 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Straightening for Latent Planning
Mar 12, 2026Learning good representations is essential for latent planning with world models. While pretrained visual encoders produce strong semantic visual features, they are not tailored to planning and contain information irrelevant -- or even detrimental -- to planning. Inspired by the perceptual straightening hypothesis in human visual processing, we introduce temporal straightening to improve representation learning for latent planning. Using a curvature regularizer that encourages locally straightened latent trajectories, we jointly learn an encoder and a predictor. We show that reducing curvature this way makes the Euclidean distance in latent space a better proxy for the geodesic distance and improves the conditioning of the planning objective. We demonstrate empirically that temporal straightening makes gradient-based planning more stable and yields significantly higher success rates across a suite of goal-reaching tasks.
Value-guided action planning with JEPA world models
Dec 28, 2025Building deep learning models that can reason about their environment requires capturing its underlying dynamics. Joint-Embedded Predictive Architectures (JEPA) provide a promising framework to model such dynamics by learning representations and predictors through a self-supervised prediction objective. However, their ability to support effective action planning remains limited. We propose an approach to enhance planning with JEPA world models by shaping their representation space so that the negative goal-conditioned value function for a reaching cost in a given environment is approximated by a distance (or quasi-distance) between state embeddings. We introduce a practical method to enforce this constraint during training and show that it leads to significantly improved planning performance compared to standard JEPA models on simple control tasks.
Closing the Train-Test Gap in World Models for Gradient-Based Planning
Dec 10, 2025



World models paired with model predictive control (MPC) can be trained offline on large-scale datasets of expert trajectories and enable generalization to a wide range of planning tasks at inference time. Compared to traditional MPC procedures, which rely on slow search algorithms or on iteratively solving optimization problems exactly, gradient-based planning offers a computationally efficient alternative. However, the performance of gradient-based planning has thus far lagged behind that of other approaches. In this paper, we propose improved methods for training world models that enable efficient gradient-based planning. We begin with the observation that although a world model is trained on a next-state prediction objective, it is used at test-time to instead estimate a sequence of actions. The goal of our work is to close this train-test gap. To that end, we propose train-time data synthesis techniques that enable significantly improved gradient-based planning with existing world models. At test time, our approach outperforms or matches the classical gradient-free cross-entropy method (CEM) across a variety of object manipulation and navigation tasks in 10% of the time budget.
Large-Scale Historical Watermark Recognition: dataset and a new consistency-based approach
Aug 27, 2019
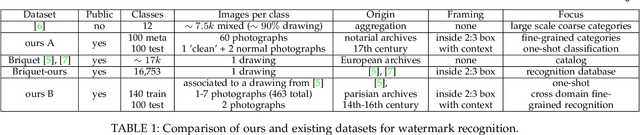

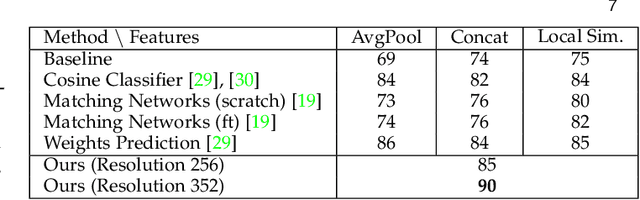
Historical watermark recognition is a highly practical, yet unsolved challenge for archivists and historians. With a large number of well-defined classes, cluttered and noisy samples, different types of representations, both subtle differences between classes and high intra-class variation, historical watermarks are also challenging for pattern recognition. In this paper, overcoming the difficulty of data collection, we present a large public dataset with more than 6k new photographs, allowing for the first time to tackle at scale the scenarios of practical interest for scholars: one-shot instance recognition and cross-domain one-shot instance recognition amongst more than 16k fine-grained classes. We demonstrate that this new dataset is large enough to train modern deep learning approaches, and show that standard methods can be improved considerably by using mid-level deep features. More precisely, we design both a matching score and a feature fine-tuning strategy based on filtering local matches using spatial consistency. This consistency-based approach provides important performance boost compared to strong baselines. Our model achieves 55% top-1 accuracy on our very challenging 16,753-class one-shot cross-domain recognition task, each class described by a single drawing from the classic Briquet catalog. In addition to watermark classification, we show our approach provides promising results on fine-grained sketch-based image retrieval.