 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multimodal Safety via Conditional Decoding
Mar 31, 2026Multimodal large-language models (MLLMs) often experience degraded safety alignment when harmful queries exploit cross-modal interactions. Models aligned on text alone show a higher rate of successful attacks when extended to two or more modalities. In this work, we propose a simple conditional decoding strategy, CASA (Classification Augmented with Safety Attention) that utilizes internal representations of MLLMs to predict a binary safety token before response generation. We introduce a novel safety attention module designed to enhance the model's ability to detect malicious queries. Our design ensures robust safety alignment without relying on any external classifier or auxiliary head, and without the need for modality-specific safety fine-tuning. On diverse benchmarks such as MM-SafetyBench, JailbreakV-28k, and adversarial audio tests, CASA lowers the average attack success rate by more than 97% across modalities and across attack types. Our empirical evaluations also show that CASA maintains strong utility in benign inputs, a result validated through both automated and human evaluations (via 13 trained annotators). Together, these results highlight CASA as a simple and generalizable framework to improve multimodal LLM safety.
Unsupervised Clustered Federated Learning in Complex Multi-source Acoustic Environments
Jun 07, 2021
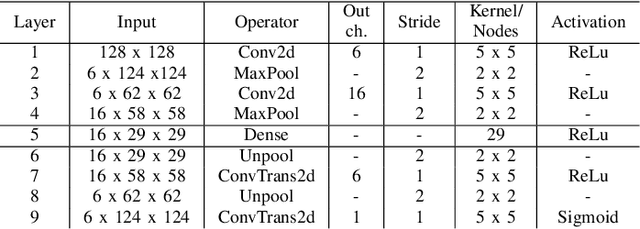

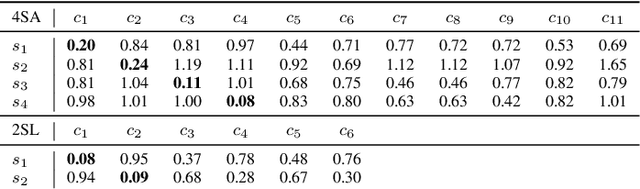
In this paper we introduce a realistic and challenging, multi-source and multi-room acoustic environment and an improved algorithm for the estimation of source-dominated microphone clusters in acoustic sensor networks. Our proposed clustering method is based on a single microphone per node and on unsupervised clustered federated learning which employs a light-weight autoencoder model. We present an improved clustering control strategy that takes into account the variability of the acoustic scene and allows the estimation of a dynamic range of clusters using reduced amounts of training data. The proposed approach is optimized using clustering-based measures and validated via a network-wide classification task.
Estimation of Microphone Clusters in Acoustic Sensor Networks using Unsupervised Federated Learning
Feb 15, 2021


In this paper we present a privacy-aware method for estimating source-dominated microphone clusters in the context of acoustic sensor networks (ASNs). The approach is based on clustered federated learning which we adapt to unsupervised scenarios by employing a light-weight autoencoder model. The model is further optimized for training on very scarce data. In order to best harness the benefits of clustered microphone nodes in ASN applications, a method for the computation of cluster membership values is introduced. We validate the performance of the proposed approach using clustering-based measures and a network-wide classification task.