 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDéjà View: Looping Transformers for Multi-View 3D Reconstruction
May 28, 2026Recent feed-forward 3D reconstruction transformers have scaled to over a billion parameters, following the broader trend of increasing model capacity in computer vision. Yet emerging evidence suggests that contiguous transformer layers often behave like repeated applications of similar operations, and multi-view reconstruction transformers refine their predictions progressively across decoder depth. We posit that model depth partially buys iteration, paid for inefficiently in unique parameters, and instead make that iteration explicit in architecture. Our model, DéjàView, applies a single looped transformer block recurrently to per-view features for K refinement steps. Trained once, it exposes K as an inference-time compute knob, matching or outperforming substantially larger feed-forward baselines across five reconstruction benchmarks spanning indoor, outdoor, object-centric, and driving scenes, while using a fraction of their parameters and comparable or lower compute. Importantly, the same looped block formulation outperforms an otherwise identical variant with independent per-step parameters under matched training data and compute, suggesting that explicit iteration is not merely a compute-efficient substitute for capacity but a stronger inductive bias for multi-view 3D reconstruction.
VGG-T$^3$: Offline Feed-Forward 3D Reconstruction at Scale
Feb 26, 2026We present a scalable 3D reconstruction model that addresses a critical limitation in offline feed-forward methods: their computational and memory requirements grow quadratically w.r.t. the number of input images. Our approach is built on the key insight that this bottleneck stems from the varying-length Key-Value (KV) space representation of scene geometry, which we distill into a fixed-size Multi-Layer Perceptron (MLP) via test-time training. VGG-T$^3$ (Visual Geometry Grounded Test Time Training) scales linearly w.r.t. the number of input views, similar to online models, and reconstructs a $1k$ image collection in just $54$ seconds, achieving a $11.6\times$ speed-up over baselines that rely on softmax attention. Since our method retains global scene aggregation capability, our point map reconstruction error outperforming other linear-time methods by large margins. Finally, we demonstrate visual localization capabilities of our model by querying the scene representation with unseen images.
Depth Completion as Parameter-Efficient Test-Time Adaptation
Feb 16, 2026We introduce CAPA, a parameter-efficient test-time optimization framework that adapts pre-trained 3D foundation models (FMs) for depth completion, using sparse geometric cues. Unlike prior methods that train task-specific encoders for auxiliary inputs, which often overfit and generalize poorly, CAPA freezes the FM backbone. Instead, it updates only a minimal set of parameters using Parameter-Efficient Fine-Tuning (e.g. LoRA or VPT), guided by gradients calculated directly from the sparse observations available at inference time. This approach effectively grounds the foundation model's geometric prior in the scene-specific measurements, correcting distortions and misplaced structures. For videos, CAPA introduces sequence-level parameter sharing, jointly adapting all frames to exploit temporal correlations, improve robustness, and enforce multi-frame consistency. CAPA is model-agnostic, compatible with any ViT-based FM, and achieves state-of-the-art results across diverse condition patterns on both indoor and outdoor datasets. Project page: research.nvidia.com/labs/dvl/projects/capa.
A Guide to Structureless Visual Localization
Apr 24, 2025Visual localization algorithms, i.e., methods that estimate the camera pose of a query image in a known scene, are core components of many applications, including self-driving cars and augmented / mixed reality systems. State-of-the-art visual localization algorithms are structure-based, i.e., they store a 3D model of the scene and use 2D-3D correspondences between the query image and 3D points in the model for camera pose estimation. While such approaches are highly accurate, they are also rather inflexible when it comes to adjusting the underlying 3D model after changes in the scene. Structureless localization approaches represent the scene as a database of images with known poses and thus offer a much more flexible representation that can be easily updated by adding or removing images. Although there is a large amount of literature on structure-based approaches, there is significantly less work on structureless methods. Hence, this paper is dedicated to providing the, to the best of our knowledge, first comprehensive discussion and comparison of structureless methods. Extensive experiments show that approaches that use a higher degree of classical geometric reasoning generally achieve higher pose accuracy. In particular, approaches based on classical absolute or semi-generalized relative pose estimation outperform very recent methods based on pose regression by a wide margin. Compared with state-of-the-art structure-based approaches, the flexibility of structureless methods comes at the cost of (slightly) lower pose accuracy, indicating an interesting direction for future work.
Light3R-SfM: Towards Feed-forward Structure-from-Motion
Jan 24, 2025



We present Light3R-SfM, a feed-forward, end-to-end learnable framework for efficient large-scale Structure-from-Motion (SfM) from unconstrained image collections. Unlike existing SfM solutions that rely on costly matching and global optimization to achieve accurate 3D reconstructions, Light3R-SfM addresses this limitation through a novel latent global alignment module. This module replaces traditional global optimization with a learnable attention mechanism, effectively capturing multi-view constraints across images for robust and precise camera pose estimation. Light3R-SfM constructs a sparse scene graph via retrieval-score-guided shortest path tree to dramatically reduce memory usage and computational overhead compared to the naive approach. Extensive experiments demonstrate that Light3R-SfM achieves competitive accuracy while significantly reducing runtime, making it ideal for 3D reconstruction tasks in real-world applications with a runtime constraint. This work pioneers a data-driven, feed-forward SfM approach, paving the way toward scalable, accurate, and efficient 3D reconstruction in the wild.
MATCHA:Towards Matching Anything
Jan 24, 2025



Establishing correspondences across images is a fundamental challenge in computer vision, underpinning tasks like Structure-from-Motion, image editing, and point tracking. Traditional methods are often specialized for specific correspondence types, geometric, semantic, or temporal, whereas humans naturally identify alignments across these domains. Inspired by this flexibility, we propose MATCHA, a unified feature model designed to ``rule them all'', establishing robust correspondences across diverse matching tasks. Building on insights that diffusion model features can encode multiple correspondence types, MATCHA augments this capacity by dynamically fusing high-level semantic and low-level geometric features through an attention-based module, creating expressive, versatile, and robust features. Additionally, MATCHA integrates object-level features from DINOv2 to further boost generalization, enabling a single feature capable of matching anything. Extensive experiments validate that MATCHA consistently surpasses state-of-the-art methods across geometric, semantic, and temporal matching tasks, setting a new foundation for a unified approach for the fundamental correspondence problem in computer vision. To the best of our knowledge, MATCHA is the first approach that is able to effectively tackle diverse matching tasks with a single unified feature.
DynOMo: Online Point Tracking by Dynamic Online Monocular Gaussian Reconstruction
Sep 03, 2024



Reconstructing scenes and tracking motion are two sides of the same coin. Tracking points allow for geometric reconstruction [14], while geometric reconstruction of (dynamic) scenes allows for 3D tracking of points over time [24, 39]. The latter was recently also exploited for 2D point tracking to overcome occlusion ambiguities by lifting tracking directly into 3D [38]. However, above approaches either require offline processing or multi-view camera setups both unrealistic for real-world applications like robot navigation or mixed reality. We target the challenge of online 2D and 3D point tracking from unposed monocular camera input introducing Dynamic Online Monocular Reconstruction (DynOMo). We leverage 3D Gaussian splatting to reconstruct dynamic scenes in an online fashion. Our approach extends 3D Gaussians to capture new content and object motions while estimating camera movements from a single RGB frame. DynOMo stands out by enabling emergence of point trajectories through robust image feature reconstruction and a novel similarity-enhanced regularization term, without requiring any correspondence-level supervision. It sets the first baseline for online point tracking with monocular unposed cameras, achieving performance on par with existing methods. We aim to inspire the community to advance online point tracking and reconstruction, expanding the applicability to diverse real-world scenarios.
The NeRFect Match: Exploring NeRF Features for Visual Localization
Mar 14, 2024



In this work, we propose the use of Neural Radiance Fields (NeRF) as a scene representation for visual localization. Recently, NeRF has been employed to enhance pose regression and scene coordinate regression models by augmenting the training database, providing auxiliary supervision through rendered images, or serving as an iterative refinement module. We extend its recognized advantages -- its ability to provide a compact scene representation with realistic appearances and accurate geometry -- by exploring the potential of NeRF's internal features in establishing precise 2D-3D matches for localization. To this end, we conduct a comprehensive examination of NeRF's implicit knowledge, acquired through view synthesis, for matching under various conditions. This includes exploring different matching network architectures, extracting encoder features at multiple layers, and varying training configurations. Significantly, we introduce NeRFMatch, an advanced 2D-3D matching function that capitalizes on the internal knowledge of NeRF learned via view synthesis. Our evaluation of NeRFMatch on standard localization benchmarks, within a structure-based pipeline, sets a new state-of-the-art for localization performance on Cambridge Landmarks.
Text2Pos: Text-to-Point-Cloud Cross-Modal Localization
Apr 05, 2022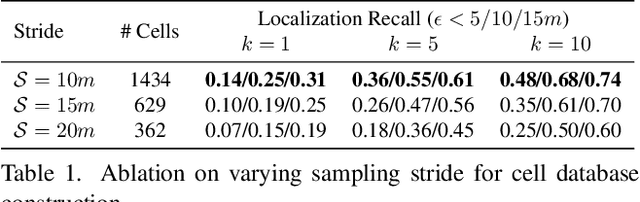
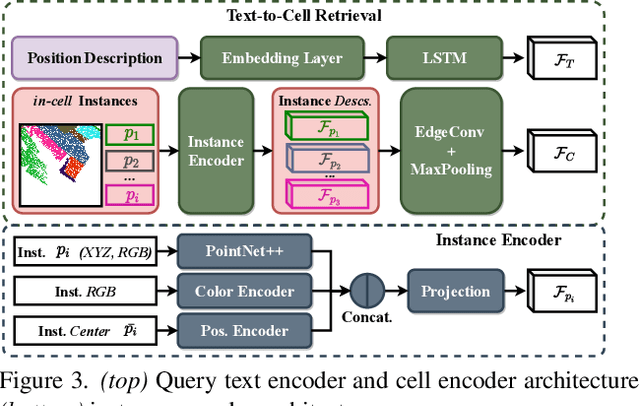
Natural language-based communication with mobile devices and home appliances is becoming increasingly popular and has the potential to become natural for communicating with mobile robots in the future. Towards this goal, we investigate cross-modal text-to-point-cloud localization that will allow us to specify, for example, a vehicle pick-up or goods delivery location. In particular, we propose Text2Pos, a cross-modal localization module that learns to align textual descriptions with localization cues in a coarse- to-fine manner. Given a point cloud of the environment, Text2Pos locates a position that is specified via a natural language-based description of the immediate surroundings. To train Text2Pos and study its performance, we construct KITTI360Pose, the first dataset for this task based on the recently introduced KITTI360 dataset. Our experiments show that we can localize 65% of textual queries within 15m distance to query locations for top-10 retrieved locations. This is a starting point that we hope will spark future developments towards language-based navigation.
Is Geometry Enough for Matching in Visual Localization?
Mar 24, 2022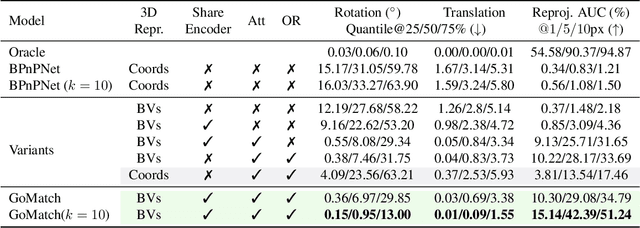
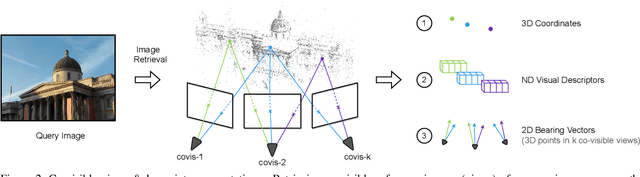
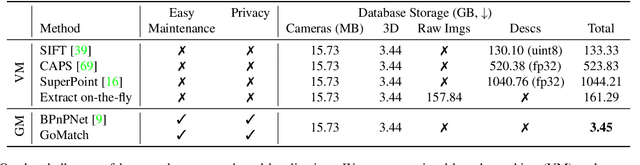
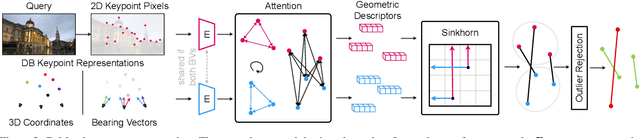
In this paper, we propose to go beyond the well-established approach to vision-based localization that relies on visual descriptor matching between a query image and a 3D point cloud. While matching keypoints via visual descriptors makes localization highly accurate, it has significant storage demands, raises privacy concerns and increases map maintenance complexity. To elegantly address those practical challenges for large-scale localization, we present GoMatch, an alternative to visual-based matching that solely relies on geometric information for matching image keypoints to maps, represented as sets of bearing vectors. Our novel bearing vectors representation of 3D points, significantly relieves the cross-domain challenge in geometric-based matching that prevented prior work to tackle localization in a realistic environment. With additional careful architecture design, GoMatch improves over prior geometric-based matching work with a reduction of ($10.67m, 95.7^{\circ}$) and ($1.43m$, $34.7^{\circ}$) in average median pose errors on Cambridge Landmarks and 7-Scenes, while requiring as little as $1.5/1.7\%$ of storage capacity in comparison to the best visual-based matching methods. This confirms its potential and feasibility for real-world localization and opens the door to future efforts in advancing city-scale visual localization methods that do not require storing visual descriptors.