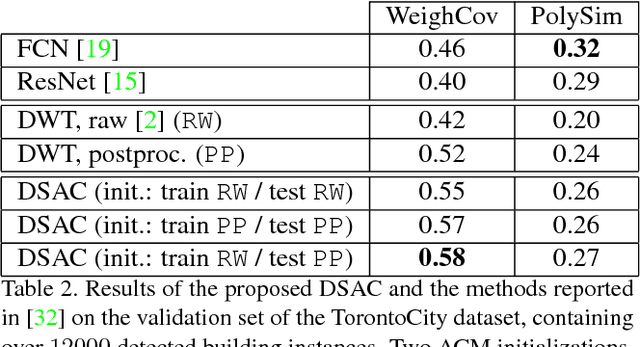
The world is covered with millions of buildings, and precisely knowing each instance's position and extents is vital to a multitude of applications. Recently, automated building footprint segmentation models have shown superior detection accuracy thanks to the usage of Convolutional Neural Networks (CNN). However, even the latest evolutions struggle to precisely delineating borders, which often leads to geometric distortions and inadvertent fusion of adjacent building instances. We propose to overcome this issue by exploiting the distinct geometric properties of buildings. To this end, we present Deep Structured Active Contours (DSAC), a novel framework that integrates priors and constraints into the segmentation process, such as continuous boundaries, smooth edges, and sharp corners. To do so, DSAC employs Active Contour Models (ACM), a family of constraint- and prior-based polygonal models. We learn ACM parameterizations per instance using a CNN, and show how to incorporate all components in a structured output model, making DSAC trainable end-to-end. We evaluate DSAC on three challenging building instance segmentation datasets, where it compares favorably against state-of-the-art. Code will be made available.
Graph Partition Neural Networks for Semi-Supervised Classification
Mar 16, 2018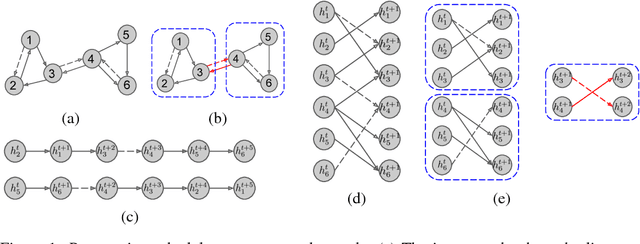

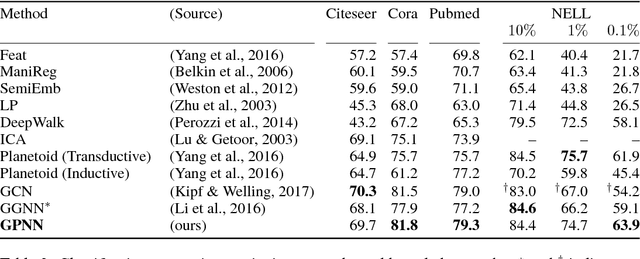
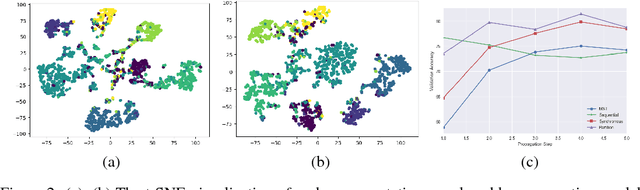
We present graph partition neural networks (GPNN), an extension of graph neural networks (GNNs) able to handle extremely large graphs. GPNNs alternate between locally propagating information between nodes in small subgraphs and globally propagating information between the subgraphs. To efficiently partition graphs, we experiment with several partitioning algorithms and also propose a novel variant for fast processing of large scale graphs. We extensively test our model on a variety of semi-supervised node classification tasks. Experimental results indicate that GPNNs are either superior or comparable to state-of-the-art methods on a wide variety of datasets for graph-based semi-supervised classification. We also show that GPNNs can achieve similar performance as standard GNNs with fewer propagation steps.
Few-Shot Learning Through an Information Retrieval Lens
Nov 14, 2017
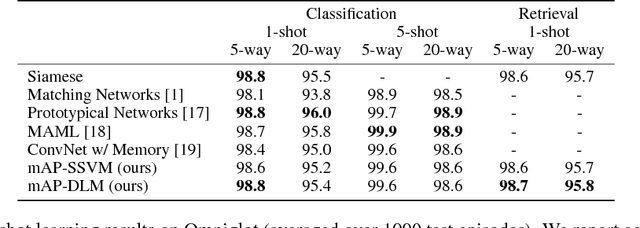
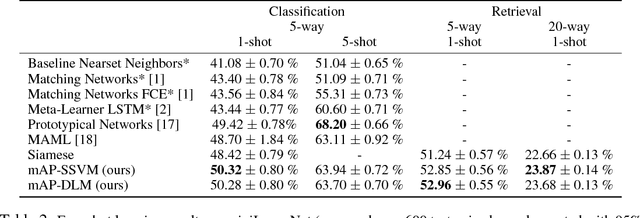
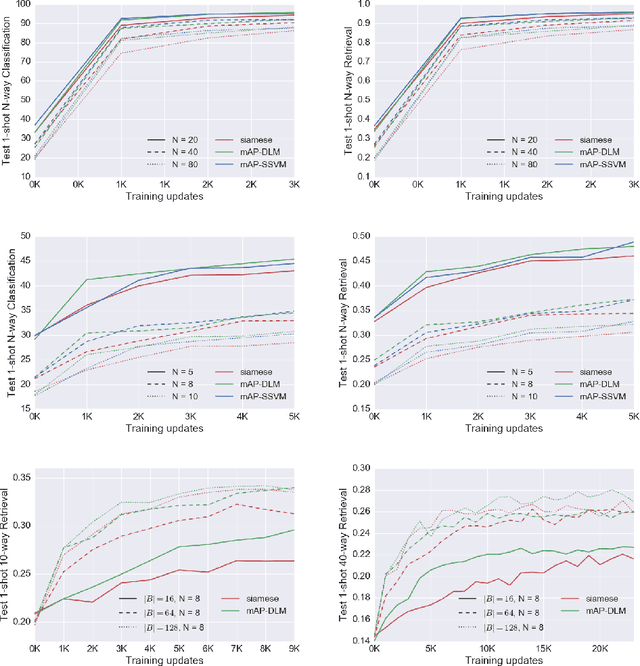
Few-shot learning refers to understanding new concepts from only a few examples. We propose an information retrieval-inspired approach for this problem that is motivated by the increased importance of maximally leveraging all the available information in this low-data regime. We define a training objective that aims to extract as much information as possible from each training batch by effectively optimizing over all relative orderings of the batch points simultaneously. In particular, we view each batch point as a `query' that ranks the remaining ones based on its predicted relevance to them and we define a model within the framework of structured prediction to optimize mean Average Precision over these rankings. Our method achieves impressive results on the standard few-shot classification benchmarks while is also capable of few-shot retrieval.
Be Your Own Prada: Fashion Synthesis with Structural Coherence
Oct 19, 2017
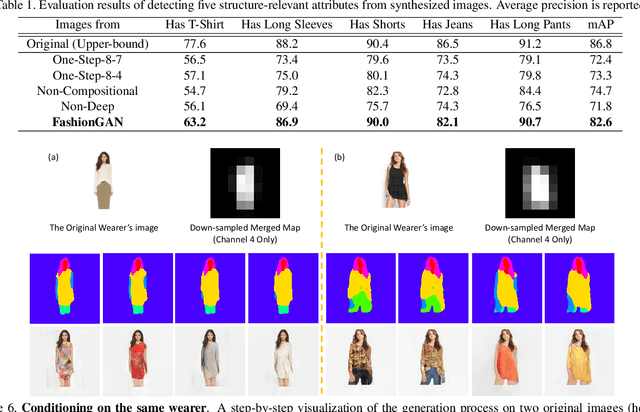
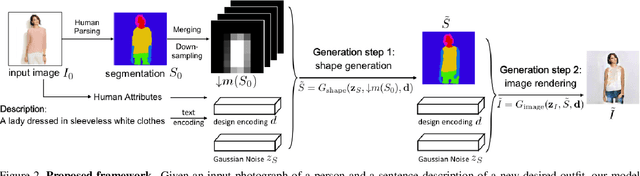

We present a novel and effective approach for generating new clothing on a wearer through generative adversarial learning. Given an input image of a person and a sentence describing a different outfit, our model "redresses" the person as desired, while at the same time keeping the wearer and her/his pose unchanged. Generating new outfits with precise regions conforming to a language description while retaining wearer's body structure is a new challenging task. Existing generative adversarial networks are not ideal in ensuring global coherence of structure given both the input photograph and language description as conditions. We address this challenge by decomposing the complex generative process into two conditional stages. In the first stage, we generate a plausible semantic segmentation map that obeys the wearer's pose as a latent spatial arrangement. An effective spatial constraint is formulated to guide the generation of this semantic segmentation map. In the second stage, a generative model with a newly proposed compositional mapping layer is used to render the final image with precise regions and textures conditioned on this map. We extended the DeepFashion dataset [8] by collecting sentence descriptions for 79K images. We demonstrate the effectiveness of our approach through both quantitative and qualitative evaluations. A user study is also conducted. The codes and the data are available at http://mmlab.ie.cuhk. edu.hk/projects/FashionGAN/.
Situation Recognition with Graph Neural Networks
Aug 14, 2017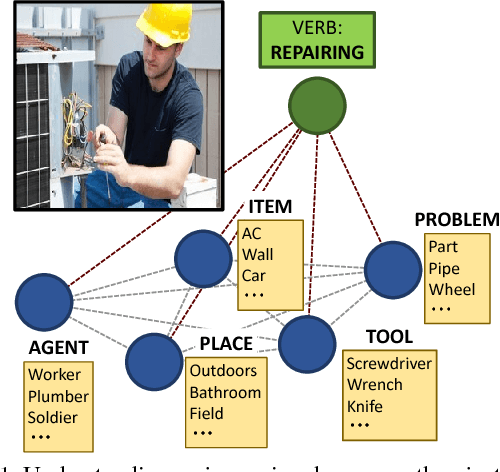
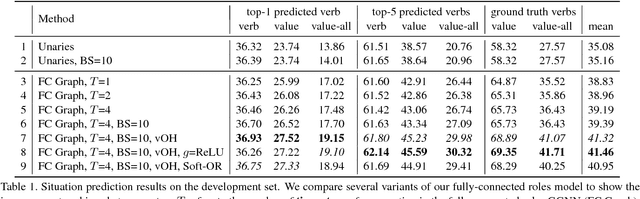

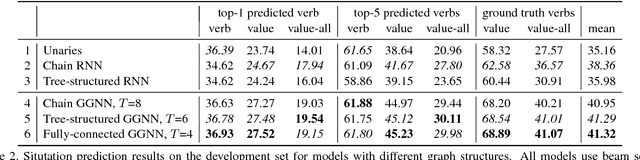
We address the problem of recognizing situations in images. Given an image, the task is to predict the most salient verb (action), and fill its semantic roles such as who is performing the action, what is the source and target of the action, etc. Different verbs have different roles (e.g. attacking has weapon), and each role can take on many possible values (nouns). We propose a model based on Graph Neural Networks that allows us to efficiently capture joint dependencies between roles using neural networks defined on a graph. Experiments with different graph connectivities show that our approach that propagates information between roles significantly outperforms existing work, as well as multiple baselines. We obtain roughly 3-5% improvement over previous work in predicting the full situation. We also provide a thorough qualitative analysis of our model and influence of different roles in the verbs.
Towards Diverse and Natural Image Descriptions via a Conditional GAN
Aug 11, 2017
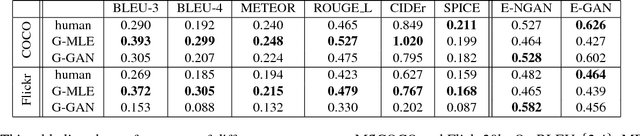
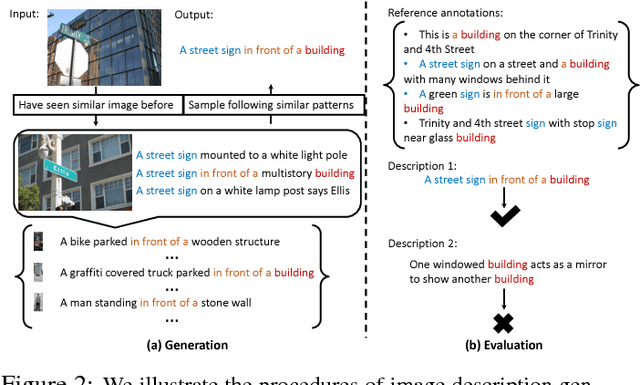

Despite the substantial progress in recent years, the image captioning techniques are still far from being perfect.Sentences produced by existing methods, e.g. those based on RNNs, are often overly rigid and lacking in variability. This issue is related to a learning principle widely used in practice, that is, to maximize the likelihood of training samples. This principle encourages high resemblance to the "ground-truth" captions while suppressing other reasonable descriptions. Conventional evaluation metrics, e.g. BLEU and METEOR, also favor such restrictive methods. In this paper, we explore an alternative approach, with the aim to improve the naturalness and diversity -- two essential properties of human expression. Specifically, we propose a new framework based on Conditional Generative Adversarial Networks (CGAN), which jointly learns a generator to produce descriptions conditioned on images and an evaluator to assess how well a description fits the visual content. It is noteworthy that training a sequence generator is nontrivial. We overcome the difficulty by Policy Gradient, a strategy stemming from Reinforcement Learning, which allows the generator to receive early feedback along the way. We tested our method on two large datasets, where it performed competitively against real people in our user study and outperformed other methods on various tasks.