 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Multi-Agent Framework for Automated Concrete Barrier Design
Jun 11, 2026The design of reinforced concrete highway barriers is a safety-critical process that requires strict compliance with regulatory provisions such as the AASHTO-LRFD bridge design guidelines. Current engineering practice relies heavily on manual, iterative, and heuristic calculations to satisfy complex nonlinear material and mechanics constraints. Although Large Language Models (LLMs) demonstrate strong generative capabilities, their direct application to structural engineering remains limited by hallucination risks and insufficient physical grounding. To address these challenges, this study proposes a novel "generation-evaluation-optimization" closed-loop framework for automated concrete barrier design using the multi-agent orchestration capabilities of AutoGen. Experimental results demonstrate that the proposed agentic framework achieves over 98% design accuracy, significantly outperforming standalone general-purpose LLMs. More importantly, the study reveals that design performance is not necessarily correlated with model scale, where an 8B-parameter lightweight model could outperform unconstrained 631B-parameter flagship models. This finding highlights the potential to substantially reduce computational costs while improving the accessibility of AI-assisted engineering tools for industry applications. The source code for the proposed multi-agent design framework is available at the project GitHub repository: https://github.com/MXY820/barrier-design. Keywords: Structural Engineering; Multi-Agent Systems; Large Language Models; Concrete Barrier Design; AutoGen; Design Automation.
Human-Enhanced Loop Modeling (HELM): Agent-Based Finite Element Modeling of Concrete Bridge Barriers
Jun 11, 2026Finite element (FE) modeling of safety-critical infrastructure such as bridge barriers requires high-fidelity nonlinear dynamic analysis, yet the current FE modeling process remains labor-intensive and lacks automation. This paper presents the Human-Enhanced Loop Modeling (HELM) framework, a collaborative human-agent protocol that decomposes long-sequence finite element modeling into discrete, visually verifiable checkpoints across geometry generation, boundary condition definition, and material assignment. The framework is demonstrated through a 20-case matrix of reinforced concrete bridge barriers under MASH TL-4 and TL-5 lateral loading conditions, interfacing specialized agents with two widely used commercial FE softwares, i.e., ANSYS and LS-PrePost. Experimental results show that HELM improves the baseline autonomous modeling success rate from 20% to 75%, with agent-level pass rates for geometry and boundary condition tasks approximately doubling. Error analysis reveals that spatial reasoning and algebraic logic limitations constitute the primary failure modes, underscoring the value of structured human-in-the-loop intervention for modeling automation. The complete agent design code and prompts are open-sourced and can be accessed at: https://github.com/SimAgentDev/Ansys-LSPP-AgentKit.
Automating Structural Analysis Across Multiple Software Platforms Using Large Language Models
Apr 10, 2026Recent advances in large language models (LLMs) have shown the promise to significantly accelerate the workflow by automating structural modeling and analysis. However, existing studies primarily focus on enabling LLMs to operate a single structural analysis software platform. In practice, structural engineers often rely on multiple finite element analysis (FEA) tools, such as ETABS, SAP2000, and OpenSees, depending on project needs, user preferences, and company constraints. This limitation restricts the practical deployment of LLM-assisted engineering workflows. To address this gap, this study develops LLMs capable of automating frame structural analysis across multiple software platforms. The LLMs adopt a two-stage multi-agent architecture. In Stage 1, a cohort of agents collaboratively interpret user input and perform structured reasoning to infer geometric, material, boundary, and load information required for finite element modeling. The outputs of these agents are compiled into a unified JSON representation. In Stage 2, code translation agents operate in parallel to convert the JSON file into executable scripts across multiple structural analysis platforms. Each agent is prompted with the syntax rules and modeling workflows of its target software. The LLMs are evaluated using 20 representative frame problems across three widely used platforms: ETABS, SAP2000, and OpenSees. Results from ten repeated trials demonstrate consistently reliable performance, achieving accuracy exceeding 90% across all cases.
A Novel Multi-Agent Architecture to Reduce Hallucinations of Large Language Models in Multi-Step Structural Modeling
Mar 08, 2026Large language models (LLMs) such as GPT and Gemini have demonstrated remarkable capabilities in contextual understanding and reasoning. The strong performance of LLMs has sparked growing interest in leveraging them to automate tasks traditionally dependent on human expertise. Recently, LLMs have been integrated into intelligent agents capable of operating structural analysis software (e.g., OpenSees) to construct structural models and perform analyses. However, existing LLMs are limited in handling multi-step structural modeling due to frequent hallucinations and error accumulation during long-sequence operations. To this end, this study presents a novel multi-agent architecture to automate the structural modeling and analysis using OpenSeesPy. First, problem analysis and construction planning agents extract key parameters from user descriptions and formulate a stepwise modeling plan. Node and element agents then operate in parallel to assemble the frame geometry, followed by a load assignment agent. The resulting geometric and load information is translated into executable OpenSeesPy scripts by code translation agents. The proposed architecture is evaluated on a benchmark of 20 frame problems over ten repeated trials, achieving 100% accuracy in 18 cases and 90% in the remaining two. The architecture also significantly improves computational efficiency and demonstrates scalability to larger structural systems.
Truncation-Free Matching System for Display Advertising at Alibaba
Feb 18, 2021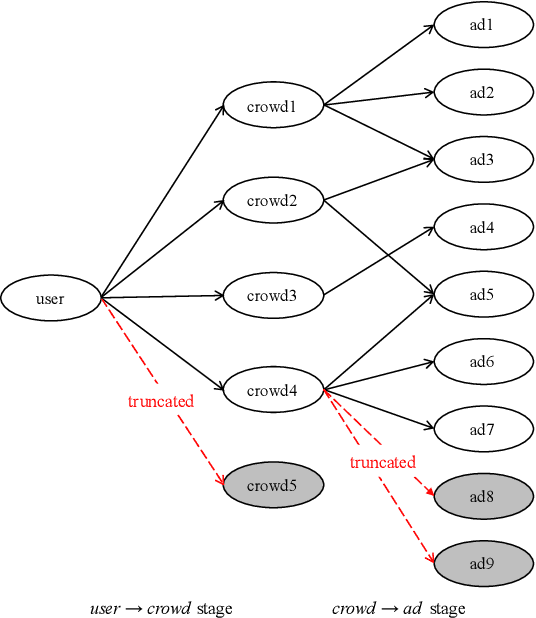


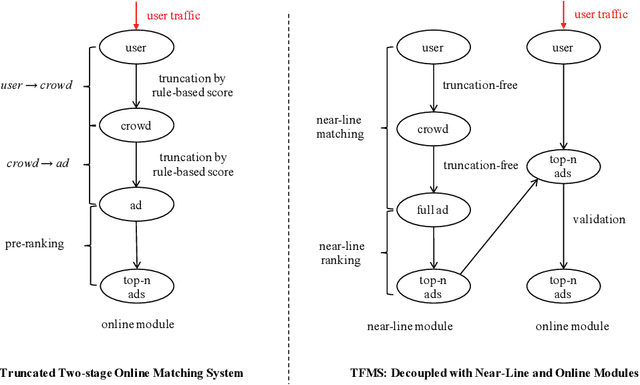
Matching module plays a critical role in display advertising systems. Without query from user, it is challenging for system to match user traffic and ads suitably. System packs up a group of users with common properties such as the same gender or similar shopping interests into a crowd. Here term crowd can be viewed as a tag over users. Then advertisers bid for different crowds and deliver their ads to those targeted users. Matching module in most industrial display advertising systems follows a two-stage paradigm. When receiving a user request, matching system (i) finds the crowds that the user belongs to; (ii) retrieves all ads that have targeted those crowds. However, in applications such as display advertising at Alibaba, with very large volumes of crowds and ads, both stages of matching have to truncate the long-tailed parts for online serving, under limited latency. That's to say, not all ads have the chance to participate in online matching. This results in sub-optimal result for both advertising performance and platform revenue. In this paper, we study the truncation problem and propose a Truncation Free Matching System (TFMS). The basic idea is to decouple the matching computation from the online pipeline. Instead of executing the two-stage matching when user visits, TFMS utilizes a near-line truncation-free matching to pre-calculate and store those top valuable ads for each user. Then the online pipeline just needs to fetch the pre-stored ads as matching results. In this way, we can jump out of online system's latency and computation cost limitations, and leverage flexible computation resource to finish the user-ad matching. TFMS has been deployed in our productive system since 2019, bringing (i) more than 50% improvement of impressions for advertisers who encountered truncation before, (ii) 9.4% Revenue Per Mile gain, which is significant enough for the business.