 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Viewpoint Robustness in Bird's Eye View Segmentation
Sep 11, 2023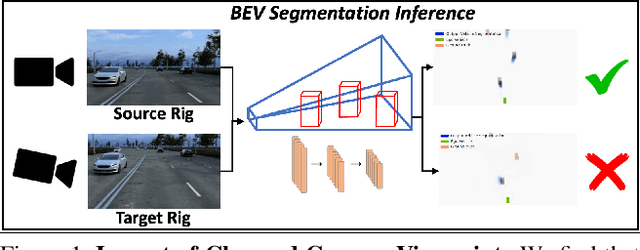


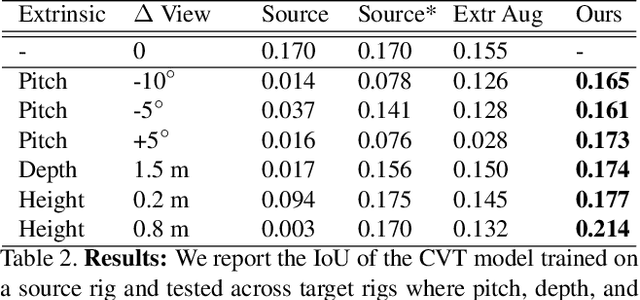
Autonomous vehicles (AV) require that neural networks used for perception be robust to different viewpoints if they are to be deployed across many types of vehicles without the repeated cost of data collection and labeling for each. AV companies typically focus on collecting data from diverse scenarios and locations, but not camera rig configurations, due to cost. As a result, only a small number of rig variations exist across most fleets. In this paper, we study how AV perception models are affected by changes in camera viewpoint and propose a way to scale them across vehicle types without repeated data collection and labeling. Using bird's eye view (BEV) segmentation as a motivating task, we find through extensive experiments that existing perception models are surprisingly sensitive to changes in camera viewpoint. When trained with data from one camera rig, small changes to pitch, yaw, depth, or height of the camera at inference time lead to large drops in performance. We introduce a technique for novel view synthesis and use it to transform collected data to the viewpoint of target rigs, allowing us to train BEV segmentation models for diverse target rigs without any additional data collection or labeling cost. To analyze the impact of viewpoint changes, we leverage synthetic data to mitigate other gaps (content, ISP, etc). Our approach is then trained on real data and evaluated on synthetic data, enabling evaluation on diverse target rigs. We release all data for use in future work. Our method is able to recover an average of 14.7% of the IoU that is otherwise lost when deploying to new rigs.
Conformal Prediction with Large Language Models for Multi-Choice Question Answering
Jun 01, 2023



As large language models continue to be widely developed, robust uncertainty quantification techniques will become crucial for their safe deployment in high-stakes scenarios. In this work, we explore how conformal prediction can be used to provide uncertainty quantification in language models for the specific task of multiple-choice question-answering. We find that the uncertainty estimates from conformal prediction are tightly correlated with prediction accuracy. This observation can be useful for downstream applications such as selective classification and filtering out low-quality predictions. We also investigate the exchangeability assumption required by conformal prediction to out-of-subject questions, which may be a more realistic scenario for many practical applications. Our work contributes towards more trustworthy and reliable usage of large language models in safety-critical situations, where robust guarantees of error rate are required.
Federated Conformal Predictors for Distributed Uncertainty Quantification
Jun 01, 2023



Conformal prediction is emerging as a popular paradigm for providing rigorous uncertainty quantification in machine learning since it can be easily applied as a post-processing step to already trained models. In this paper, we extend conformal prediction to the federated learning setting. The main challenge we face is data heterogeneity across the clients - this violates the fundamental tenet of exchangeability required for conformal prediction. We propose a weaker notion of partial exchangeability, better suited to the FL setting, and use it to develop the Federated Conformal Prediction (FCP) framework. We show FCP enjoys rigorous theoretical guarantees and excellent empirical performance on several computer vision and medical imaging datasets. Our results demonstrate a practical approach to incorporating meaningful uncertainty quantification in distributed and heterogeneous environments. We provide code used in our experiments https://github.com/clu5/federated-conformal.
Domain Generalization In Robust Invariant Representation
Apr 07, 2023Unsupervised approaches for learning representations invariant to common transformations are used quite often for object recognition. Learning invariances makes models more robust and practical to use in real-world scenarios. Since data transformations that do not change the intrinsic properties of the object cause the majority of the complexity in recognition tasks, models that are invariant to these transformations help reduce the amount of training data required. This further increases the model's efficiency and simplifies training. In this paper, we investigate the generalization of invariant representations on out-of-distribution data and try to answer the question: Do model representations invariant to some transformations in a particular seen domain also remain invariant in previously unseen domains? Through extensive experiments, we demonstrate that the invariant model learns unstructured latent representations that are robust to distribution shifts, thus making invariance a desirable property for training in resource-constrained settings.
Role of Transients in Two-Bounce Non-Line-of-Sight Imaging
Apr 03, 2023



The goal of non-line-of-sight (NLOS) imaging is to image objects occluded from the camera's field of view using multiply scattered light. Recent works have demonstrated the feasibility of two-bounce (2B) NLOS imaging by scanning a laser and measuring cast shadows of occluded objects in scenes with two relay surfaces. In this work, we study the role of time-of-flight (ToF) measurements, \ie transients, in 2B-NLOS under multiplexed illumination. Specifically, we study how ToF information can reduce the number of measurements and spatial resolution needed for shape reconstruction. We present our findings with respect to tradeoffs in (1) temporal resolution, (2) spatial resolution, and (3) number of image captures by studying SNR and recoverability as functions of system parameters. This leads to a formal definition of the mathematical constraints for 2B lidar. We believe that our work lays an analytical groundwork for design of future NLOS imaging systems, especially as ToF sensors become increasingly ubiquitous.
Scalable Collaborative Learning via Representation Sharing
Dec 13, 2022Privacy-preserving machine learning has become a key conundrum for multi-party artificial intelligence. Federated learning (FL) and Split Learning (SL) are two frameworks that enable collaborative learning while keeping the data private (on device). In FL, each data holder trains a model locally and releases it to a central server for aggregation. In SL, the clients must release individual cut-layer activations (smashed data) to the server and wait for its response (during both inference and back propagation). While relevant in several settings, both of these schemes have a high communication cost, rely on server-level computation algorithms and do not allow for tunable levels of collaboration. In this work, we present a novel approach for privacy-preserving machine learning, where the clients collaborate via online knowledge distillation using a contrastive loss (contrastive w.r.t. the labels). The goal is to ensure that the participants learn similar features on similar classes without sharing their input data. To do so, each client releases averaged last hidden layer activations of similar labels to a central server that only acts as a relay (i.e., is not involved in the training or aggregation of the models). Then, the clients download these last layer activations (feature representations) of the ensemble of users and distill their knowledge in their personal model using a contrastive objective. For cross-device applications (i.e., small local datasets and limited computational capacity), this approach increases the utility of the models compared to independent learning and other federated knowledge distillation (FD) schemes, is communication efficient and is scalable with the number of clients. We prove theoretically that our framework is well-posed, and we benchmark its performance against standard FD and FL on various datasets using different model architectures.
ORCa: Glossy Objects as Radiance Field Cameras
Dec 12, 2022



Reflections on glossy objects contain valuable and hidden information about the surrounding environment. By converting these objects into cameras, we can unlock exciting applications, including imaging beyond the camera's field-of-view and from seemingly impossible vantage points, e.g. from reflections on the human eye. However, this task is challenging because reflections depend jointly on object geometry, material properties, the 3D environment, and the observer viewing direction. Our approach converts glossy objects with unknown geometry into radiance-field cameras to image the world from the object's perspective. Our key insight is to convert the object surface into a virtual sensor that captures cast reflections as a 2D projection of the 5D environment radiance field visible to the object. We show that recovering the environment radiance fields enables depth and radiance estimation from the object to its surroundings in addition to beyond field-of-view novel-view synthesis, i.e. rendering of novel views that are only directly-visible to the glossy object present in the scene, but not the observer. Moreover, using the radiance field we can image around occluders caused by close-by objects in the scene. Our method is trained end-to-end on multi-view images of the object and jointly estimates object geometry, diffuse radiance, and the 5D environment radiance field.
Differentially Private CutMix for Split Learning with Vision Transformer
Oct 28, 2022



Recently, vision transformer (ViT) has started to outpace the conventional CNN in computer vision tasks. Considering privacy-preserving distributed learning with ViT, federated learning (FL) communicates models, which becomes ill-suited due to ViT' s large model size and computing costs. Split learning (SL) detours this by communicating smashed data at a cut-layer, yet suffers from data privacy leakage and large communication costs caused by high similarity between ViT' s smashed data and input data. Motivated by this problem, we propose DP-CutMixSL, a differentially private (DP) SL framework by developing DP patch-level randomized CutMix (DP-CutMix), a novel privacy-preserving inter-client interpolation scheme that replaces randomly selected patches in smashed data. By experiment, we show that DP-CutMixSL not only boosts privacy guarantees and communication efficiency, but also achieves higher accuracy than its Vanilla SL counterpart. Theoretically, we analyze that DP-CutMix amplifies R\'enyi DP (RDP), which is upper-bounded by its Vanilla Mixup counterpart.
Detection and Mapping of Specular Surfaces Using Multibounce Lidar Returns
Sep 07, 2022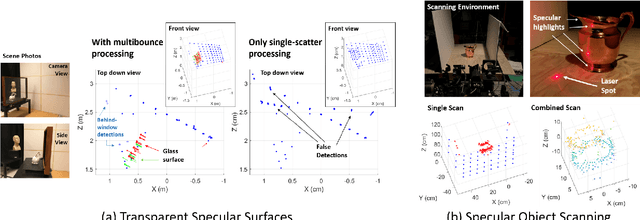
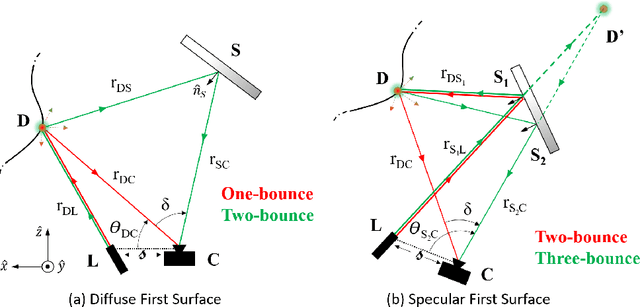
We propose methods that use specular, multibounce lidar returns to detect and map specular surfaces that might be invisible to conventional lidar systems that rely on direct, single-scatter returns. We derive expressions that relate the time- and angle-of-arrival of these multibounce returns to scattering points on the specular surface, and then use these expressions to formulate techniques for retrieving specular surface geometry when the scene is scanned by a single beam or illuminated with a multi-beam flash. We also consider the special case of transparent specular surfaces, for which surface reflections can be mixed together with light that scatters off of objects lying behind the surface.
Fundamentals of Task-Agnostic Data Valuation
Aug 25, 2022
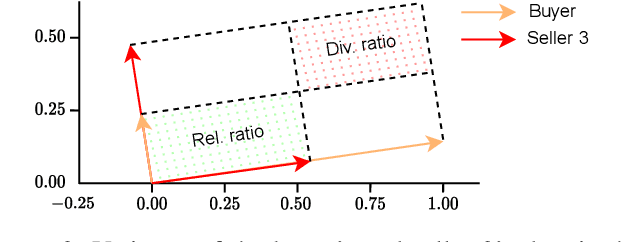
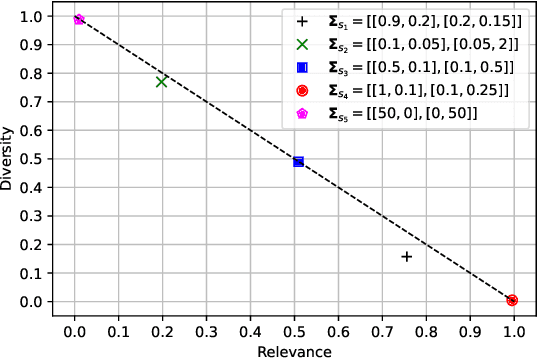
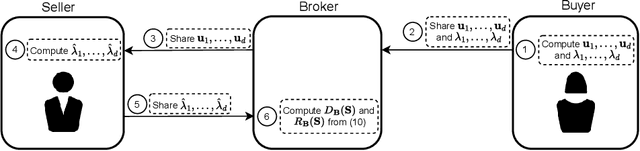
We study valuing the data of a data owner/seller for a data seeker/buyer. Data valuation is often carried out for a specific task assuming a particular utility metric, such as test accuracy on a validation set, that may not exist in practice. In this work, we focus on task-agnostic data valuation without any validation requirements. The data buyer has access to a limited amount of data (which could be publicly available) and seeks more data samples from a data seller. We formulate the problem as estimating the differences in the statistical properties of the data at the seller with respect to the baseline data available at the buyer. We capture these statistical differences through second moment by measuring diversity and relevance of the seller's data for the buyer; we estimate these measures through queries to the seller without requesting raw data. We design the queries with the proposed approach so that the seller is blind to the buyer's raw data and has no knowledge to fabricate responses to queries to obtain a desired outcome of the diversity and relevance trade-off.We will show through extensive experiments on real tabular and image datasets that the proposed estimates capture the diversity and relevance of the seller's data for the buyer.