 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom STL Rulebooks to Rewards
Oct 06, 2021


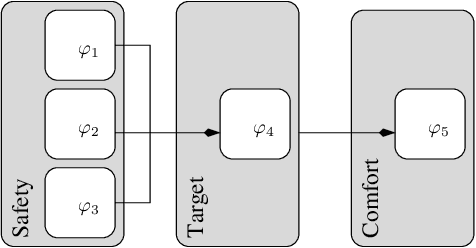
The automatic synthesis of neural-network controllers for autonomous agents through reinforcement learning has to simultaneously optimize many, possibly conflicting, objectives of various importance. This multi-objective optimization task is reflected in the shape of the reward function, which is most often the result of an ad-hoc and crafty-like activity. In this paper we propose a principled approach to shaping rewards for reinforcement learning from multiple objectives that are given as a partially-ordered set of signal-temporal-logic (STL) rules. To this end, we first equip STL with a novel quantitative semantics allowing to automatically evaluate individual requirements. We then develop a method for systematically combining evaluations of multiple requirements into a single reward that takes into account the priorities defined by the partial order. We finally evaluate our approach on several case studies, demonstrating its practical applicability.
From English to Signal Temporal Logic
Sep 21, 2021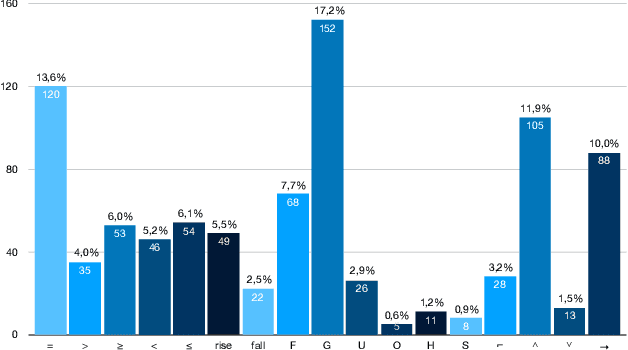

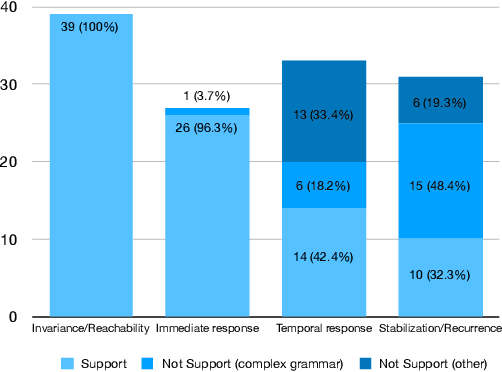

Formal methods provide very powerful tools and techniques for the design and analysis of complex systems. Their practical application remains however limited, due to the widely accepted belief that formal methods require extensive expertise and a steep learning curve. Writing correct formal specifications in form of logical formulas is still considered to be a difficult and error prone task. In this paper we propose DeepSTL, a tool and technique for the translation of informal requirements, given as free English sentences, into Signal Temporal Logic (STL), a formal specification language for cyber-physical systems, used both by academia and advanced research labs in industry. A major challenge to devise such a translator is the lack of publicly available informal requirements and formal specifications. We propose a two-step workflow to address this challenge. We first design a grammar-based generation technique of synthetic data, where each output is a random STL formula and its associated set of possible English translations. In the second step, we use a state-of-the-art transformer-based neural translation technique, to train an accurate attentional translator of English to STL. The experimental results show high translation quality for patterns of English requirements that have been well trained, making this workflow promising to be extended for processing more complex translation tasks.
GoTube: Scalable Stochastic Verification of Continuous-Depth Models
Jul 18, 2021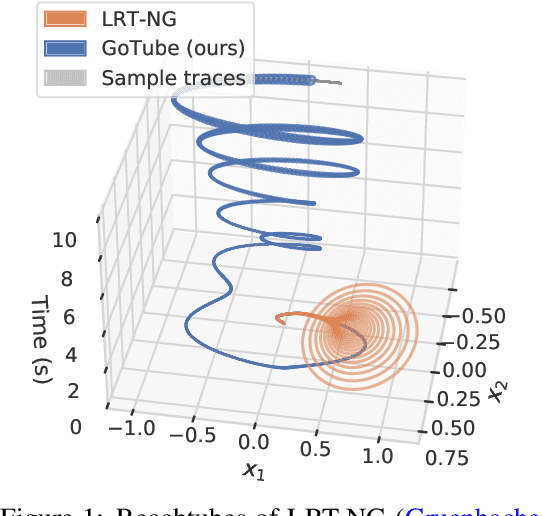
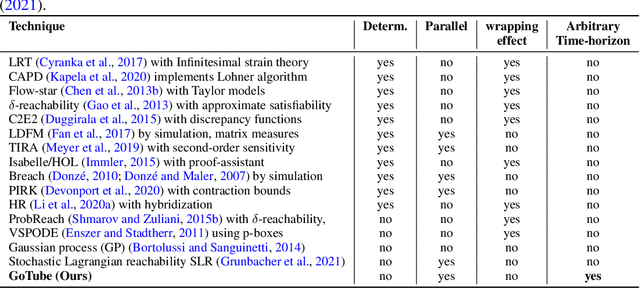
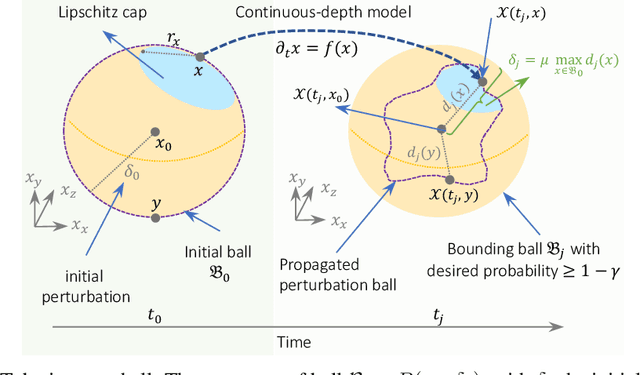
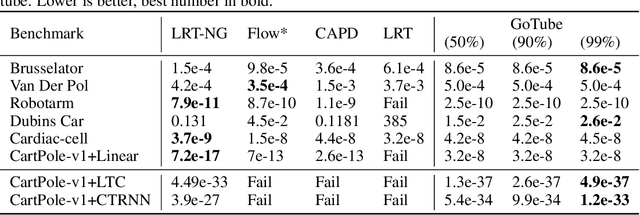
We introduce a new stochastic verification algorithm that formally quantifies the behavioral robustness of any time-continuous process formulated as a continuous-depth model. The algorithm solves a set of global optimization (Go) problems over a given time horizon to construct a tight enclosure (Tube) of the set of all process executions starting from a ball of initial states. We call our algorithm GoTube. Through its construction, GoTube ensures that the bounding tube is conservative up to a desired probability. GoTube is implemented in JAX and optimized to scale to complex continuous-depth models. Compared to advanced reachability analysis tools for time-continuous neural networks, GoTube provably does not accumulate over-approximation errors between time steps and avoids the infamous wrapping effect inherent in symbolic techniques. We show that GoTube substantially outperforms state-of-the-art verification tools in terms of the size of the initial ball, speed, time-horizon, task completion, and scalability, on a large set of experiments. GoTube is stable and sets the state-of-the-art for its ability to scale up to time horizons well beyond what has been possible before.
On-Off Center-Surround Receptive Fields for Accurate and Robust Image Classification
Jun 13, 2021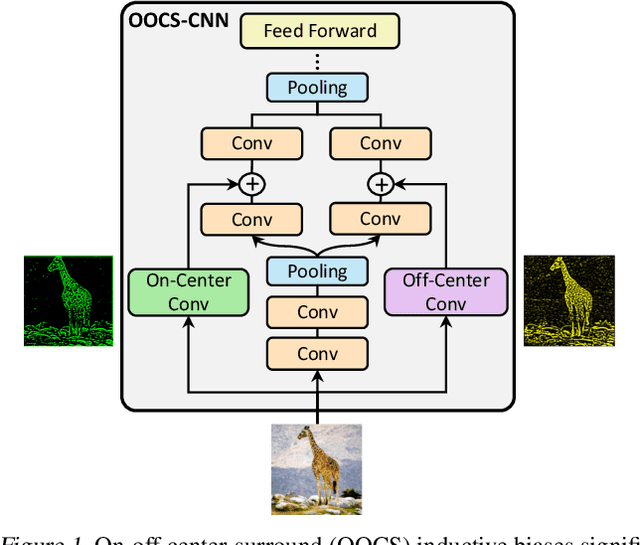
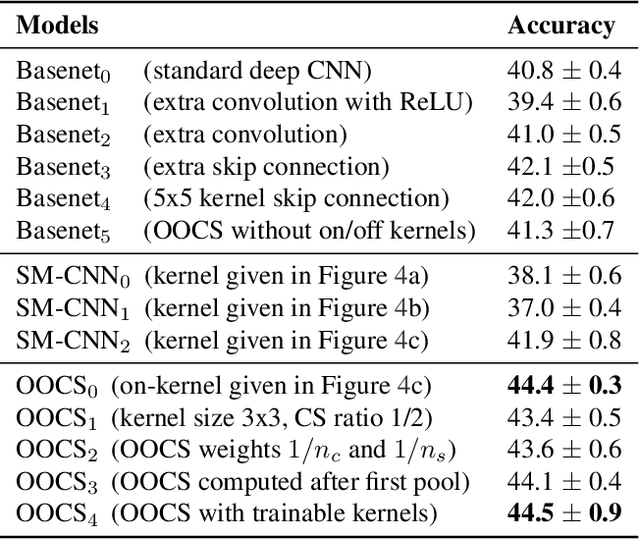
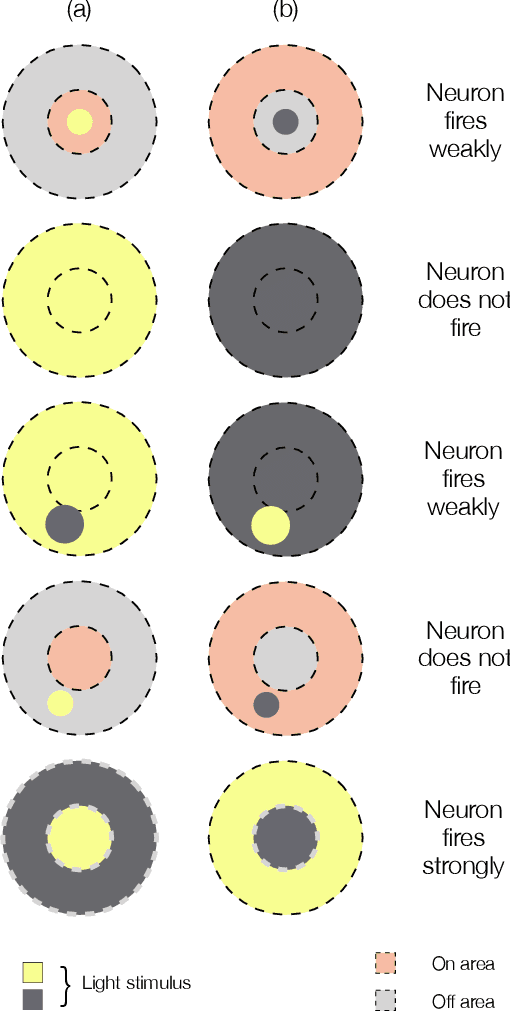

Robustness to variations in lighting conditions is a key objective for any deep vision system. To this end, our paper extends the receptive field of convolutional neural networks with two residual components, ubiquitous in the visual processing system of vertebrates: On-center and off-center pathways, with excitatory center and inhibitory surround; OOCS for short. The on-center pathway is excited by the presence of a light stimulus in its center but not in its surround, whereas the off-center one is excited by the absence of a light stimulus in its center but not in its surround. We design OOCS pathways via a difference of Gaussians, with their variance computed analytically from the size of the receptive fields. OOCS pathways complement each other in their response to light stimuli, ensuring this way a strong edge-detection capability, and as a result, an accurate and robust inference under challenging lighting conditions. We provide extensive empirical evidence showing that networks supplied with the OOCS edge representation gain accuracy and illumination-robustness compared to standard deep models.
Adversarial Training is Not Ready for Robot Learning
Mar 15, 2021



Adversarial training is an effective method to train deep learning models that are resilient to norm-bounded perturbations, with the cost of nominal performance drop. While adversarial training appears to enhance the robustness and safety of a deep model deployed in open-world decision-critical applications, counterintuitively, it induces undesired behaviors in robot learning settings. In this paper, we show theoretically and experimentally that neural controllers obtained via adversarial training are subjected to three types of defects, namely transient, systematic, and conditional errors. We first generalize adversarial training to a safety-domain optimization scheme allowing for more generic specifications. We then prove that such a learning process tends to cause certain error profiles. We support our theoretical results by a thorough experimental safety analysis in a robot-learning task. Our results suggest that adversarial training is not yet ready for robot learning.
Model-based versus Model-free Deep Reinforcement Learning for Autonomous Racing Cars
Mar 08, 2021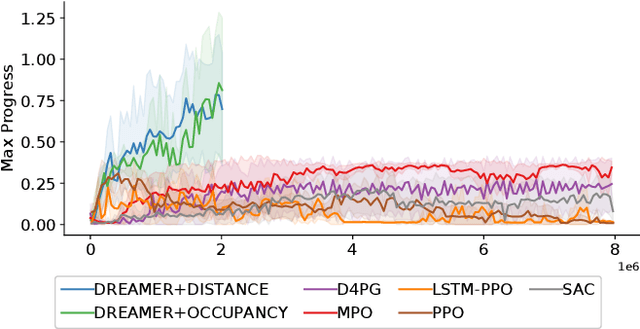
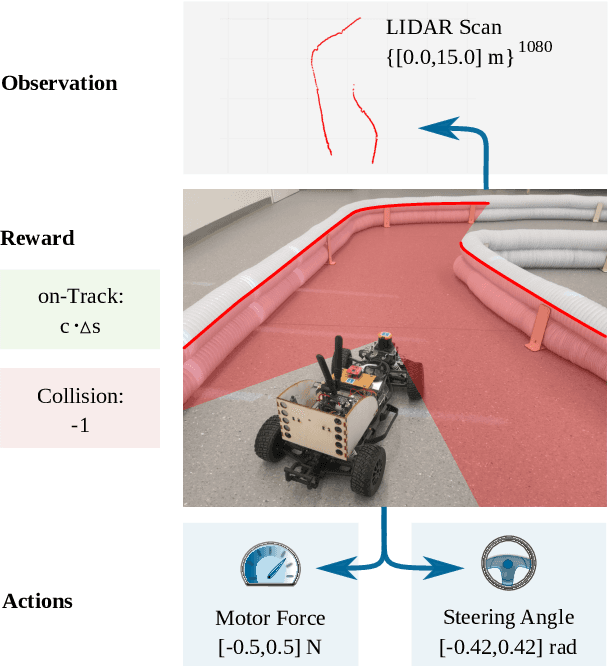

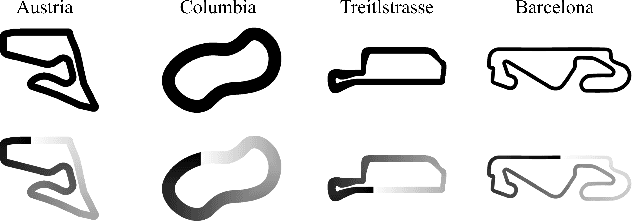
Despite the rich theoretical foundation of model-based deep reinforcement learning (RL) agents, their effectiveness in real-world robotics-applications is less studied and understood. In this paper, we, therefore, investigate how such agents generalize to real-world autonomous-vehicle control-tasks, where advanced model-free deep RL algorithms fail. In particular, we set up a series of time-lap tasks for an F1TENTH racing robot, equipped with high-dimensional LiDAR sensors, on a set of test tracks with a gradual increase in their complexity. In this continuous-control setting, we show that model-based agents capable of learning in imagination, substantially outperform model-free agents with respect to performance, sample efficiency, successful task completion, and generalization. Moreover, we show that the generalization ability of model-based agents strongly depends on the observation-model choice. Finally, we provide extensive empirical evidence for the effectiveness of model-based agents provided with long enough memory horizons in sim2real tasks.
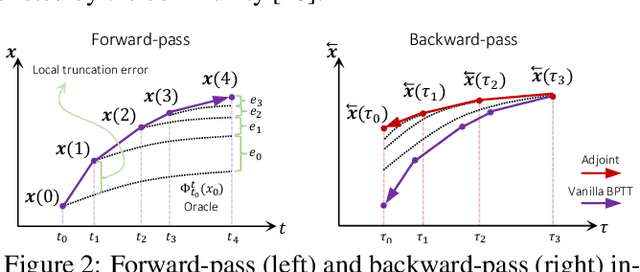
On The Verification of Neural ODEs with Stochastic Guarantees
Dec 16, 2020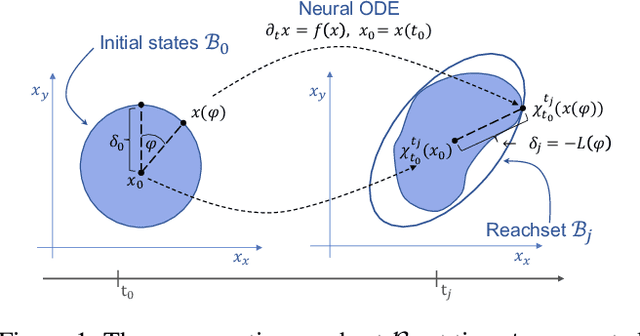
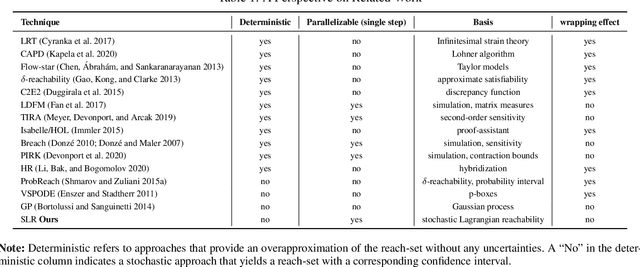
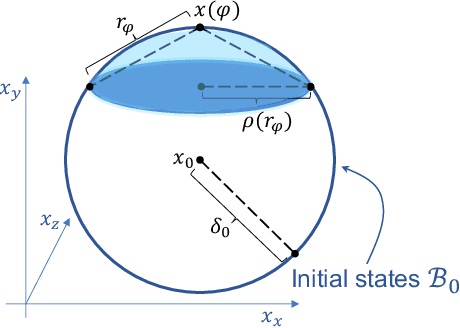
We show that Neural ODEs, an emerging class of time-continuous neural networks, can be verified by solving a set of global-optimization problems. For this purpose, we introduce Stochastic Lagrangian Reachability (SLR), an abstraction-based technique for constructing a tight Reachtube (an over-approximation of the set of reachable states over a given time-horizon), and provide stochastic guarantees in the form of confidence intervals for the Reachtube bounds. SLR inherently avoids the infamous wrapping effect (accumulation of over-approximation errors) by performing local optimization steps to expand safe regions instead of repeatedly forward-propagating them as is done by deterministic reachability methods. To enable fast local optimizations, we introduce a novel forward-mode adjoint sensitivity method to compute gradients without the need for backpropagation. Finally, we establish asymptotic and non-asymptotic convergence rates for SLR.
Lagrangian Reachtubes: The Next Generation
Dec 14, 2020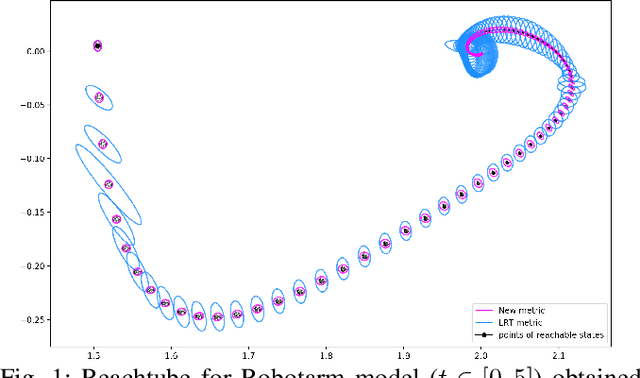
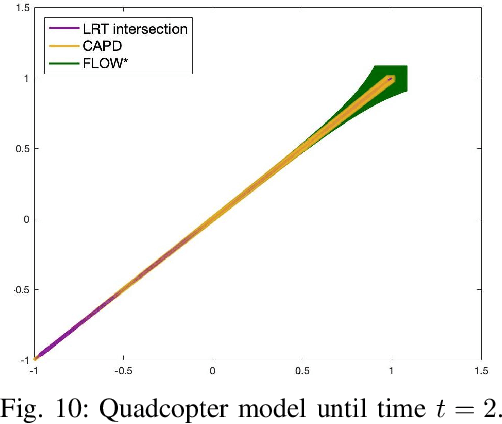


We introduce LRT-NG, a set of techniques and an associated toolset that computes a reachtube (an over-approximation of the set of reachable states over a given time horizon) of a nonlinear dynamical system. LRT-NG significantly advances the state-of-the-art Langrangian Reachability and its associated tool LRT. From a theoretical perspective, LRT-NG is superior to LRT in three ways. First, it uses for the first time an analytically computed metric for the propagated ball which is proven to minimize the ball's volume. We emphasize that the metric computation is the centerpiece of all bloating-based techniques. Secondly, it computes the next reachset as the intersection of two balls: one based on the Cartesian metric and the other on the new metric. While the two metrics were previously considered opposing approaches, their joint use considerably tightens the reachtubes. Thirdly, it avoids the "wrapping effect" associated with the validated integration of the center of the reachset, by optimally absorbing the interval approximation in the radius of the next ball. From a tool-development perspective, LRT-NG is superior to LRT in two ways. First, it is a standalone tool that no longer relies on CAPD. This required the implementation of the Lohner method and a Runge-Kutta time-propagation method. Secondly, it has an improved interface, allowing the input model and initial conditions to be provided as external input files. Our experiments on a comprehensive set of benchmarks, including two Neural ODEs, demonstrates LRT-NG's superior performance compared to LRT, CAPD, and Flow*.
Liquid Time-constant Networks
Jun 08, 2020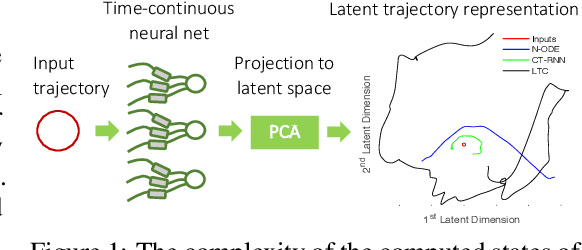

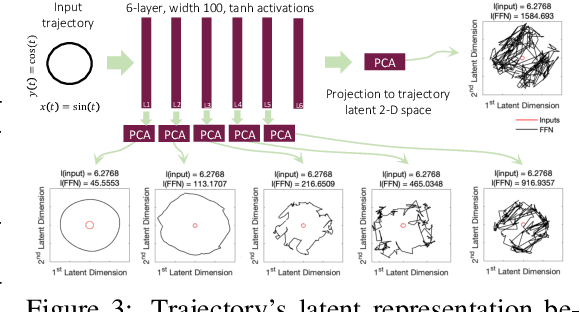
We introduce a new class of time-continuous recurrent neural network models. Instead of declaring the nonlinearity of a learning system by neurons, we impose specialized nonlinearities on the network connections. The obtained models realize dynamical systems with varying (i.e., \emph{liquid}) time-constants coupled to their hidden state, and outputs being computed by numerical differential equation solvers. These neural networks exhibit stable and bounded behavior, yield superior expressivity within the family of neural ordinary differential equations, and give rise to improved performance on time-series prediction tasks. To demonstrate these properties, we first take a theoretical approach to find bounds over their dynamics, and compute their expressive power by the \emph{trajectory length} measure in a latent trajectory representation space. We then conduct a series of time-series prediction experiments to manifest the approximation capability of Liquid Time-Constant Networks (LTCs) compared to classical and modern RNNs.
ResNets, NeuralODEs and CT-RNNs are Particular Neural Regulatory Networks
Mar 19, 2020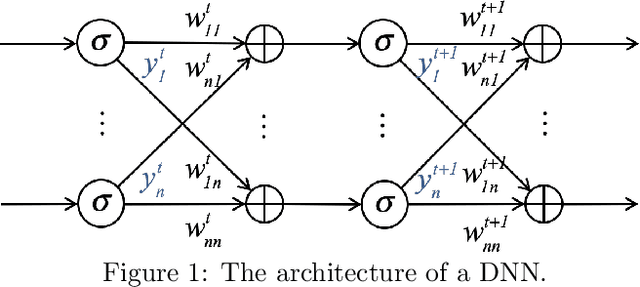
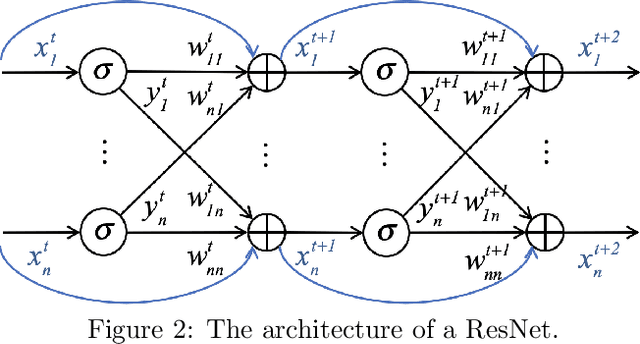
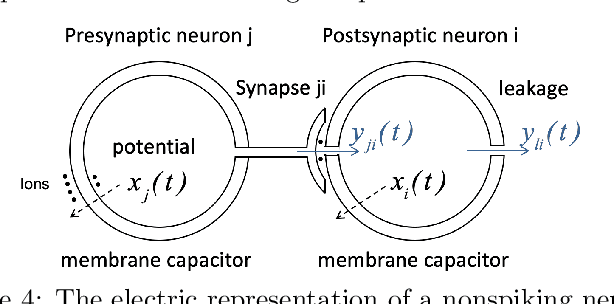
This paper shows that ResNets, NeuralODEs, and CT-RNNs, are particular neural regulatory networks (NRNs), a biophysical model for the nonspiking neurons encountered in small species, such as the C.elegans nematode, and in the retina of large species. Compared to ResNets, NeuralODEs and CT-RNNs, NRNs have an additional multiplicative term in their synaptic computation, allowing them to adapt to each particular input. This additional flexibility makes NRNs $M$ times more succinct than NeuralODEs and CT-RNNs, where $M$ is proportional to the size of the training set. Moreover, as NeuralODEs and CT-RNNs are $N$ times more succinct than ResNets, where $N$ is the number of integration steps required to compute the output $F(x)$ for a given input $x$, NRNs are in total $M\,{\cdot}\,N$ more succinct than ResNets. For a given approximation task, this considerable succinctness allows to learn a very small and therefore understandable NRN, whose behavior can be explained in terms of well established architectural motifs, that NRNs share with gene regulatory networks, such as, activation, inhibition, sequentialization, mutual exclusion, and synchronization. To the best of our knowledge, this paper unifies for the first time the mainstream work on deep neural networks with the one in biology and neuroscience in a quantitative fashion.