 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuscleMap: Towards Video-based Activated Muscle Group Estimation
Mar 17, 2023



In this paper, we tackle the new task of video-based Activated Muscle Group Estimation (AMGE) aiming at identifying active muscle regions during physical activity. To this intent, we provide the MuscleMap136 dataset featuring >15K video clips with 136 different activities and 20 labeled muscle groups. This dataset opens the vistas to multiple video-based applications in sports and rehabilitation medicine. We further complement the main MuscleMap136 dataset, which specifically targets physical exercise, with Muscle-UCF90 and Muscle-HMDB41, which are new variants of the well-known activity recognition benchmarks extended with AMGE annotations. To make the AMGE model applicable in real-life situations, it is crucial to ensure that the model can generalize well to types of physical activities not present during training and involving new combinations of activated muscles. To achieve this, our benchmark also covers an evaluation setting where the model is exposed to activity types excluded from the training set. Our experiments reveal that generalizability of existing architectures adapted for the AMGE task remains a challenge. Therefore, we also propose a new approach, TransM3E, which employs a transformer-based model with cross-modal multi-label knowledge distillation and surpasses all popular video classification models when dealing with both, previously seen and new types of physical activities. The datasets and code will be publicly available at https://github.com/KPeng9510/MuscleMap.
Mirror U-Net: Marrying Multimodal Fission with Multi-task Learning for Semantic Segmentation in Medical Imaging
Mar 13, 2023



Positron Emission Tomography (PET) and Computer Tomography (CT) are routinely used together to detect tumors. PET/CT segmentation models can automate tumor delineation, however, current multimodal models do not fully exploit the complementary information in each modality, as they either concatenate PET and CT data or fuse them at the decision level. To combat this, we propose Mirror U-Net, which replaces traditional fusion methods with multimodal fission by factorizing the multimodal representation into modality-specific branches and an auxiliary multimodal decoder. At these branches, Mirror U-Net assigns a task tailored to each modality to reinforce unimodal features while preserving multimodal features in the shared representation. In contrast to previous methods that use either fission or multi-task learning, Mirror U-Net combines both paradigms in a unified framework. We explore various task combinations and examine which parameters to share in the model. We evaluate Mirror U-Net on the AutoPET PET/CT and on the multimodal MSD BrainTumor datasets, demonstrating its effectiveness in multimodal segmentation and achieving state-of-the-art performance on both datasets. Our code will be made publicly available.
Guiding the Guidance: A Comparative Analysis of User Guidance Signals for Interactive Segmentation of Volumetric Images
Mar 13, 2023Interactive segmentation reduces the annotation time of medical images and allows annotators to iteratively refine labels with corrective interactions, such as clicks. While existing interactive models transform clicks into user guidance signals, which are combined with images to form (image, guidance) pairs, the question of how to best represent the guidance has not been fully explored. To address this, we conduct a comparative study of existing guidance signals by training interactive models with different signals and parameter settings to identify crucial parameters for the model's design. Based on our findings, we design a guidance signal that retains the benefits of other signals while addressing their limitations. We propose an adaptive Gaussian heatmaps guidance signal that utilizes the geodesic distance transform to dynamically adapt the radius of each heatmap when encoding clicks. We conduct our study on the MSD Spleen and the AutoPET datasets to explore the segmentation of both anatomy (spleen) and pathology (tumor lesions). Our results show that choosing the guidance signal is crucial for interactive segmentation as we improve the performance by 14% Dice with our adaptive heatmaps on the challenging AutoPET dataset when compared to non-interactive models. This brings interactive models one step closer to deployment on clinical workflows. We will make our code publically available.
Delivering Arbitrary-Modal Semantic Segmentation
Mar 02, 2023



Multimodal fusion can make semantic segmentation more robust. However, fusing an arbitrary number of modalities remains underexplored. To delve into this problem, we create the DeLiVER arbitrary-modal segmentation benchmark, covering Depth, LiDAR, multiple Views, Events, and RGB. Aside from this, we provide this dataset in four severe weather conditions as well as five sensor failure cases to exploit modal complementarity and resolve partial outages. To make this possible, we present the arbitrary cross-modal segmentation model CMNeXt. It encompasses a Self-Query Hub (SQ-Hub) designed to extract effective information from any modality for subsequent fusion with the RGB representation and adds only negligible amounts of parameters (~0.01M) per additional modality. On top, to efficiently and flexibly harvest discriminative cues from the auxiliary modalities, we introduce the simple Parallel Pooling Mixer (PPX). With extensive experiments on a total of six benchmarks, our CMNeXt achieves state-of-the-art performance on the DeLiVER, KITTI-360, MFNet, NYU Depth V2, UrbanLF, and MCubeS datasets, allowing to scale from 1 to 81 modalities. On the freshly collected DeLiVER, the quad-modal CMNeXt reaches up to 66.30% in mIoU with a +9.10% gain as compared to the mono-modal baseline. The DeLiVER dataset and our code are at: https://jamycheung.github.io/DELIVER.html.
MateRobot: Material Recognition in Wearable Robotics for People with Visual Impairments
Feb 28, 2023



Wearable robotics can improve the lives of People with Visual Impairments (PVI) by providing additional sensory information. Blind people typically recognize objects through haptic perception. However, knowing materials before touching is under-explored in the field of assistive technology. To fill this gap, in this work, a wearable robotic system, MateRobot, is established for PVI to recognize materials before hand. Specially, the human-centric system can perform pixel-wise semantic segmentation of objects and materials. Considering both general object segmentation and material segmentation, an efficient MateViT architecture with Learnable Importance Sampling (LIS) and Multi-gate Mixture-of-Experts (MMoE) is proposed to wearable robots to achieve complementary gains from different target domains. Our methods achieve respective 40.2% and 51.1% of mIoU on COCOStuff and DMS datasets, surpassing previous method with +5.7% and +7.0% gains. Moreover, on the field test with participants, our wearable system obtains a score of 28 in NASA-Task Load Index, indicating low cognitive demands and ease of use. Our MateRobot demonstrates the feasibility of recognizing material properties through visual cues, and offers a promising step towards improving the functionality of wearable robots for PVI. Code will be available at: https://github.com/JunweiZheng93/MATERobot.
Multimodal Interactive Lung Lesion Segmentation: A Framework for Annotating PET/CT Images based on Physiological and Anatomical Cues
Jan 24, 2023



Recently, deep learning enabled the accurate segmentation of various diseases in medical imaging. These performances, however, typically demand large amounts of manual voxel annotations. This tedious process for volumetric data becomes more complex when not all required information is available in a single imaging domain as is the case for PET/CT data. We propose a multimodal interactive segmentation framework that mitigates these issues by combining anatomical and physiological cues from PET/CT data. Our framework utilizes the geodesic distance transform to represent the user annotations and we implement a novel ellipsoid-based user simulation scheme during training. We further propose two annotation interfaces and conduct a user study to estimate their usability. We evaluated our model on the in-domain validation dataset and an unseen PET/CT dataset. We make our code publicly available: https://github.com/verena-hallitschke/pet-ct-annotate.
Uncertainty-aware Vision-based Metric Cross-view Geolocalization
Nov 22, 2022This paper proposes a novel method for vision-based metric cross-view geolocalization (CVGL) that matches the camera images captured from a ground-based vehicle with an aerial image to determine the vehicle's geo-pose. Since aerial images are globally available at low cost, they represent a potential compromise between two established paradigms of autonomous driving, i.e. using expensive high-definition prior maps or relying entirely on the sensor data captured at runtime. We present an end-to-end differentiable model that uses the ground and aerial images to predict a probability distribution over possible vehicle poses. We combine multiple vehicle datasets with aerial images from orthophoto providers on which we demonstrate the feasibility of our method. Since the ground truth poses are often inaccurate w.r.t. the aerial images, we implement a pseudo-label approach to produce more accurate ground truth poses and make them publicly available. While previous works require training data from the target region to achieve reasonable localization accuracy (i.e. same-area evaluation), our approach overcomes this limitation and outperforms previous results even in the strictly more challenging cross-area case. We improve the previous state-of-the-art by a large margin even without ground or aerial data from the test region, which highlights the model's potential for global-scale application. We further integrate the uncertainty-aware predictions in a tracking framework to determine the vehicle's trajectory over time resulting in a mean position error on KITTI-360 of 0.78m.
Anticipative Feature Fusion Transformer for Multi-Modal Action Anticipation
Oct 23, 2022



Although human action anticipation is a task which is inherently multi-modal, state-of-the-art methods on well known action anticipation datasets leverage this data by applying ensemble methods and averaging scores of unimodal anticipation networks. In this work we introduce transformer based modality fusion techniques, which unify multi-modal data at an early stage. Our Anticipative Feature Fusion Transformer (AFFT) proves to be superior to popular score fusion approaches and presents state-of-the-art results outperforming previous methods on EpicKitchens-100 and EGTEA Gaze+. Our model is easily extensible and allows for adding new modalities without architectural changes. Consequently, we extracted audio features on EpicKitchens-100 which we add to the set of commonly used features in the community.
Detailed Annotations of Chest X-Rays via CT Projection for Report Understanding
Oct 07, 2022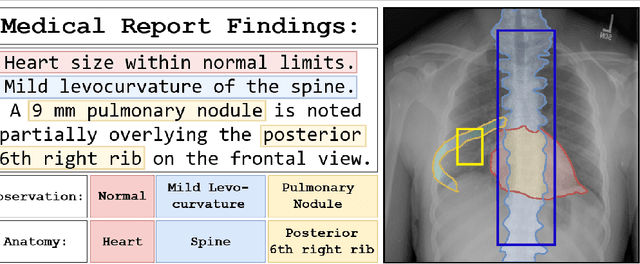
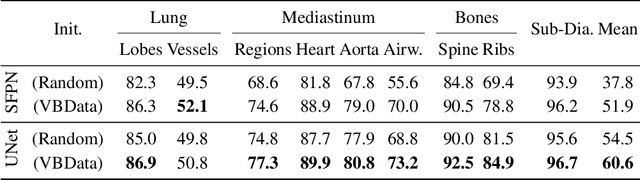
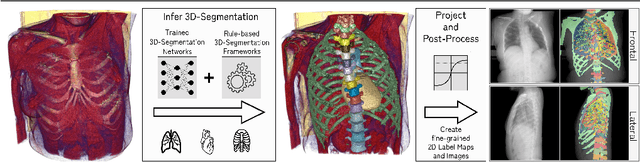
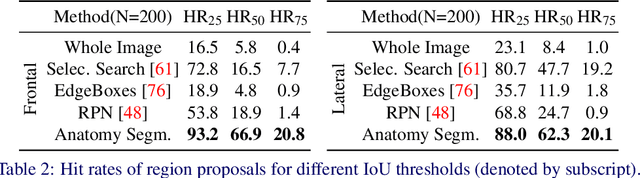
In clinical radiology reports, doctors capture important information about the patient's health status. They convey their observations from raw medical imaging data about the inner structures of a patient. As such, formulating reports requires medical experts to possess wide-ranging knowledge about anatomical regions with their normal, healthy appearance as well as the ability to recognize abnormalities. This explicit grasp on both the patient's anatomy and their appearance is missing in current medical image-processing systems as annotations are especially difficult to gather. This renders the models to be narrow experts e.g. for identifying specific diseases. In this work, we recover this missing link by adding human anatomy into the mix and enable the association of content in medical reports to their occurrence in associated imagery (medical phrase grounding). To exploit anatomical structures in this scenario, we present a sophisticated automatic pipeline to gather and integrate human bodily structures from computed tomography datasets, which we incorporate in our PAXRay: A Projected dataset for the segmentation of Anatomical structures in X-Ray data. Our evaluation shows that methods that take advantage of anatomical information benefit heavily in visually grounding radiologists' findings, as our anatomical segmentations allow for up to absolute 50% better grounding results on the OpenI dataset as compared to commonly used region proposals. The PAXRay dataset is available at https://constantinseibold.github.io/paxray/.
AutoPET Challenge: Combining nn-Unet with Swin UNETR Augmented by Maximum Intensity Projection Classifier
Sep 02, 2022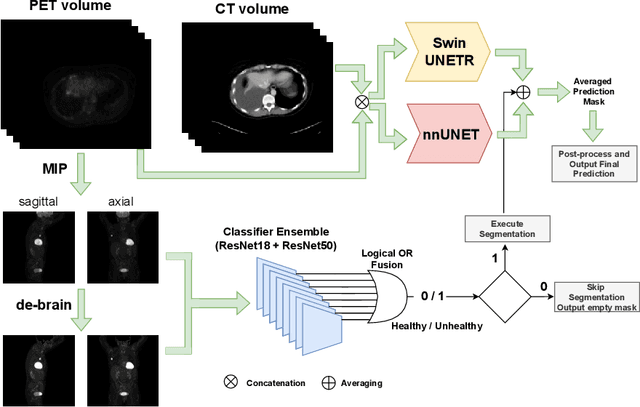
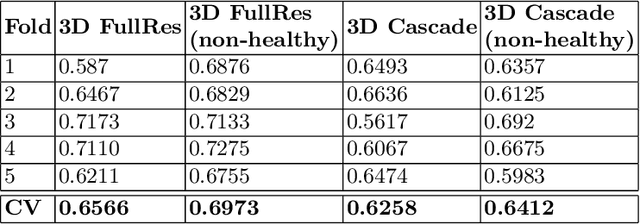
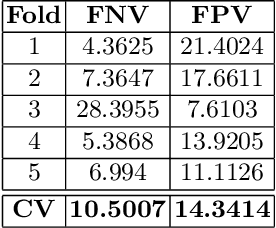
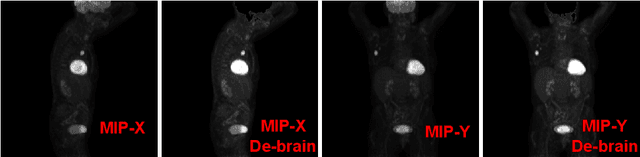
Tumor volume and changes in tumor characteristics over time are important biomarkers for cancer therapy. In this context, FDG-PET/CT scans are routinely used for staging and re-staging of cancer, as the radiolabeled fluorodeoxyglucose is taken up in regions of high metabolism. Unfortunately, these regions with high metabolism are not specific to tumors and can also represent physiological uptake by normal functioning organs, inflammation, or infection, making detailed and reliable tumor segmentation in these scans a demanding task. This gap in research is addressed by the AutoPET challenge, which provides a public data set with FDG-PET/CT scans from 900 patients to encourage further improvement in this field. Our contribution to this challenge is an ensemble of two state-of-the-art segmentation models, the nn-Unet and the Swin UNETR, augmented by a maximum intensity projection classifier that acts like a gating mechanism. If it predicts the existence of lesions, both segmentations are combined by a late fusion approach. Our solution achieves a Dice score of 72.12\% on patients diagnosed with lung cancer, melanoma, and lymphoma in our cross-validation. Code: https://github.com/heiligerl/autopet_submission