 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
Mar 27, 2021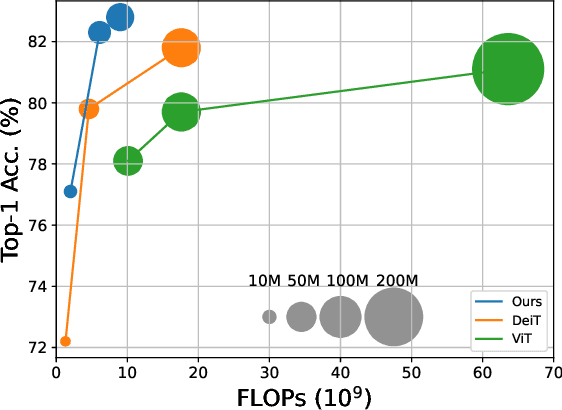
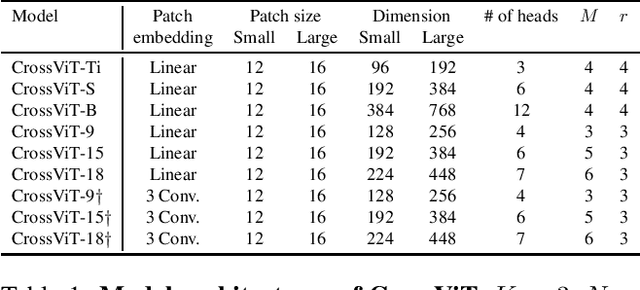
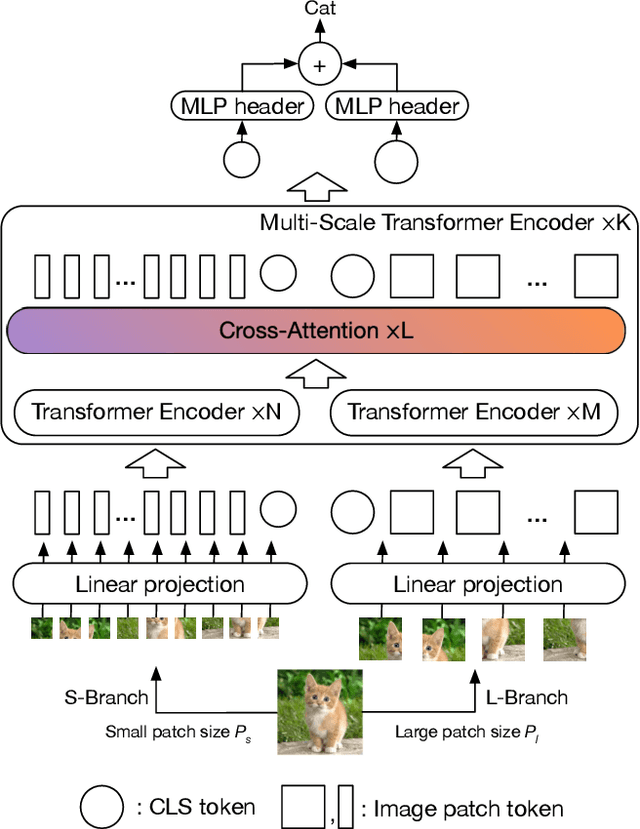
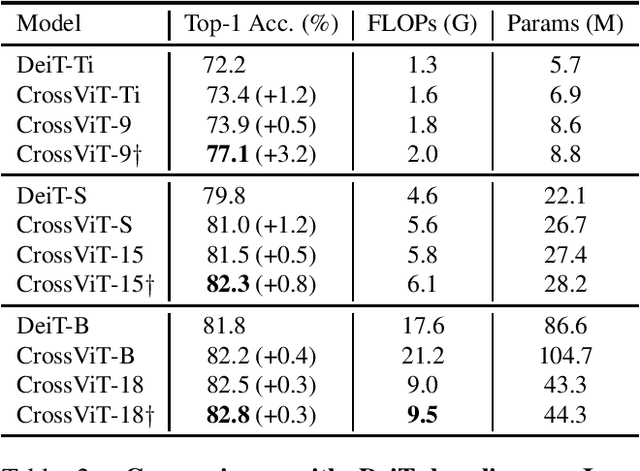
The recently developed vision transformer (ViT) has achieved promising results on image classification compared to convolutional neural networks. Inspired by this, in this paper, we study how to learn multi-scale feature representations in transformer models for image classification. To this end, we propose a dual-branch transformer to combine image patches (i.e., tokens in a transformer) of different sizes to produce stronger image features. Our approach processes small-patch and large-patch tokens with two separate branches of different computational complexity and these tokens are then fused purely by attention multiple times to complement each other. Furthermore, to reduce computation, we develop a simple yet effective token fusion module based on cross attention, which uses a single token for each branch as a query to exchange information with other branches. Our proposed cross-attention only requires linear time for both computational and memory complexity instead of quadratic time otherwise. Extensive experiments demonstrate that the proposed approach performs better than or on par with several concurrent works on vision transformer, in addition to efficient CNN models. For example, on the ImageNet1K dataset, with some architectural changes, our approach outperforms the recent DeiT by a large margin of 2\%
All at Once Network Quantization via Collaborative Knowledge Transfer
Mar 02, 2021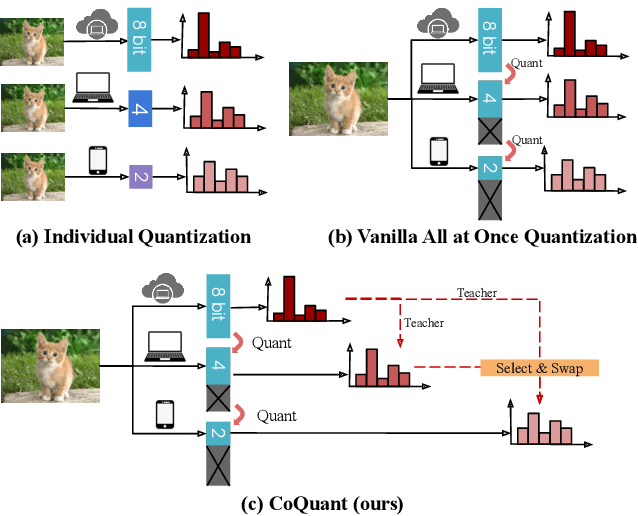
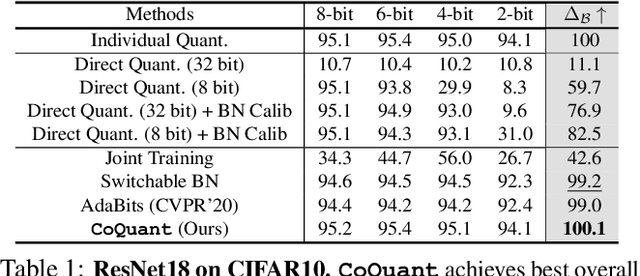
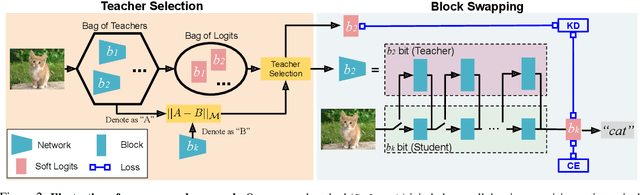
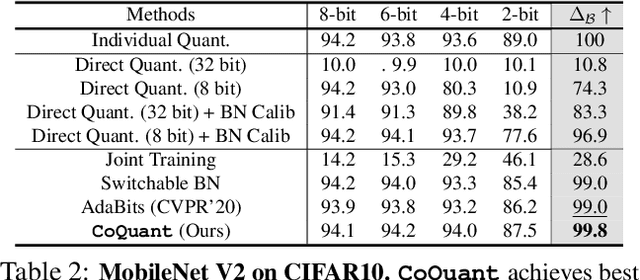
Network quantization has rapidly become one of the most widely used methods to compress and accelerate deep neural networks on edge devices. While existing approaches offer impressive results on common benchmark datasets, they generally repeat the quantization process and retrain the low-precision network from scratch, leading to different networks tailored for different resource constraints. This limits scalable deployment of deep networks in many real-world applications, where in practice dynamic changes in bit-width are often desired. All at Once quantization addresses this problem, by flexibly adjusting the bit-width of a single deep network during inference, without requiring re-training or additional memory to store separate models, for instant adaptation in different scenarios. In this paper, we develop a novel collaborative knowledge transfer approach for efficiently training the all-at-once quantization network. Specifically, we propose an adaptive selection strategy to choose a high-precision \enquote{teacher} for transferring knowledge to the low-precision student while jointly optimizing the model with all bit-widths. Furthermore, to effectively transfer knowledge, we develop a dynamic block swapping method by randomly replacing the blocks in the lower-precision student network with the corresponding blocks in the higher-precision teacher network. Extensive experiments on several challenging and diverse datasets for both image and video classification well demonstrate the efficacy of our proposed approach over state-of-the-art methods.
VA-RED$^2$: Video Adaptive Redundancy Reduction
Feb 15, 2021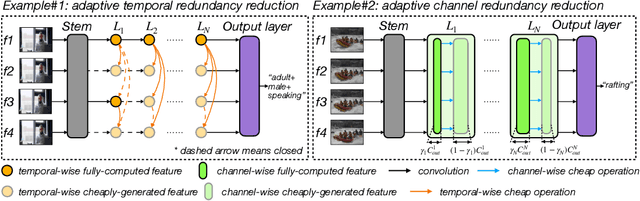
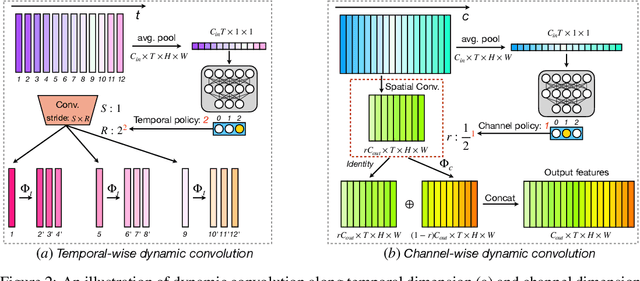
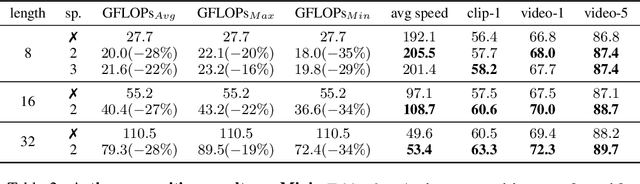
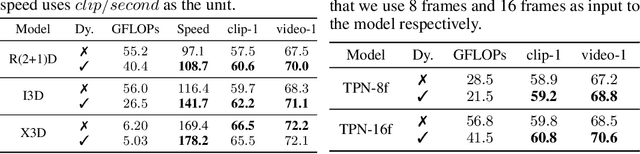
Performing inference on deep learning models for videos remains a challenge due to the large amount of computational resources required to achieve robust recognition. An inherent property of real-world videos is the high correlation of information across frames which can translate into redundancy in either temporal or spatial feature maps of the models, or both. The type of redundant features depends on the dynamics and type of events in the video: static videos have more temporal redundancy while videos focusing on objects tend to have more channel redundancy. Here we present a redundancy reduction framework, termed VA-RED$^2$, which is input-dependent. Specifically, our VA-RED$^2$ framework uses an input-dependent policy to decide how many features need to be computed for temporal and channel dimensions. To keep the capacity of the original model, after fully computing the necessary features, we reconstruct the remaining redundant features from those using cheap linear operations. We learn the adaptive policy jointly with the network weights in a differentiable way with a shared-weight mechanism, making it highly efficient. Extensive experiments on multiple video datasets and different visual tasks show that our framework achieves $20\% - 40\%$ reduction in computation (FLOPs) when compared to state-of-the-art methods without any performance loss. Project page: http://people.csail.mit.edu/bpan/va-red/.
AdaFuse: Adaptive Temporal Fusion Network for Efficient Action Recognition
Feb 10, 2021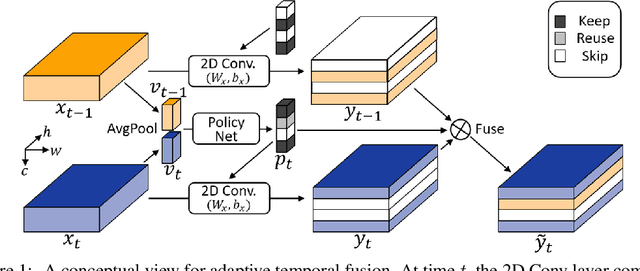

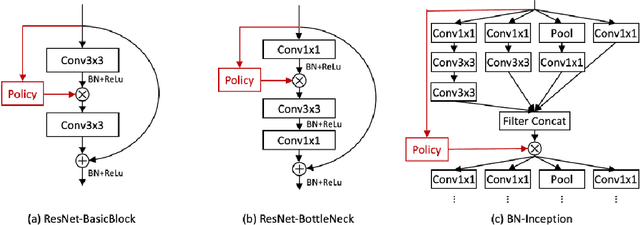
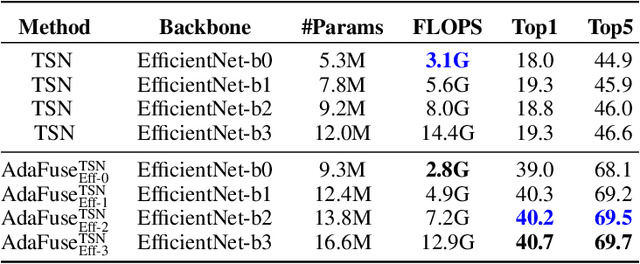
Temporal modelling is the key for efficient video action recognition. While understanding temporal information can improve recognition accuracy for dynamic actions, removing temporal redundancy and reusing past features can significantly save computation leading to efficient action recognition. In this paper, we introduce an adaptive temporal fusion network, called AdaFuse, that dynamically fuses channels from current and past feature maps for strong temporal modelling. Specifically, the necessary information from the historical convolution feature maps is fused with current pruned feature maps with the goal of improving both recognition accuracy and efficiency. In addition, we use a skipping operation to further reduce the computation cost of action recognition. Extensive experiments on Something V1 & V2, Jester and Mini-Kinetics show that our approach can achieve about 40% computation savings with comparable accuracy to state-of-the-art methods. The project page can be found at https://mengyuest.github.io/AdaFuse/
Semi-Supervised Action Recognition with Temporal Contrastive Learning
Feb 04, 2021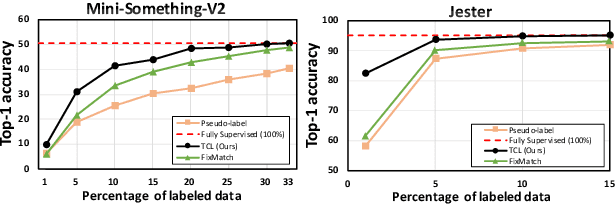
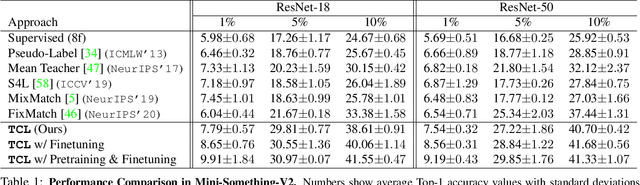
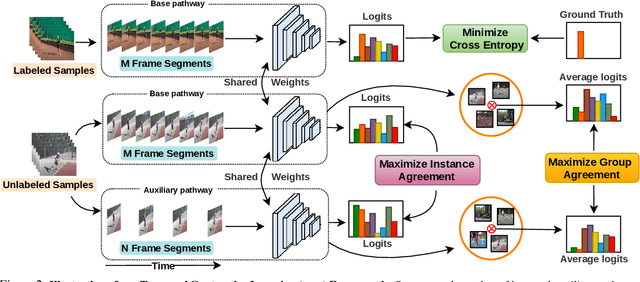
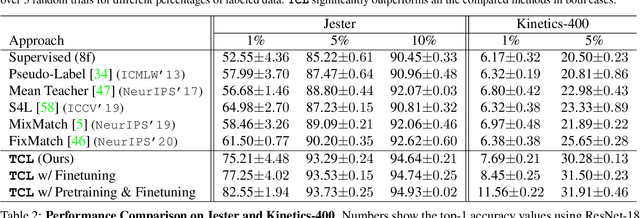
Learning to recognize actions from only a handful of labeled videos is a challenging problem due to the scarcity of tediously collected activity labels. We approach this problem by learning a two-pathway temporal contrastive model using unlabeled videos at two different speeds leveraging the fact that changing video speed does not change an action. Specifically, we propose to maximize the similarity between encoded representations of the same video at two different speeds as well as minimize the similarity between different videos played at different speeds. This way we use the rich supervisory information in terms of 'time' that is present in otherwise unsupervised pool of videos. With this simple yet effective strategy of manipulating video playback rates, we considerably outperform video extensions of sophisticated state-of-the-art semi-supervised image recognition methods across multiple diverse benchmark datasets and network architectures. Interestingly, our proposed approach benefits from out-of-domain unlabeled videos showing generalization and robustness. We also perform rigorous ablations and analysis to validate our approach.
A Maximal Correlation Approach to Imposing Fairness in Machine Learning
Dec 30, 2020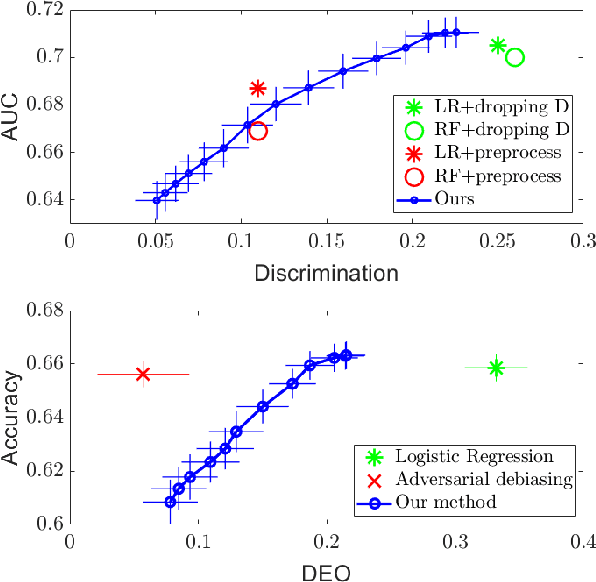
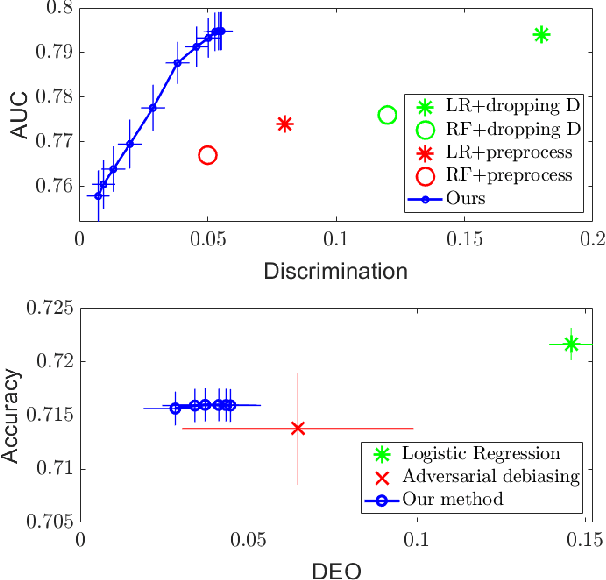
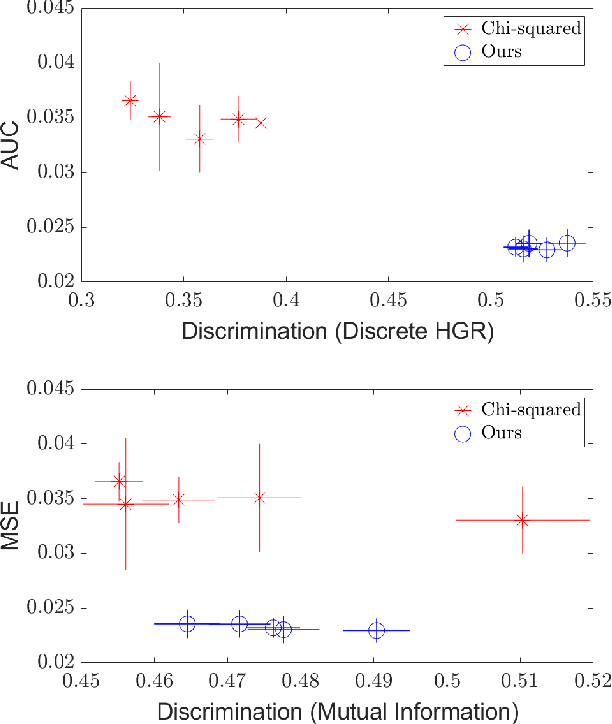
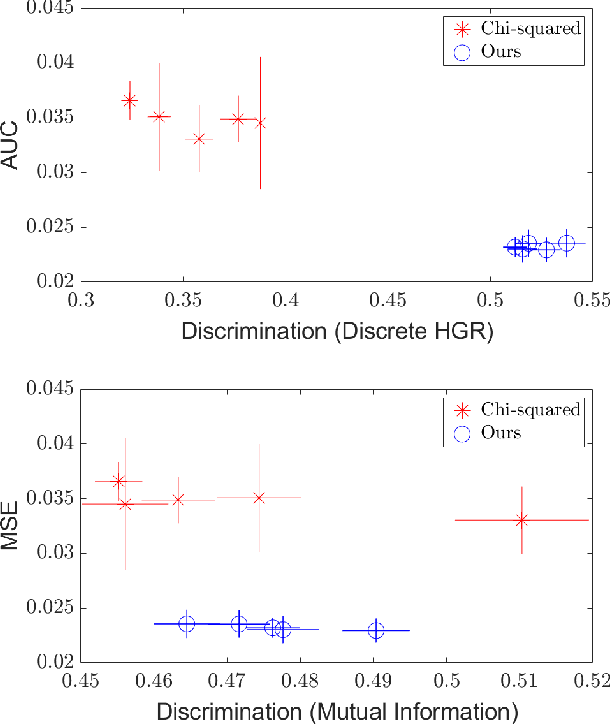
As machine learning algorithms grow in popularity and diversify to many industries, ethical and legal concerns regarding their fairness have become increasingly relevant. We explore the problem of algorithmic fairness, taking an information-theoretic view. The maximal correlation framework is introduced for expressing fairness constraints and shown to be capable of being used to derive regularizers that enforce independence and separation-based fairness criteria, which admit optimization algorithms for both discrete and continuous variables which are more computationally efficient than existing algorithms. We show that these algorithms provide smooth performance-fairness tradeoff curves and perform competitively with state-of-the-art methods on both discrete datasets (COMPAS, Adult) and continuous datasets (Communities and Crimes).
Select, Label, and Mix: Learning Discriminative Invariant Feature Representations for Partial Domain Adaptation
Dec 06, 2020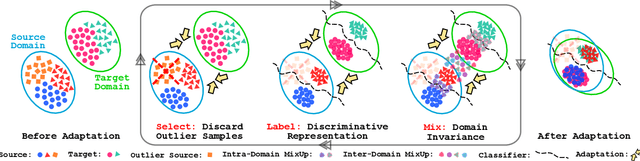
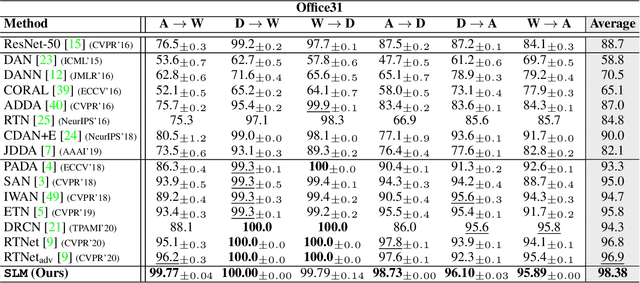
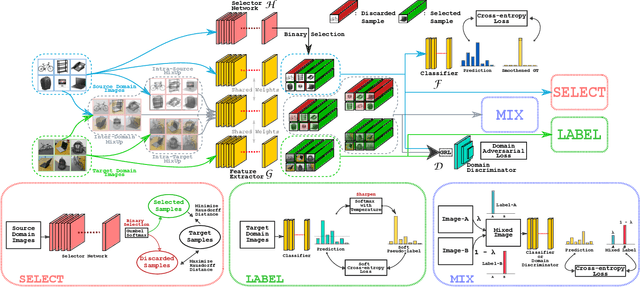
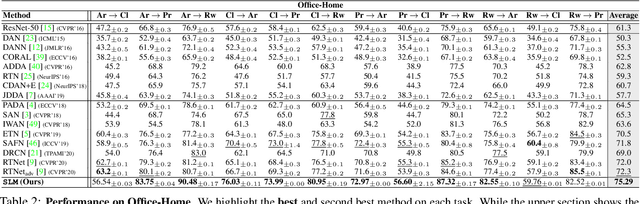
Partial domain adaptation which assumes that the unknown target label space is a subset of the source label space has attracted much attention in computer vision. Despite recent progress, existing methods often suffer from three key problems: negative transfer, lack of discriminability and domain invariance in the latent space. To alleviate the above issues, we develop a novel 'Select, Label, and Mix' (SLM) framework that aims to learn discriminative invariant feature representations for partial domain adaptation. First, we present a simple yet efficient "select" module that automatically filters out the outlier source samples to avoid negative transfer while aligning distributions across both domains. Second, the "label" module iteratively trains the classifier using both the labeled source domain data and the generated pseudo-labels for the target domain to enhance the discriminability of the latent space. Finally, the "mix" module utilizes domain mixup regularization jointly with the other two modules to explore more intrinsic structures across domains leading to a domain-invariant latent space for partial domain adaptation. Extensive experiments on several benchmark datasets demonstrate the superiority of our proposed framework over state-of-the-art methods.
Large Scale Neural Architecture Search with Polyharmonic Splines
Nov 20, 2020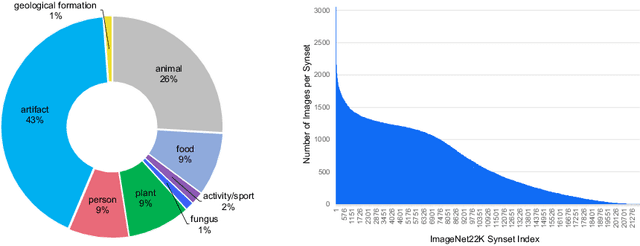
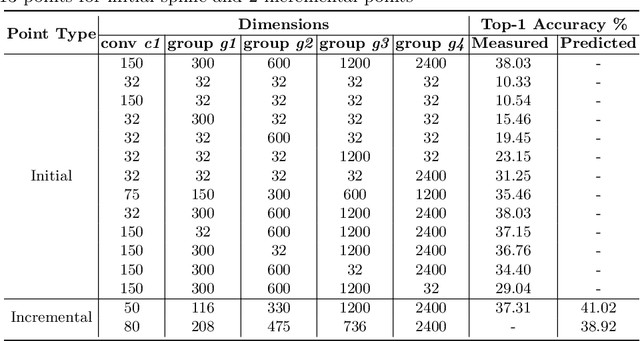
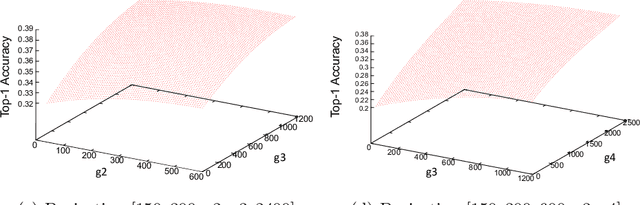
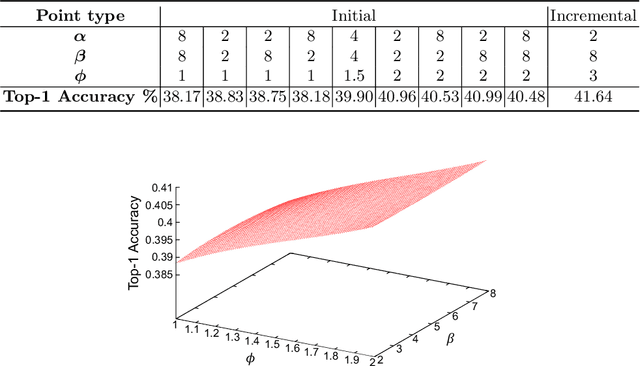
Neural Architecture Search (NAS) is a powerful tool to automatically design deep neural networks for many tasks, including image classification. Due to the significant computational burden of the search phase, most NAS methods have focused so far on small, balanced datasets. All attempts at conducting NAS at large scale have employed small proxy sets, and then transferred the learned architectures to larger datasets by replicating or stacking the searched cells. We propose a NAS method based on polyharmonic splines that can perform search directly on large scale, imbalanced target datasets. We demonstrate the effectiveness of our method on the ImageNet22K benchmark[16], which contains 14 million images distributed in a highly imbalanced manner over 21,841 categories. By exploring the search space of the ResNet [23] and Big-Little Net ResNext [11] architectures directly on ImageNet22K, our polyharmonic splines NAS method designed a model which achieved a top-1 accuracy of 40.03% on ImageNet22K, an absolute improvement of 3.13% over the state of the art with similar global batch size [15].
Deep Analysis of CNN-based Spatio-temporal Representations for Action Recognition
Oct 23, 2020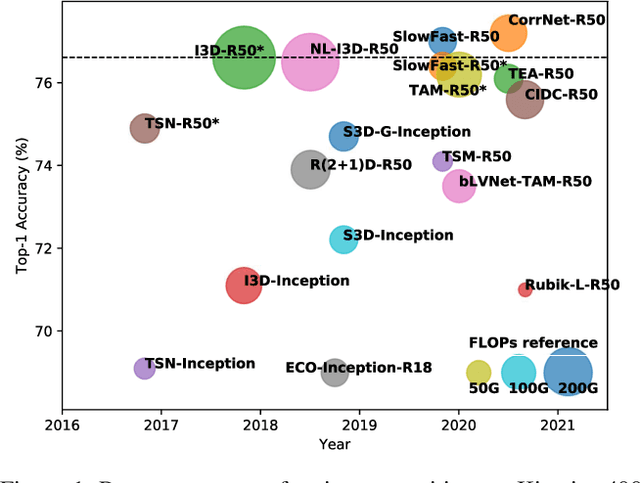
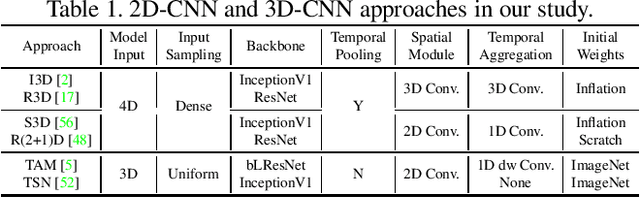
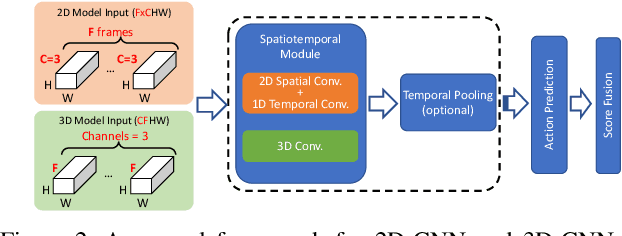
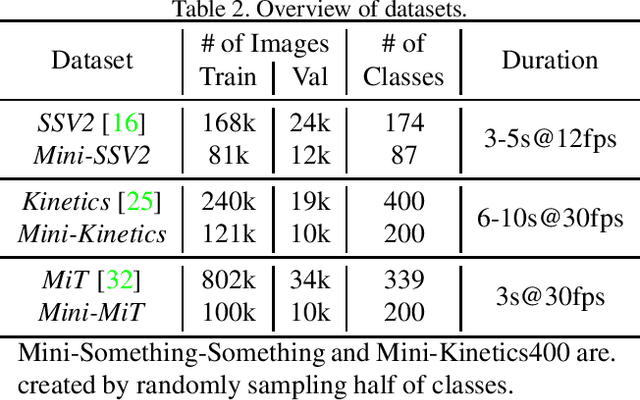
In recent years, a number of approaches based on 2D CNNs and 3D CNNs have emerged for video action recognition, achieving state-of-the-art results on several large-scale benchmark datasets. In this paper, we carry out an in-depth comparative analysis to better understand the differences between these approaches and the progress made by them. To this end, we develop a unified framework for both 2D-CNN and 3D-CNN action models, which enables us to remove bells and whistles and provides a common ground for a fair comparison. We then conduct an effort towards a large-scale analysis involving over 300 action recognition models. Our comprehensive analysis reveals that a) a significant leap is made in efficiency for action recognition, but not in accuracy; b) 2D-CNN and 3D-CNN models behave similarly in terms of spatio-temporal representation abilities and transferability. Our analysis also shows that recent action models seem to be able to learn data-dependent temporality flexibly as needed. Our codes and models are available on https://github.com/IBM/action-recognition-pytorch.
Measurement-driven Security Analysis of Imperceptible Impersonation Attacks
Aug 26, 2020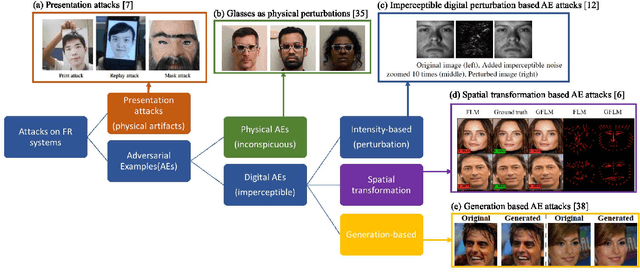


The emergence of Internet of Things (IoT) brings about new security challenges at the intersection of cyber and physical spaces. One prime example is the vulnerability of Face Recognition (FR) based access control in IoT systems. While previous research has shown that Deep Neural Network(DNN)-based FR systems (FRS) are potentially susceptible to imperceptible impersonation attacks, the potency of such attacks in a wide set of scenarios has not been thoroughly investigated. In this paper, we present the first systematic, wide-ranging measurement study of the exploitability of DNN-based FR systems using a large scale dataset. We find that arbitrary impersonation attacks, wherein an arbitrary attacker impersonates an arbitrary target, are hard if imperceptibility is an auxiliary goal. Specifically, we show that factors such as skin color, gender, and age, impact the ability to carry out an attack on a specific target victim, to different extents. We also study the feasibility of constructing universal attacks that are robust to different poses or views of the attacker's face. Our results show that finding a universal perturbation is a much harder problem from the attacker's perspective. Finally, we find that the perturbed images do not generalize well across different DNN models. This suggests security countermeasures that can dramatically reduce the exploitability of DNN-based FR systems.