 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Safe Learning-Based Non-Linear Model Predictive Control through Recurrent Neural Network Modeling
Mar 25, 2026The practical deployment of nonlinear model predictive control (NMPC) is often limited by online computation: solving a nonlinear program at high control rates can be expensive on embedded hardware, especially when models are complex or horizons are long. Learning-based NMPC approximations shift this computation offline but typically demand large expert datasets and costly training. We propose Sequential-AMPC, a sequential neural policy that generates MPC candidate control sequences by sharing parameters across the prediction horizon. For deployment, we wrap the policy in a safety-augmented online evaluation and fallback mechanism, yielding Safe Sequential-AMPC. Compared to a naive feedforward policy baseline across several benchmarks, Sequential-AMPC requires substantially fewer expert MPC rollouts and yields candidate sequences with higher feasibility rates and improved closed-loop safety. On high-dimensional systems, it also exhibits better learning dynamics and performance in fewer epochs while maintaining stable validation improvement where the feedforward baseline can stagnate.
Declarative Scenario-based Testing with RoadLogic
Mar 10, 2026Scenario-based testing is a key method for cost-effective and safe validation of autonomous vehicles (AVs). Existing approaches rely on imperative scenario definitions, requiring developers to manually enumerate numerous variants to achieve coverage. Declarative languages, such as OpenSCENARIO DSL (OS2), raise the abstraction level but lack systematic methods for instantiating concrete, specification-compliant scenarios as simulations. To our knowledge, currently, no open-source solution provides this capability. We present RoadLogic that bridges declarative OS2 specifications and executable simulations. It uses Answer Set Programming to generate abstract plans satisfying scenario constraints, motion planning to refine the plans into feasible trajectories, and specification-based monitoring to verify correctness. We evaluate RoadLogic on instantiating representative OS2 scenarios as simulations in the CommonRoad framework. Results show that RoadLogic consistently produces realistic, specification-satisfying simulations within minutes and captures diverse behavioral variants through parameter sampling, thus opening the door to systematic scenario-based testing for autonomous driving systems.
GreenServ: Energy-Efficient Context-Aware Dynamic Routing for Multi-Model LLM Inference
Jan 24, 2026Large language models (LLMs) demonstrate remarkable capabilities, but their broad deployment is limited by significant computational resource demands, particularly energy consumption during inference. Static, one-model-fits-all inference strategies are often inefficient, as they do not exploit the diverse range of available models or adapt to varying query requirements. This paper presents GreenServ, a dynamic, context-aware routing framework that optimizes the trade-off between inference accuracy and energy efficiency. GreenServ extracts lightweight contextual features from each query, including task type, semantic cluster, and text complexity, and routes queries to the most suitable model from a heterogeneous pool, based on observed accuracy and energy usage. We employ a multi-armed bandit approach to learn adaptive routing policies online. This approach operates under partial feedback, eliminates the need for extensive offline calibration, and streamlines the integration of new models into the inference pipeline. We evaluated GreenServ across five benchmark tasks and a pool of 16 contemporary open-access LLMs. Experimental results show that GreenServ consistently outperforms static (single-model) and random baselines. In particular, compared to random routing, GreenServ achieved a 22% increase in accuracy while reducing cumulative energy consumption by 31%. Finally, we evaluated GreenServ with RouterBench, achieving an average accuracy of 71.7% with a peak accuracy of 75.7%. All artifacts are open-source and available as an anonymous repository for review purposes here: https://anonymous.4open.science/r/llm-inference-router-EBEA/README.md
Rule-Guided Reinforcement Learning Policy Evaluation and Improvement
Mar 12, 2025We consider the challenging problem of using domain knowledge to improve deep reinforcement learning policies. To this end, we propose LEGIBLE, a novel approach, following a multi-step process, which starts by mining rules from a deep RL policy, constituting a partially symbolic representation. These rules describe which decisions the RL policy makes and which it avoids making. In the second step, we generalize the mined rules using domain knowledge expressed as metamorphic relations. We adapt these relations from software testing to RL to specify expected changes of actions in response to changes in observations. The third step is evaluating generalized rules to determine which generalizations improve performance when enforced. These improvements show weaknesses in the policy, where it has not learned the general rules and thus can be improved by rule guidance. LEGIBLE supported by metamorphic relations provides a principled way of expressing and enforcing domain knowledge about RL environments. We show the efficacy of our approach by demonstrating that it effectively finds weaknesses, accompanied by explanations of these weaknesses, in eleven RL environments and by showcasing that guiding policy execution with rules improves performance w.r.t. gained reward.
Exact Upper and Lower Bounds for the Output Distribution of Neural Networks with Random Inputs
Feb 17, 2025We derive exact upper and lower bounds for the cumulative distribution function (cdf) of the output of a neural network over its entire support subject to noisy (stochastic) inputs. The upper and lower bounds converge to the true cdf over its domain as the resolution increases. Our method applies to any feedforward NN using continuous monotonic piecewise differentiable activation functions (e.g., ReLU, tanh and softmax) and convolutional NNs, which were beyond the scope of competing approaches. The novelty and an instrumental tool of our approach is to bound general NNs with ReLU NNs. The ReLU NN based bounds are then used to derive upper and lower bounds of the cdf of the NN output. Experiments demonstrate that our method delivers guaranteed bounds of the predictive output distribution over its support, thus providing exact error guarantees, in contrast to competing approaches.
An Energy-Aware Approach to Design Self-Adaptive AI-based Applications on the Edge
Aug 31, 2023



The advent of edge devices dedicated to machine learning tasks enabled the execution of AI-based applications that efficiently process and classify the data acquired by the resource-constrained devices populating the Internet of Things. The proliferation of such applications (e.g., critical monitoring in smart cities) demands new strategies to make these systems also sustainable from an energetic point of view. In this paper, we present an energy-aware approach for the design and deployment of self-adaptive AI-based applications that can balance application objectives (e.g., accuracy in object detection and frames processing rate) with energy consumption. We address the problem of determining the set of configurations that can be used to self-adapt the system with a meta-heuristic search procedure that only needs a small number of empirical samples. The final set of configurations are selected using weighted gray relational analysis, and mapped to the operation modes of the self-adaptive application. We validate our approach on an AI-based application for pedestrian detection. Results show that our self-adaptive application can outperform non-adaptive baseline configurations by saving up to 81\% of energy while loosing only between 2% and 6% in accuracy.
Deductive Controller Synthesis for Probabilistic Hyperproperties
Jul 10, 2023Probabilistic hyperproperties specify quantitative relations between the probabilities of reaching different target sets of states from different initial sets of states. This class of behavioral properties is suitable for capturing important security, privacy, and system-level requirements. We propose a new approach to solve the controller synthesis problem for Markov decision processes (MDPs) and probabilistic hyperproperties. Our specification language builds on top of the logic HyperPCTL and enhances it with structural constraints over the synthesized controllers. Our approach starts from a family of controllers represented symbolically and defined over the same copy of an MDP. We then introduce an abstraction refinement strategy that can relate multiple computation trees and that we employ to prune the search space deductively. The experimental evaluation demonstrates that the proposed approach considerably outperforms HyperProb, a state-of-the-art SMT-based model checking tool for HyperPCTL. Moreover, our approach is the first one that is able to effectively combine probabilistic hyperproperties with additional intra-controller constraints (e.g. partial observability) as well as inter-controller constraints (e.g. agreements on a common action).
From English to Signal Temporal Logic
Sep 21, 2021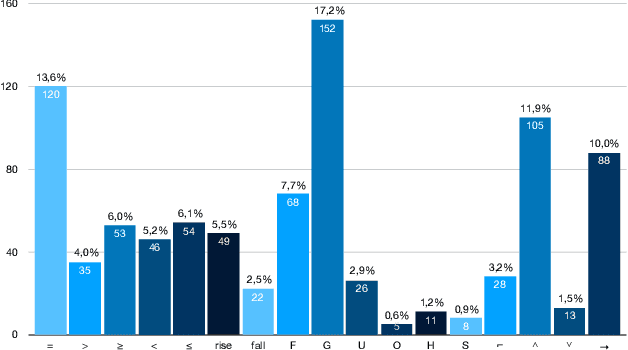

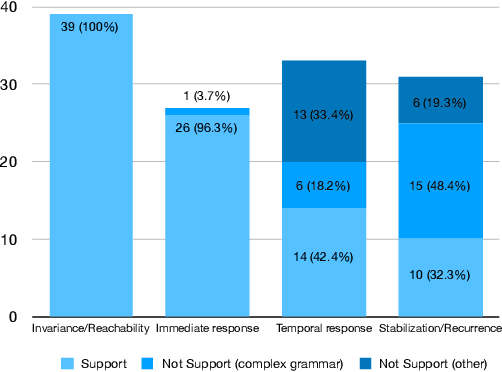

Formal methods provide very powerful tools and techniques for the design and analysis of complex systems. Their practical application remains however limited, due to the widely accepted belief that formal methods require extensive expertise and a steep learning curve. Writing correct formal specifications in form of logical formulas is still considered to be a difficult and error prone task. In this paper we propose DeepSTL, a tool and technique for the translation of informal requirements, given as free English sentences, into Signal Temporal Logic (STL), a formal specification language for cyber-physical systems, used both by academia and advanced research labs in industry. A major challenge to devise such a translator is the lack of publicly available informal requirements and formal specifications. We propose a two-step workflow to address this challenge. We first design a grammar-based generation technique of synthetic data, where each output is a random STL formula and its associated set of possible English translations. In the second step, we use a state-of-the-art transformer-based neural translation technique, to train an accurate attentional translator of English to STL. The experimental results show high translation quality for patterns of English requirements that have been well trained, making this workflow promising to be extended for processing more complex translation tasks.
Neural Network-based Control for Multi-Agent Systems from Spatio-Temporal Specifications
Apr 06, 2021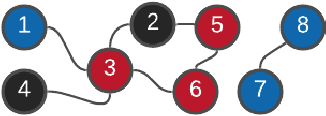
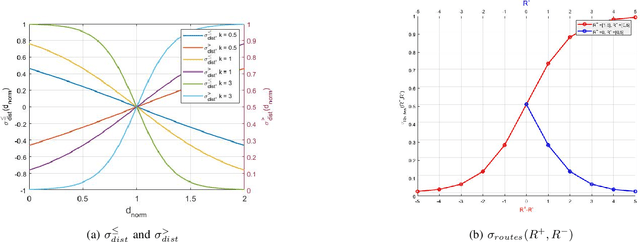
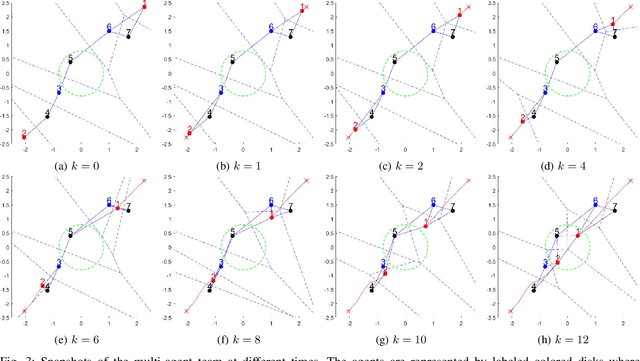
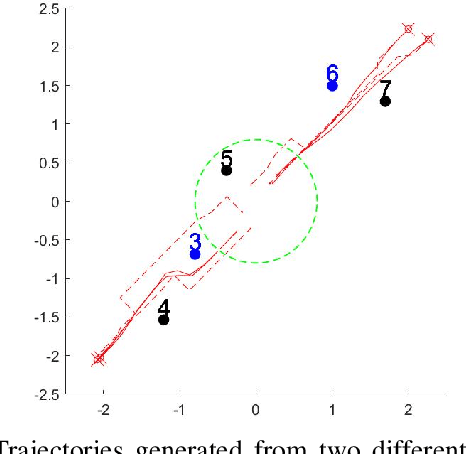
We propose a framework for solving control synthesis problems for multi-agent networked systems required to satisfy spatio-temporal specifications. We use Spatio-Temporal Reach and Escape Logic (STREL) as a specification language. For this logic, we define smooth quantitative semantics, which captures the degree of satisfaction of a formula by a multi-agent team. We use the novel quantitative semantics to map control synthesis problems with STREL specifications to optimization problems and propose a combination of heuristic and gradient-based methods to solve such problems. As this method might not meet the requirements of a real-time implementation, we develop a machine learning technique that uses the results of the off-line optimizations to train a neural network that gives the control inputs at current states. We illustrate the effectiveness of the proposed framework by applying it to a model of a robotic team required to satisfy a spatial-temporal specification under communication constraints.
CityPM: Predictive Monitoring with Logic-Calibrated Uncertainty for Smart Cities
Oct 31, 2020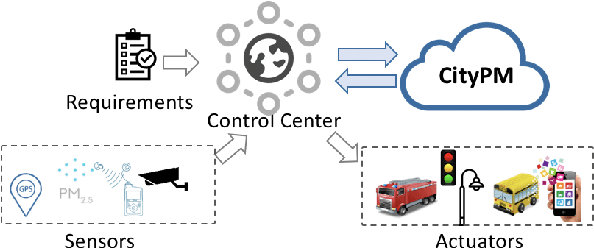
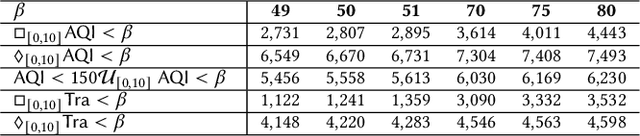
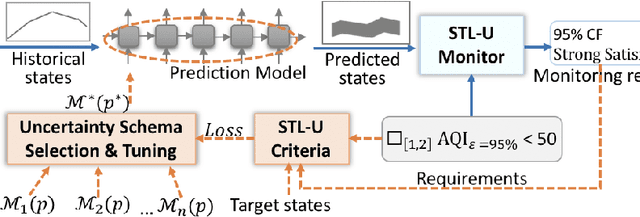
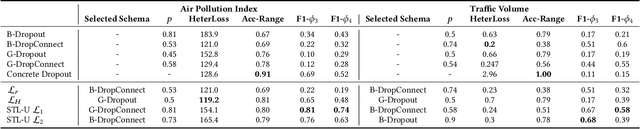
We present CityPM, a novel predictive monitoring system for smart cities, that continuously generates sequential predictions of future city states using Bayesian deep learning and monitors if the generated predictions satisfy city safety and performance requirements. We formally define a flowpipe signal to characterize prediction outputs of Bayesian deep learning models, and develop a new logic, named {Signal Temporal Logic with Uncertainty} (STL-U), for reasoning about the correctness of flowpipe signals. CityPM can monitor city requirements specified in STL-U such as "with 90% confidence level, the predicated air quality index in the next 10 hours should always be below 100". We also develop novel STL-U logic-based criteria to measure uncertainty for Bayesian deep learning. CityPM uses these logic-calibrated uncertainty measurements to select and tune the uncertainty estimation schema in deep learning models. We evaluate CityPM on three large-scale smart city case studies, including two real-world city datasets and one simulated city experiment. The results show that CityPM significantly improves the simulated city's safety and performance, and the use of STL-U logic-based criteria leads to improved uncertainty calibration in various Bayesian deep learning models.